从实际操作来看,数据治理一般分四个部分:
指标治理
规则流程
数仓架构模型规范(含数据安全)
数据质量
「HAO 治理」模型主要包含三部分,即数据接入模块、数据治理模块和数据服务模块。其中数据接入需要采集、汇聚等操作,从而构建异质的大数据。其次数据治理模块主要对数据进行一系列预处理过程,从而构建更加容易建模的数据。最后的数据服务模块则通过分析与加工,为外部提供各种新的能力。
1. 数据接入
一般而言,现实世界的数据主要分为结构化或非结构化,而这些图像、文本等各种数据都应该进行统一的接入与管理。对于数据源之上的接入模块,它主要完成不同类型的抽取汇聚任务配置,包括异构数据库之间数据传输汇聚,不同类型的文件数据和服务接口间相互传输。
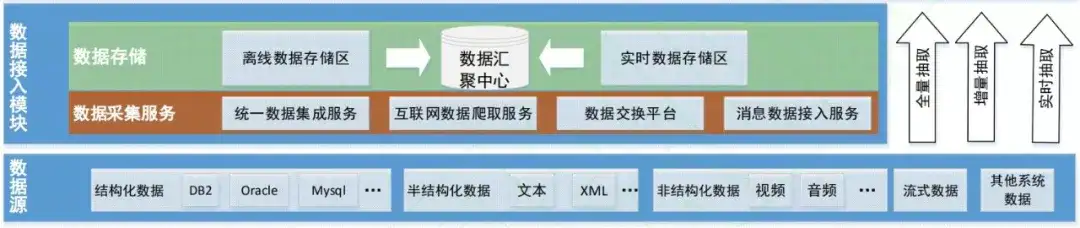
2. 数据治理
接入后的数据都是比较杂乱的,它本身带了一些冗余或缺失的信息。因此,数据治理模块主要包括对汇聚库中的数据进行数据清洗和数据规范,必要时进行主题划分和数据关联,然后进行数据集成。治理完成后的数据汇聚到数据共享中心中,并用于后续的建模。

其中我们比较熟悉的就是数据清洗,它会对数据进行审查和校验,从而过滤不合规数据、删除重复数据、纠正错误数据、完成格式转换。
3. 数据服务
数据治理的目标是提供一个可直接使用且方便管理的数据库,它最终还是要为各种模型提供学习基础。而模型,最终也是要提供各种智能服务,因此这一部分也应该得到规范的管理。
基于数据治理模块,数据服务模块最开始会根据数据共享中心构建知识图谱,它不仅向使用者提供模型管理、模型探索、数据探索等数据服务,同时还向专业人员提供挖掘分析、专家建模等智能数据服务。
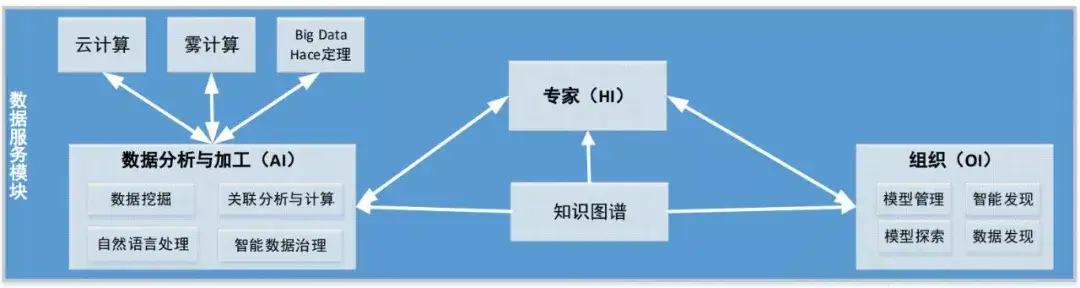
其中核心的知识图谱是由节点和边组成的巨型知识网络,节点代表实体、边代表实体之间的关系,每个实体 还通过键值对来描述实体的内在特性。领域专家们可以根据知识图谱中的实体和关系等核心数据进行建模,并进行高层次的数据挖掘分析和加工。
统一数据接入、治理和服务模块,就能构造出「HAO 治理」模型,它规定了最一般的处理流程。吴信东教授说:「只有通过多维感知,利用数据治理技术,将高质量的数据连接起来,才能进行知识的智能抽取,基于知识图谱、暴力挖掘对知识进行多维度分析推理,构建决策模型,完成从数字化、网络化到智能化的跃迁。」