笔记来源:源码学院
索引(Index)是帮助 MySQL 高效获取数据的数据结构。 常见的查询算法:顺序查找、二分查找、二叉排序树查找、哈希散列法、分块查找、平衡多路搜索树 B 树(B-tree)

索引可以用的查找算法
一、哈希算法
哈希算法(也叫散列), 就是把任意长度值(Key)通过散列算法变换成固定长度的key地址,通过这个地址进行访问的数据结构。
它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
这个映射函数叫做散列函数,存放记录的数组叫做散列表。


比如对于SQL语句:
select * from user where id = 7
很快就可以获得id=7的物理地址:
hash时间复杂度:O(1)
为什么MySQL索引没将hash算法作为主流?
# hash算法很适用于
select * from user where id = 7
# 但是对于以下情况,就力不从心了
select * from user where id < 7
Hash不支持范围查询和排序
二、二叉排序树
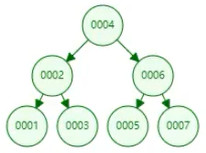
如果是【平衡二叉树】,查询id=7,则查询了 3 次
但如果平衡二叉树是以下这种情况【倾斜二叉树】:

如果查询id=7,则查询了 7 次【树的深度对查找次数有影响】
三、红黑树
解决二叉树的平衡的问题,但是mysql索引依然没有使用红黑树
问题:没有绝对解决,还是有倾斜现象

四、B+树
真实的数据存在于叶子节点;非叶子节点不存储真实的数据,只存储指引搜索方向的数据项。

当数据增加时,B+树会横向扩容,很难增加树的深度
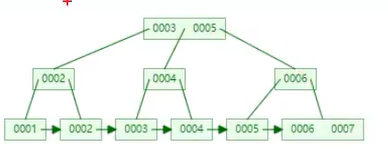
比如对于SQL语句:
select * from user where id = 7
查询到7,只需要查询3次即可
所以B+树非常适合做索引的底层数据结构【Hash算法有时也会做,因为时间复杂度低】
MySQL索引存储
数据库的索引会存储到磁盘
一、myisam引擎(非聚集索引方式)
- frm:创建表的语句文件
- MYD:数据库数据文件
- MYI:数据库索引文件
因为数据和索引是分开的,所以是非聚集的。
myisam不支持事务
比如以下图。我们对id和username建立了索引,则我们对id和username的索引都建立了对应的存储文件:

二、INNODB 引擎(聚集索引方式)
- frm:创建表的语句文件
- ibd:数据库数据+索引文件
INNODB查询速度不快
比如以下图。我们对id和username建立了索引
- 第一个IBD索引数据文件记录了id和数据
- 第二个IBD索引文件,如果对username也建立了索引,则记录的是username的索引和对应的id,为了节省空间,不存储数据
