Part.01 Webmagic介绍
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发
WebMagic项目代码分为核心和扩展两部分
- 核心部分(webmagic-core)是一个精简的、模块化的爬虫实现,而扩展部分则包括一些便利的、实用性的功能。WebMagic的架构设计参照了Scrapy,目标是尽量的模块化,并体现爬虫的功能特点。这部分提供非常简单、灵活的API,在基本不改变开发模式的情况下,编写一个爬虫
- 扩展部分(webmagic-extension)提供一些便捷的功能,例如注解模式编写爬虫等。同时内置了一些常用的组件,便于爬虫开发
Part.02 Webmagic设计原理
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。
WebMagic总体架构图如下:
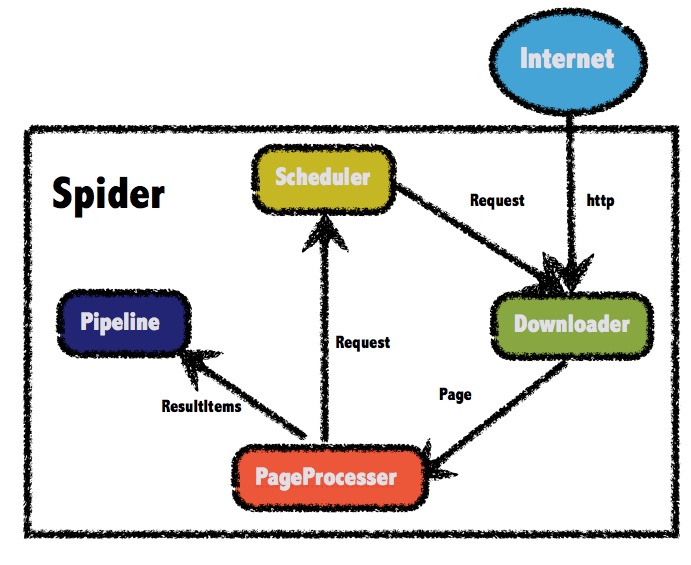
WebMagic的四个组件
- Downloader:Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
- PageProcessor:PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
- Scheduler:Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
- Pipeline:Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
用于数据流转的对象
- Request:Request是对URL地址的一层封装,一个Request对应一个URL地址。它是PageProcessor与Downloader交互的载体,也是PageProcessor控制Downloader唯一方式。除了URL本身外,它还包含一个Key-Value结构的字段extra。你可以在extra中保存一些特殊的属性,然后在其他地方读取,以完成不同的功能。例如附加上一个页面的一些信息等。
- Page:Page代表了从Downloader下载到的一个页面——可能是HTML,也可能是JSON或者其他文本格式的内容。Page是WebMagic抽取过程的核心对象,它提供一些方法可供抽取、结果保存等。
- ResultItems:ResultItems相当于一个Map,它保存PageProcessor处理的结果,供Pipeline使用。它的API与Map很类似,值得注意的是它有一个字段skip,若设置为true,则不应被Pipeline处理。
Part.03 Webmagic 实例(爬取 笔趣阁&bilibili的数据)
-
完整代码下载:<点击进入>
webmagic使用maven管理依赖,在项目中添加对应的依赖即可使用webmagic
<!-- web magic -->
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
WebMagic 使用slf4j-log4j12作为slf4j的实现.如果你自己定制了slf4j的实现,请在项目中去掉此依赖
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
核心代码
- BilibiliReptile.java
package com.reptile.bilibili;
import com.mysql.dao.BilibiliDao;
import com.mysql.entity.Bilibili;
import com.mysql.pipeline.MysqlPipelineBilibili;
import com.tool.SplitJson;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import java.sql.SQLException;
import static com.reptile.json.GetHttpInterface.GetHttpInterface;
public class BilibiliReptile implements PageProcessor{
//设置拼接的url变量
//爬取av号从1至1000000
private static int start =1;
private static int end =1000000;
//设置网站相关配置
//重试次数和抓取间隔
private Site site = Site.me().setRetryTimes(5).setSleepTime(0).setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36");
public synchronized void process(Page page) {
//视频标题
page.putField("title",page.getHtml().xpath("//h1[@class='video-title']/span/text()").get());
//如果title为空则跳过
if (page.getResultItems().get("title") == null) {
page.setSkip(true);
}
//标题图
page.putField("image",page.getHtml().xpath("/html/head/meta[10]").get());
//up
page.putField("up",page.getHtml().xpath("//div[@class='name']/a[1]/text()").get());
//简介
page.putField("info",page.getHtml().xpath("//div[@class='u-info']/div[2]/text()").get());
//分p
page.putField("part",page.getHtml().xpath("//*[@id="multi_page"]/div[1]/div/span/text()").get());
//时间戳
page.putField("date",page.getHtml().xpath("//div/time/text()").get());
}
public Site getSite() {
// TODO Auto-generated method stub
return site;
}
