一、准备
1.1 先搭建好hadoop集群,参考https://www.cnblogs.com/the-roc/p/12362926.html
1.2 配置好 Java 1.8环境(hadoop集群搭建时就配置过)
1.3 准备好和hadoop版本一样的jar包
scala-2.13.0.tgz
spark-2.4.3-bin-hadoop2.7 .tgz
链接:https://pan.baidu.com/s/1WaohSAwWaOhWURthWx8KHg
提取码:hkd6
1.4 创建3台虚拟机,且配置好网络,建立好互信。
由于电脑配置问题,这里我只做了两台虚拟机进行实验
主 hadp01
从 hadp06
1.5配置免密
ssh-keygen #生成密钥对
ssh-copy-id hadp01 #将公钥拷贝给本机
ssh-copy-id hadp06 #将公钥拷贝给其他机
二、具体流程实现
2.1 用XShell操作上传jar包
cd /opt/install
rz
2.2 解压
tar -zxvf scala-2.13.1.tgz
tar -zxvf spark-2.4.4-bin-hadoop2.7.tgz
移动到 /opt/software 目录 mv scala-2.13.1 /opt/software
mv spark-2.4.4-bin-hadoop2.7 /opt/software
2.3 配置环境变量
vi /etc/profile
SCALA_HOME=/opt/software/scala-2.13.1
SPARK_HOME=/opt/software/spark-2.4.4-bin-hadoop2.7
PATH一行直接加 :$SPARK_HOME/bin:$PATH:$SCALA_HOME/bin
2.4 验证安装

2.5 配置spark-env.sh和slaves
cd /opt/software/spark-2.4.4-bin-hadoop2.7/conf
将 slaves.template spark-env.sh.template .template去掉
mv spark-env.sh.template spark-env.sh
mv slaves.template slaves
vim spark-env.sh
添加
export JAVA_HOME=/opt/software/jdk1.8
export SCALA_HOME=/opt/software/scala-2.13.1
export HADOOP_HOME=/opt/software/hadoop-2.7.7
export HADOOP_CONF_DIR=/opt/software/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_HOST=hadp01 主机名
export SPARK_WORKER_MEMORY=1g 虚拟机内存
export SPARK_WORKER_CORES=1 虚拟机核数
export SPARK_HOME=/opt/software/spark-2.4.4-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/opt/software/hadoop-2.7.7/bin/hadoop classpath)
vim slaves
将localhost改为 主从主机名
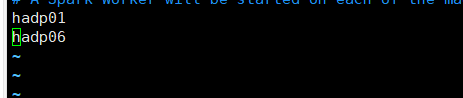
2.6 启动hadoop集群
start-all.sh
再在主节点启动spark
cd /opt/software/spark-2.4.4-bin-hadoop2.7
sbin/start-all.sh
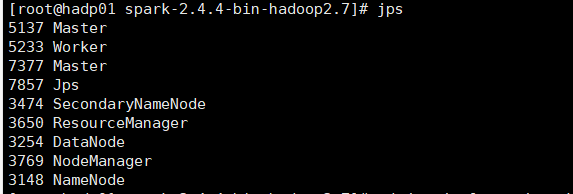
主:
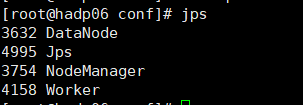
从:
2.7打开浏览器输入192.168.xx.xx:8080 查看
