文章来源:http://www.cnblogs.com/huxi2b/p/4583249.html
-----------------------------------------------------------------------------------------
在Kafak中国社区的qq群中,这个问题被提及的比例是相当高的,这也是Kafka用户最常碰到的问题之一。本文结合Kafka源码试图对该问题相关的因素进行探讨。希望对大家有所帮助。
怎么确定分区数?
“我应该选择几个分区?”——如果你在Kafka中国社区的群里,这样的问题你会经常碰到的。不过有些遗憾的是,我们似乎并没有很权威的答案能够解答这样的问题。其实这也不奇怪,毕竟这样的问题通常都是没有固定答案的。Kafka官网上标榜自己是"high-throughput distributed messaging system",即一个高吞吐量的分布式消息引擎。那么怎么达到高吞吐量呢?Kafka在底层摒弃了Java堆缓存机制,采用了操作系统级别的页缓存,同时将随机写操作改为顺序写,再结合Zero-Copy的特性极大地改善了IO性能。但是,这只是一个方面,毕竟单机优化的能力是有上限的。如何通过水平扩展甚至是线性扩展来进一步提升吞吐量呢? Kafka就是使用了分区(partition),通过将topic的消息打散到多个分区并分布保存在不同的broker上实现了消息处理(不管是producer还是consumer)的高吞吐量。
Kafka的生产者和消费者都可以多线程地并行操作,而每个线程处理的是一个分区的数据。因此分区实际上是调优Kafka并行度的最小单元。对于producer而言,它实际上是用多个线程并发地向不同分区所在的broker发起Socket连接同时给这些分区发送消息;而consumer呢,同一个消费组内的所有consumer线程都被指定topic的某一个分区进行消费(具体如何确定consumer线程数目我们后面会详细说明)。所以说,如果一个topic分区越多,理论上整个集群所能达到的吞吐量就越大。
但分区是否越多越好呢?显然也不是,因为每个分区都有自己的开销:
一、客户端/服务器端需要使用的内存就越多
先说说客户端的情况。Kafka 0.8.2之后推出了Java版的全新的producer,这个producer有个参数batch.size,默认是16KB。它会为每个分区缓存消息,一旦满了就打包将消息批量发出。看上去这是个能够提升性能的设计。不过很显然,因为这个参数是分区级别的,如果分区数越多,这部分缓存所需的内存占用也会更多。假设你有10000个分区,按照默认设置,这部分缓存需要占用约157MB的内存。而consumer端呢?我们抛开获取数据所需的内存不说,只说线程的开销。如果还是假设有10000个分区,同时consumer线程数要匹配分区数(大部分情况下是最佳的消费吞吐量配置)的话,那么在consumer client就要创建10000个线程,也需要创建大约10000个Socket去获取分区数据。这里面的线程切换的开销本身已经不容小觑了。
服务器端的开销也不小,如果阅读Kafka源码的话可以发现,服务器端的很多组件都在内存中维护了分区级别的缓存,比如controller,FetcherManager等,因此分区数越多,这种缓存的成本越久越大。
二、文件句柄的开销
每个分区在底层文件系统都有属于自己的一个目录。该目录下通常会有两个文件: base_offset.log和base_offset.index。Kafak的controller和ReplicaManager会为每个broker都保存这两个文件句柄(file handler)。很明显,如果分区数越多,所需要保持打开状态的文件句柄数也就越多,最终可能会突破你的ulimit -n的限制。
三、降低高可用性
Kafka通过副本(replica)机制来保证高可用。具体做法就是为每个分区保存若干个副本(replica_factor指定副本数)。每个副本保存在不同的broker上。期中的一个副本充当leader 副本,负责处理producer和consumer请求。其他副本充当follower角色,由Kafka controller负责保证与leader的同步。如果leader所在的broker挂掉了,contorller会检测到然后在zookeeper的帮助下重选出新的leader——这中间会有短暂的不可用时间窗口,虽然大部分情况下可能只是几毫秒级别。但如果你有10000个分区,10个broker,也就是说平均每个broker上有1000个分区。此时这个broker挂掉了,那么zookeeper和controller需要立即对这1000个分区进行leader选举。比起很少的分区leader选举而言,这必然要花更长的时间,并且通常不是线性累加的。如果这个broker还同时是controller情况就更糟了。
说了这么多“废话”,很多人肯定已经不耐烦了。那你说到底要怎么确定分区数呢?答案就是:视情况而定。基本上你还是需要通过一系列实验和测试来确定。当然测试的依据应该是吞吐量。虽然LinkedIn这篇文章做了Kafka的基准测试,但它的结果其实对你意义不大,因为不同的硬件、软件、负载情况测试出来的结果必然不一样。我经常碰到的问题类似于,官网说每秒能到10MB,为什么我的producer每秒才1MB? —— 且不说硬件条件,最后发现他使用的消息体有1KB,而官网的基准测试是用100B测出来的,因此根本没有可比性。不过你依然可以遵循一定的步骤来尝试确定分区数:创建一个只有1个分区的topic,然后测试这个topic的producer吞吐量和consumer吞吐量。假设它们的值分别是Tp和Tc,单位可以是MB/s。然后假设总的目标吞吐量是Tt,那么分区数 = Tt / max(Tp, Tc)
Tp表示producer的吞吐量。测试producer通常是很容易的,因为它的逻辑非常简单,就是直接发送消息到Kafka就好了。Tc表示consumer的吞吐量。测试Tc通常与应用的关系更大, 因为Tc的值取决于你拿到消息之后执行什么操作,因此Tc的测试通常也要麻烦一些。
另外,Kafka并不能真正地做到线性扩展(其实任何系统都不能),所以你在规划你的分区数的时候最好多规划一下,这样未来扩展时候也更加方便。
消息-分区的分配
默认情况下,Kafka根据传递消息的key来进行分区的分配,即hash(key) % numPartitions,如下图所示:
def partition(key: Any, numPartitions: Int): Int = {
Utils.abs(key.hashCode) % numPartitions
}
这就保证了相同key的消息一定会被路由到相同的分区。如果你没有指定key,那么Kafka是如何确定这条消息去往哪个分区的呢?