public static void main(String[] args) throws SQLException {
int id = 1;
BilibiliDao bilidao = new BilibiliDao();
Bilibili bilibili = new Bilibili();
SplitJson sj = new SplitJson();
while (start<end) {
Spider.create(new BilibiliReptile()).addUrl("https://www.bilibili.com/video/av" + start + "/")
//输出到控制台
.addPipeline(new ConsolePipeline())
//传输到数据库
// .addPipeline(new MysqlPipelineBilibili())
//开启5个线程抓取
.thread(5)
//启动爬虫
.run();
String str = GetHttpInterface("https://api.bilibili.com/x/web-interface/archive/stat?aid=" + start);
if((sj.splitCode(str)).equals("0"))
{
bilibili.setId(id);
bilibili.setPlay(sj.splitView(str));
bilibili.setBarrage(sj.splitDanmaku(str));
bilidao.addData(bilibili);
System.out.println(str);
System.out.println("view:" + sj.splitView(str));
System.out.println("danmuke:" + sj.splitView(str));
id++;
}
start++;
}
}
}
- BiQuGeReptile.java
package com.reptile.biquge;
import com.mysql.pipeline.MysqlPipelineBiQuGe;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
public class BiQuGeReptile implements PageProcessor {
//regex of URL:http://www.xbiquge.la/
public static final String FIRST_URL = "http://www\.xbiquge\.la/\w+";
public static final String HELP_URL = "/\d+/\d+/";
public static final String TARGET_URL = "/\d+/\d+/\d+\.html/";
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);
public Site getSite() {
// TODO Auto-generated method stub
return site;
}
public void process(Page page) {
if(page.getUrl().regex(FIRST_URL).match()){
List<String> urls = page.getHtml().links().regex(HELP_URL).all();
page.addTargetRequests(urls);
//标题
page.putField("title",page.getHtml().xpath("//div[@id='info']/h1/text()").get());
//如果title为空则跳过
if (page.getResultItems().get("title") == null) {
page.setSkip(true);
}
//作者
page.putField("author",page.getHtml().xpath("//div[@id='info']/p/text()").get());
//简介
page.putField("info",page.getHtml().xpath("//div[@id='intro']/p[2]/text()").get());
//首图url
page.putField("image",page.getHtml().xpath("//div[@id='fmimg']/img").get());
//下一深度的网页爬取章节和内容
if(page.getUrl().regex(HELP_URL).match()){
List<String> links = page.getHtml().links().regex(TARGET_URL).all();
page.addTargetRequests(links);
//章节
page.putField("chapter", page.getHtml().xpath("//div[@class='bookname']/h1/text()").get());
//内容
page.putField("content", page.getHtml().xpath("//div[@id='content']/text()").get());
}
}
}
public static void main(String[] args){
Spider.create(new BiQuGeReptile()).addUrl("http://www.xbiquge.la/xiaoshuodaquan/")
//输出到控制台
.addPipeline(new ConsolePipeline())
//传输到数据库
// .addPipeline(new MysqlPipelineBiQuGe())
//开启5个线程抓取
.thread(5)
//启动爬虫
.run();
}
}
注意事项
在0.7.3版本中,爬取只支持TLS1.2的https站点的时候会报错:
javax.net.ssl.SSLException: Received fatal alert: protocol_version
解决办法:https://github.com/code4craft/webmagic/issues/701
Part.04 Webmagic 拓展
URL 去重
Scheduler是WebMagic中进行 URL 管理的组件。一般来说,Scheduler包括两个作用:
