SVM的概率输出(Platt scaling)
最近在研究基于样本的相似度度量问题,其中用到了分类器的概率输出(Platt scaling),大概了解了一下用法,总结的比较简单。
Platt scaling参考wiki的定义,Platt scaling,也叫Platt calibration,是一种将分类模型的输出变换为基于类别的概率分布的方法(可能翻译的不太准确,附上原文:In machine learning, Platt scaling or Platt calibration is a way of transforming the outputs of a classification model into a probability distribution over classes.)Platt scaling最初是用来解决SVM分类结果的概率输出(也可用于其他分类方法),采用逻辑斯蒂回归模型拟合分类器分数(classifier's socre)。
这里定义SVM的输出(非阈值化的):

其中

Platt基于Bayes准则,用后验概率 P(y=1|f) 替代类别条件密度 p(f|y),采用Sigmoid的参数化形式表达。

模型有两个参数A和B,采用最大似然估计训练,定义新的训练集合,其中ti为目标概率:
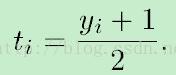
最小化训练数据的Negative Log Likelihood,目标函数为cross-entropy error function:
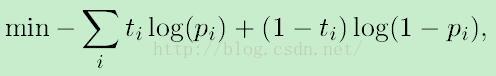
其中

Platt在论文中指出优化的两个问题:训练集的选择和避免过拟合的方法。
Platt Scaling的方法相当于创建新的训练集(SVM分类器输出Score和标签),基于这些新的数据进行训练,训练模型的输出就是分类器的概率输出。
相关参考:
Classifier calibration with Platt's scaling and isotonic regression
Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods 1999