if(key == null) { // 如果没有指定key
val id = sendPartitionPerTopicCache.get(topic) // 先看看Kafka有没有缓存的现成的分区Id
id match {
case Some(partitionId) =>
partitionId // 如果有的话直接使用这个分区Id就好了
case None => // 如果没有的话,
val availablePartitions = topicPartitionList.filter(_.leaderBrokerIdOpt.isDefined) //找出所有可用分区的leader所在的broker
if (availablePartitions.isEmpty)
throw new LeaderNotAvailableException("No leader for any partition in topic " + topic)
val index = Utils.abs(Random.nextInt) % availablePartitions.size // 从中随机挑一个
val partitionId = availablePartitions(index).partitionId
sendPartitionPerTopicCache.put(topic, partitionId) // 更新缓存以备下一次直接使用
partitionId
}
}
可以看出,Kafka几乎就是随机找一个分区发送无key的消息,然后把这个分区号加入到缓存中以备后面直接使用——当然了,Kafka本身也会清空该缓存(默认每10分钟或每次请求topic元数据时)
如何设定consumer线程数
我个人的观点,如果你的分区数是N,那么最好线程数也保持为N,这样通常能够达到最大的吞吐量。超过N的配置只是浪费系统资源,因为多出的线程不会被分配到任何分区。让我们来看看具体Kafka是如何分配的。
topic下的一个分区只能被同一个consumer group下的一个consumer线程来消费,但反之并不成立,即一个consumer线程可以消费多个分区的数据,比如Kafka提供的ConsoleConsumer,默认就只是一个线程来消费所有分区的数据。——其实ConsoleConsumer可以使用通配符的功能实现同时消费多个topic数据,但这和本文无关。
再讨论分配策略之前,先说说KafkaStream——它是consumer的关键类,提供了遍历方法用于consumer程序调用实现数据的消费。其底层维护了一个阻塞队列,所以在没有新消息到来时,consumer是处于阻塞状态的,表现出来的状态就是consumer程序一直在等待新消息的到来。——你当然可以配置成带超时的consumer,具体参看参数consumer.timeout.ms的用法。
下面说说Kafka提供的两种分配策略: range和roundrobin,由参数partition.assignment.strategy指定,默认是range策略。本文只讨论range策略。所谓的range其实就是按照阶段平均分配。举个例子就明白了,假设你有10个分区,P0 ~ P9,consumer线程数是3, C0 ~ C2,那么每个线程都分配哪些分区呢?
C0 消费分区 0, 1, 2, 3
C1 消费分区 4, 5, 6
C2 消费分区 7, 8, 9
具体算法就是:
val nPartsPerConsumer = curPartitions.size / curConsumers.size // 每个consumer至少保证消费的分区数
val nConsumersWithExtraPart = curPartitions.size % curConsumers.size // 还剩下多少个分区需要单独分配给开头的线程们
...
for (consumerThreadId <- consumerThreadIdSet) { // 对于每一个consumer线程
val myConsumerPosition = curConsumers.indexOf(consumerThreadId) //算出该线程在所有线程中的位置,介于[0, n-1]
assert(myConsumerPosition >= 0)
// startPart 就是这个线程要消费的起始分区数
val startPart = nPartsPerConsumer * myConsumerPosition + myConsumerPosition.min(nConsumersWithExtraPart)
// nParts 就是这个线程总共要消费多少个分区
val nParts = nPartsPerConsumer + (if (myConsumerPosition + 1 > nConsumersWithExtraPart) 0 else 1)
...
}
针对于这个例子,nPartsPerConsumer就是10/3=3,nConsumersWithExtraPart为10%3=1,说明每个线程至少保证3个分区,还剩下1个分区需要单独分配给开头的若干个线程。这就是为什么C0消费4个分区,后面的2个线程每个消费3个分区,具体过程详见下面的Debug截图信息:
ctx.myTopicThreadIds
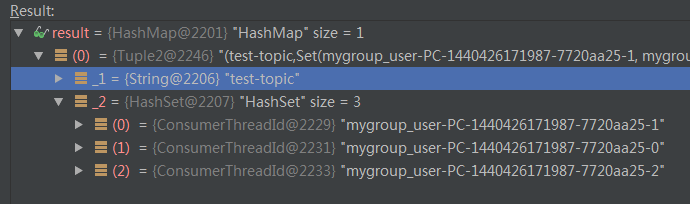


