
一、参考
二、样本数据(订单)
{
"source": "手机", // 订单来源
"category": [ // 订单中商品类型
"书籍",
],
"currency": "CNY", //货币单位
"customer_nickname": "testName", // 消费者昵称
"customer_gender": "MALE", // 消费者性别
"customer_id": 38, // 消费者ID
"customer_phone": "12345678910", // 消费者手机
"day_of_week": "Monday", // 星期
"email": "test@test.com", // 消费者邮箱
"manufacturer": [ // 制造商
"机械工业出版社"
],
"order_date": "2020-11-23T09:28:48+00:00", //订单日期
"order_id": 584677, //订单ID
"products": [
{
"base_price": 45.00, //定价(多件)
"discount_percentage": 17, //折扣(%)
"quantity": 1, //购买数量
"manufacturer": "机械工业出版社", //制造商
"tax_amount": 0, //税额
"product_id": 6283, //商品ID
"category": "书籍", //商品分类
"sku": "ZO0549605496", //商品sku码
"taxless_price": 37.35, //免税价格
"unit_discount_amount": 7.65, //折扣金额(单件)
"min_price": 20.50, //最低价格
"_id": "sold_product_584677_6283", //与订单有关的商品ID
"discount_amount": 7.65, //折扣金额(多件)
"created_on": "2016-12-26T09:28:48+00:00", //商品创建日期
"product_name": "TCP/IP 详解卷1:协议", //商品名称
"price": 37.35, //实际商品价格
"taxful_price": 37.35, //含税价格
"base_unit_price": 45.00 //定价(单件)
}
],
"sku": [
"ZO0549605496" // 商品sku码
],
"taxful_total_price": 37.35, //含税总价
"taxless_total_price": 37.35, //免税总价
"total_quantity": 1,
"total_unique_products": 1,
"type": "order",
"user": "thewind",
"geoip": {
"country_iso_code": "CN", //国家代码
"location": {
"lon": 121.4,
"lat": 31.2
},
"region_name": "上海", //省
"continent_name": "亚洲", //洲
"city_name": "上海" //市
}
}
三、查询基本使用
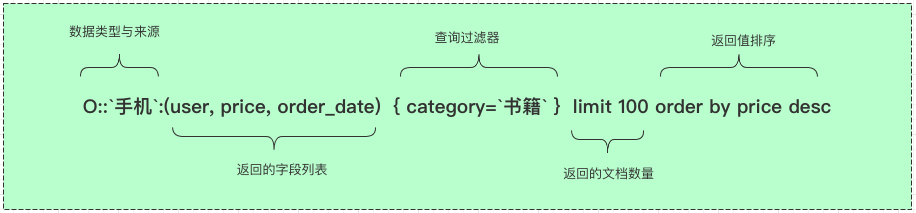
3.1 数据类型与来源
(1) 数据类型与来源是必填项,
(2) 来源可以使用正则匹配, 或者指定多个来源
示例:
# 正则匹配
O::re(`pc.*`):(user, price, order_date) { category=`书籍` } limit 100 order by price desc
# 多个来源
O::手机,pc:(user, price, order_date) { category=`书籍` } limit 100 order by price desc
3.2 查询过滤器
(1) 对于数值类型的字段,可以使用 >, <, =, != 等数值计算
(2) 对于字符串类型的字段,可以使用 =, match, re等函数
(3) 多个过滤器之间可以使用 &&, || 逻辑运算法
3.3 limit 说明
当前返回的最大数量为 5000条
3.4 order by 说明
(1) 当前 order by支持对于多个字段排序
(2) 多个排序字段需要使用相同的排序方式(desc, asc)
3.5 query 相关的函数
3.5.1 re
(1) 函数名 re
(2) 函数含义:regular expression,正则匹配
(3) 示例:
O::re("c.*"):(age){ age > 20 }
O::c1:(age, name){ age > 19 and name=re("go.*") }
3.5.2 match
(1) 函数名 match
(2) 函数含义:对于 text 字段,可以使用 match 查询
(3) 示例:
O::c1:(age, height) {name=match("golang")}
四、含有聚合的查询

4.1 指标函数
4.1.1 avg
(1) 函数名 avg
(2) 函数含义:求平均值
(3) 示例: O::c1:(avg(age)) group by name, 先按照 name 分组,再求每组中 age 的平均值
4.1.2 count/cardinality
(1) 函数名 cardinality
(2) 函数含义:求字段中唯一值的数量,相当于 sql 中 distinct 或者 unique 值的数目
(3) 示例: O::c1:(cardinality(student)) group by school, 先按照 school 分组,再求每组中的 student 去重
4.1.3 extended_stats
(1) 函数名 extended_stats
(2) 函数含义:同status,多了下面的4个指标值
sum_of_squares(平方和),
variance(方差),
std_deviation(标准偏差),
std_deviation_bounds(标准偏差界限)
(3) 示例: extended_stats(grade)
4.1.4 max
(1) 函数名 max
(2) 函数含义:求最大值
(3) 示例: max(grade), 求 grade 的最大值
4.1.5 min
(1) 函数名 min
(2) 函数含义:求最小值
(3) 示例: min(grade), 求 grade 的最小值
4.1.6 percentiles
(1) 函数名 percentiles
(2) 函数含义:求百分位分布
(3) 示例: percentiles(grade), 求 grade 的百分位分布列表
4.1.7 stats
(1) 函数名 stats
(2) 函数含义:计算状态值
(3) 示例: stats(grade), 求 grade 的各个状态值 (min, max, sum, count, avg)
4.1.8 sum
(1) 函数名 sum
(2) 函数含义:汇总计算
(3) 示例: sum(grade), 求 grade 的总值
4.1.9 median_absolute_deviation
(1) 函数名 median_absolute_deviation
(2) 函数含义:绝对中位差,可以反映数据的波动情况
(3) 示例: median_absolute_deviation(grade), 求 grade 的绝对中位差
4.2 未实现的指标函数
4.2.1 weighted avg
带有权重的平均值
4.2.2 geo_bounds
求一组经纬度的范围
4.2.3 geo_centroid
求一组经纬度的质心(密集点)
4.2.4 percentile_ranks
求一定范围内的百分位分布
4.2.5 scripted_metric
脚本自定义的函数
4.2.6 value_count
计算值用到的总的文档数量
4.3 groupsize
(1) 函数名 groupsize
(2) 函数含义:当涉及到对象数据的聚合时候,需要指定桶聚合的 size,默认size 为10
(3) 示例:
O::c1:(groupSize(age, 20), height){ age > 20 } group by age, height
4.4 tophits
(1) 函数名 tophits
(2) 函数含义:当聚合后,还需要返回原始数据的时候,需要提供 tophits 函数
(3) 示例:
O::c1:(tophits(age, height, name, size=30)){ age > 20 } group by age, height