对待抓取的URL队列进行管理。
对已抓取的URL进行去重。
Scheduler的内部实现进行了重构,去重部分被单独抽象成了一个接口:DuplicateRemover,从而可以为同一个Scheduler选择不同的去重方式,以适应不同的需要,目前提供了三种去重方式。
HashSet
使用 java 中 HashSet 不能重复的特点去重。占用内存大,性能低
Redis 去重
使用 Redis 的 set 进行去重。优点是速度快,而且不会占用爬虫服务器的资源。可以处理更大数据量的数据爬取;缺点是需要 redis 服务器,增加开发和使用成本
布隆过滤器(BloomFilter)
优点是占用内存比 HashSet 小的多,也适合大数据量的去重操作。
布隆过滤器的使用实例:
@Scheduled(initialDelay = 1000, fixedDelay = 60 * 1000 * 60 * 12)
public void start() {
Spider.create(new BdProcessor())
.addUrl(URL)
.thread(10)
// 设置布隆过滤器去重操作(默认使用HashSet来进行去重,占用内存较大;使用BloomFilter来进行去重,占用内存较小,但是可能漏抓页面)
.setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(10000000)))
.addPipeline(dbPipeline)
.run();
}
网页去重
指纹码对比
最常见的去重方案是生成文档的指纹门。例如对一篇文章进行 MD5 加密生成一个字符串,我们可以认为这是文章的指纹码,再和其他的文章指纹码对比,一致则说明文章重复。
但是这种方式是完全一致则是重复的,如果文章只是多了几个标点符号,那仍旧被认为是重复的,这种方式并不合理。
BloomFilter
这种方式就是我们之前对 url 进行去重的方式,使用在这里的话,也是对文章进行计算得到一个数,再进行对比,缺点和方法 1 是一样的,如果只有一点点不一样,也会认为不重复,这种方式不合理。
KMP 算法
KMP 算法是一种改进的字符串匹配算法。KMP 算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。能够找到两个文章有哪些是一-样的,哪些不一样
这种方式能够解决前面两个方式的“只要一点不一样就是不重复”的问题。但是它的时空复杂度太高了,不适合大数据量的重复比对
SimHash (主要)
Google 的 simhash 算法产生的签名,可以满足上述要求。这个算法并不深奥,比较容易理解。这种算法也是目前 Google 搜索引擎所目前所使用的网页去重算法
分词,把需要判断文本分词形成这个文章的特征单词。
hash,通过 hash 算法把每个词变成 hash 值,比如“美国”通过 hash 算法计算为 100101,“51 区”通过 hash 算法计算为 101011。这样我们的字符串就变成了一串串数字。
加权,通过 2 步骤的 hash 生成结果,需要按照单词的权重形成加权数字串,。“美国”的 hash 值为“100101”,通过加权计算为“4-4-44-44”。“51 区”计算为‘“5-55-555”。
合并,把上面各个单词算出来的序列值累加,变成只有一一个序列串。。“美国”的“4-4-44-44”,“51 区”的“5-55-555”。
代理的使用
有些网站不允许爬虫进行数据爬取,因为会加大服务器的压力。其中一种最有效的方式是通过 ip+时间进行鉴别,因为正常人不可能短时间开启太多的页面,发起太多的请求。
我们使用的 WebMagic 可以很方便的设置爬取数据的时间(参考第二天的的 3.1. 爬虫的配置、启动和终止)。但是这样会大大降低我们 J 爬取数据的效率,如果不小心 ip 被禁了,会让我们无法爬去数据,那么我们就有必要使用代理服务器来爬取数据。
代理 L(英语:Proxy),也称网络代理,是一-种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。
提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(英文:Proxy. Server)。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源。
我们就需要知道代理服务器在哪里(ip 和端口号)才可以使用。网上有很多代理服务器的提供商,但是大多是免费的不好用,付费的还行。推荐个免费的服务网站:
-
米扑代理:<点击进入>
配置代理
WebMagic的代理API ProxyProvider。因为相对于 Site 的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。
- 设置代理:HttpClientDownloader.setProxyProvider(ProxyProvider proxyProvider)
ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
代理示例:
设置单一的普通HTTP代理为101.101.101.101的8888端口,并设置密码为"username","password"
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(new Proxy("101.101.101.101",8888,"username","password")));
spider.setDownloader(httpClientDownloader);
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
httpClientDownloader.setProxyProvider(SimpleProxyProvider.from(
new Proxy("101.101.101.101",8888)
,new Proxy("102.102.102.102",8888)));
Part.05 总结
-
关于Webmagic使用说明的总结
- Webmagic属于可快速上手的简易爬虫框架,在阅读官方文档后可快速上手开发,主要难点在于对于xpath(会正则的同学会很快就上手)的学习以及对于部分网站需要进行的cookie验证、代理以及登陆验证时有一定难度,对于部分动态渲染的前端页面可通过Chrome内核内嵌代码渲染的方式解决
Part.06 参考文献
PS:确实觉得写的很好,转给大家分享,文中提到的一些操作自己打算日后试试