又是考试考到了板子,看出是Kmp板子题后心态直接炸裂然后题意看错暴力打错。。。
就是知识点理解掌握的并不扎实就像exgcd一样课下自己推了一遍理解透了考试现推也能打但是理解不透,记得再熟也会打不出来尴尬。
一直认为Kmp简单而且理解透了回去在看全是细节和思想。并不容易,至少我自己想是想不出来这种优秀算法的。
这是一种依据性质的算法。
发现匹配字符串时人眼基本很快找出失配后从哪一位重新匹,那么说明它有一定 的性质。
在传统匹法中每次重新回归会浪费时间很多效率低的像我一样(就是不行)。
找性质:发现对于一个串在一个位置上失配的话并不一定要跳回起点所以(整个KMP的重点就在于当某一个字符与主串不匹配时,我们应该知道j指针要移动到哪? )
摘自课件:我们可以大概看出一点端倪,当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。
手玩一下就能发现,一个比较显然的性质,注意是j之前的最后k个字符,因为在j处失配我们把当前用来匹配的下面那个串挪动位置继续与上一个串匹配的话,就能用到之前我们和上面那个串匹配到的信息,会发现一般这种信息重用的算法都很强,比如CDQ分治,我们既然匹配到了J就说明j之前的完全匹配上了,那么跳位置的 时候就可以利用这一点,更新答案后我们无需重新从头匹配因为这个下面的串可能有一定的特点就是j之前的最后K个字符和最前面的K个字符一样,这样的性质非常强大,因为这说明我们把下面串的头挪动到当前j前面最后k个字符的头时,从这个位置开始又无形中匹配了一个小串的长度,这是因为既然这K个一样而j之前的又全匹那么把第一个小串挪过来就无形中又再次匹配有可能使答案更优而不重不漏。做到不重不漏的算法就既保证了正确性又能够优化时间。这是kmp的关键思想。 如果这没看懂别着急下面还有。
摘(,当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。 )
代码实现如何找这个位置:
摘 { ”好,接下来就是重点了,怎么求这个(这些)k呢?因为在P的每一个位置都可能发生不匹配,也就是说我们要计算每一个位置j对应的k,所以用一个数组next来保存,next[j] = k,表示当T[i] != P[j]时,j指针的下一个位置。 “; }
所以这里的next数组是关键类似于ac自动机中的fail指针,效果是类似的。
代码很短思想很强。
定义了两个非常强大的指针,k用来在前面的部分移动寻找对后边到J为止最大的贡献处(也就是寻找next,最长匹配);
j用来一直移动因为在跑程序时每一个j都可能失配,我们让j不断右移,根据j的位置来调整K的位置就可以;
初始化:next[0]=-1; 因为起点失配就没法了只能让下面那个串的起点右移,这时当前下串对应的原来位置就是-1了。
k=-1, j=0; 开始时j当然是起点了,而起点前面没有那q个字符的存在,k初始是-1表示当前前面那个串和后面的匹配长度为0;并为第一次匹配做准备,有点玄乎先看下面。
每次j只移动了一位,所以之前的前后小串匹配可以在新的p[++j]==p[++k]情况下使得匹配串串长长一位。想一下之前的某个位置这个串开始了,然后从某个后位置和整个的串头开始对上了这时候又多了一位当然就会使next[新的j]=next[j-1]+1; 这里再说一下初始化k=-1的问题,首先设为0想一下有什么后果后果就是j=k,那完了,设成0不对那么设成-1为什么是对的呢?从第二个字符也就是1位置来说(0已初始化next),它的最长匹配怎么求可能是多少呢?画两个块发现它失配的话肯定是跳回0位置无疑了。这时候又有些懵了,发现刚才那句话并没理解透:,当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。 注意这里两个k是同一个为什么呢?因为我们是把头移到了某个位置而使得j对应上了串中的位置k,那么正好就是前k个字符了。所以对于j :0->1这个位置k=-1 ->0所以前0个和后0个匹配啊,next[1]=0;这是在字符串正常读入第一位是0的情况下,要是读入1的话,就是跳到第K位而前k-1个和后K -1个同。 把k移过来了,那前面不就K-1个吗。
aaaaab 的情况下k=4,可以有重复因为跳过来还是可以继续匹配
对上了的情况我们已经考虑到了,那么没对上我们该怎么办???
我们之前提到过通过调整k来找到符合j的最大匹配->位置即next[j],那么之前都对上了现在有断点如何继续更新j的匹配长度呢?会发现其实我们把前部分和后部分去一一比对,其实就是在字符串匹配所以失配不就是又一个kmp吗,这是我们已经算出了next[k],因为k<j啊,所以此时失配前面一样可以用kmp,而是k=next[k]了,而这样是把前面的头换到某个位置所以整个前面部分这个串继续去匹配所以是正确的。


next[0]=-1; k=-1; j=0; while(j<p.length-1)//为什么到length-1,看一下下面的++j,所以到-2时可以求出next[ length-1 ,如果说读入字符串+1了,那么就是<length. { if(k==-1||p[j]==p[k]) next[++j]=++k; //也等于next[j-1]+1;但最好别那么写没准有问题注意只有算出next[j]来j才加加保证算出 else k=next[k]; } 代码1还未优化用于理解 代码1未优化用于理解
注意:代码一也得学会因为有些题符合Kmp的性质但并不是裸的kmp字符匹配有的题会用到代码1而不用代码2
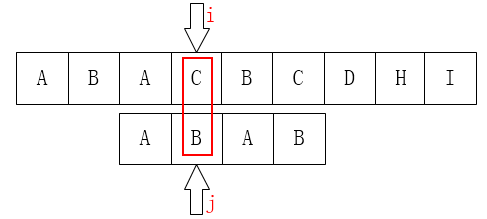
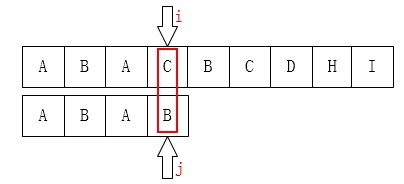
顺序放反了理解一下。。。
从右图失配到跳到左图,发现两个失配处字母还是一样,结果一样。所以这样浪费啊,但是直接pass ? no因为那个前面的b还可能有next.....
该一下代码关键在如果P[j]==P[next[j]] 时换一下就好。因为按顺序且一直这样做所以再找前面那个b的next还是不可能找到b,这就很优秀了,不重不漏。
int k=-1,j=0;
next[0]=-1;
while(j<length-1)
{
if(k==-1||p[j]==p[k])
{
if(p[++j]==p[++k]) //比较p[j]是否==p[next[j]],因为这时的next[j+1]=k+1,我们先比较是否相等再确定
{
next[j]=next[k];
}
else next[j]=k;
}
else k=next[k];
}
学知识学不透总是要还的。。。
迷迷糊糊的理解总有一天会忘了怎么回事一定要理解透彻。。。