nPartsPerConsumer = 10 / 3 = 3
nConsumersWithExtraPart = 10 % 3 = 1
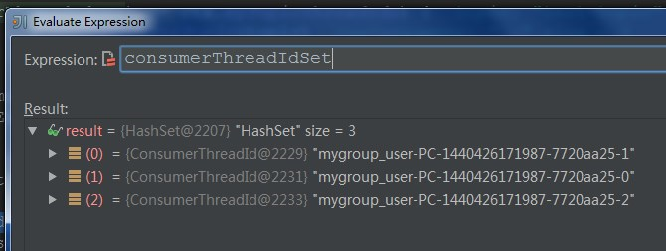

第一次:
myConsumerPosition = 1
startPart = 1 * 3 + min(1, 1) = 4 ---也就是从分区4开始读
nParts = 3 + (if (1 + 1 > 1) 0 else 1) = 3 读取3个分区, 即4,5,6
第二次:
myConsumerPosition = 0
startPart = 3 * 0 + min(1, 0) =0 --- 从分区0开始读
nParts = 3 + (if (0 + 1 > 1) 0 else 1) = 4 读取4个分区,即0,1,2,3
第三次:
myConsumerPosition = 2
startPart = 3 * 2 + min(2, 1) = 7 --- 从分区7开始读
nParts = 3 + if (2 + 1 > 1) 0 else 1) = 3 读取3个分区,即7, 8, 9
至此10个分区都已经分配完毕

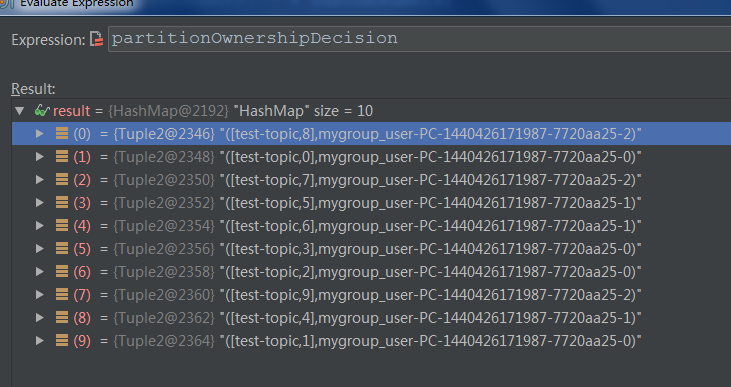
说到这里,经常有个需求就是我想让某个consumer线程消费指定的分区而不消费其他的分区。坦率来说,目前Kafka并没有提供自定义分配策略。做到这点很难,但仔细想一想,也许我们期望Kafka做的事情太多了,毕竟它只是个消息引擎,在Kafka中加入消息消费的逻辑也许并不是Kafka该做的事情。

self.consumer = KafkaConsumer((topic, int(partition_id)),
group_id=gid,
bootstrap_servers=[bs_server]
)