一,准备
1.1导入相关jar包
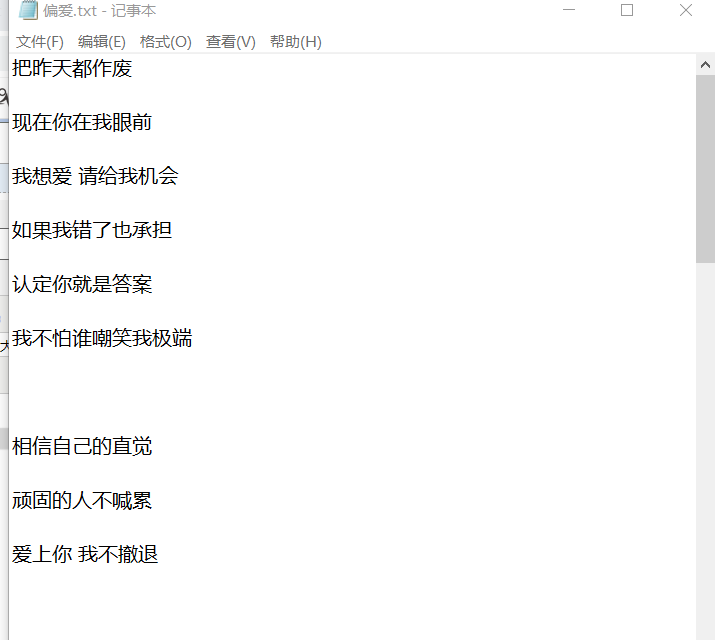
1.2准备数据源
我选了一首歌
二、相关代码
2.1 Map类
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ private static List<String> bill=new ArrayList<>(); //初始化块 只会执行一次 static{ System.out.println("我是初始化块 我一定会执行..."); bill.add("。"); bill.add(","); bill.add("?"); } @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { String line= value.toString(); char[] cs = line.toCharArray(); for(char c:cs) { if(!bill.contains(c+"")) { context.write(new Text(c+""), new IntWritable(1)); } } }
2.2 Reduce类
public class WordCountReducer extends Reducer<Text,IntWritable, Text,IntWritable> { //Reduce获取数据的时候 当前我们Mapper类生成的临时文件 中的所有的key会做一个合并处理 //Reduce获取的数据应该Mapper类执行后的结果 //把会结果自动合并 把KEY值会自动合并 把VALUE放到一个List集合中 //明 1 //明 1 //明 1 //明 1 //明 [1,1,1,1] 预处理 Reduce获取结果的时候 数据已经被预处理过了 // @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum=0; for(IntWritable value:values) { sum+=value.get(); } context.write(key,new IntWritable(sum)); } }
2.3 job类
public static void main(String[] args) { Configuration conf=new Configuration(); conf.set("fs.defaultFS","hdfs://192.168.1.63:9000"); try { Job job = Job.getInstance(conf); //要给当前的任务取一个名称 job.setJarByClass(WordCountDriver.class); //我当前的任务的Mapper类是谁 job.setMapperClass(WordCountMapper.class); //我们Mapper任务输出的文件的Key值类型 job.setMapOutputKeyClass(Text.class); //我们Mapper任务输出的文件的Value值类型 job.setMapOutputValueClass(IntWritable.class); //我们当前任务的Reducer类是谁 job.setReducerClass(WordCountReducer.class); //我们Reducer任务输出的文件的Key值类型 job.setOutputKeyClass(Text.class); //我们Reducer任务输出的文件的Value值类型 job.setMapOutputValueClass(IntWritable.class); //关联我们HDFS文件 HDFS文件的绝对路径 //输入的路径是文件夹 把这个文件夹下面的所有文件 都执行一遍 FileInputFormat.setInputPaths(job,new Path("/file/偏爱.txt/")); //最终要有一个结果 我最终计算完成生成的结果存放在HDFS上的哪里 //Mapper执行的后的结果是一个临时文件 这个文件存放在本地 //Reducer执行后的结果自动的上传到HDFS之上 并且还会把Mapper执行后的结果给删除掉 FileOutputFormat.setOutputPath(job,new Path("/out/")); job.waitForCompletion(true); //我们关联完毕后 我们要执行了 } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
三、实现流程
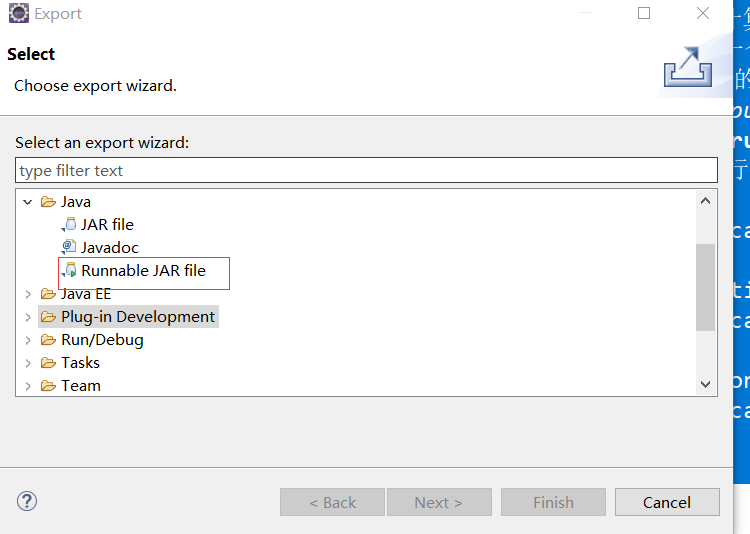
3.1 打成jar包(eclipse)

3.2启动Hadoop
start-dfs.sh
start-yarn.sh
3.3上传素材和jar包
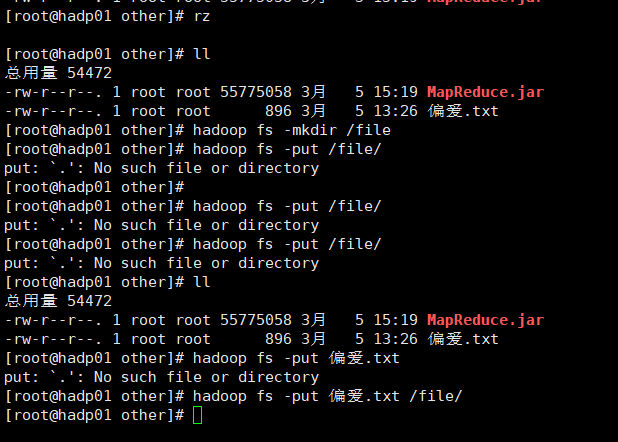

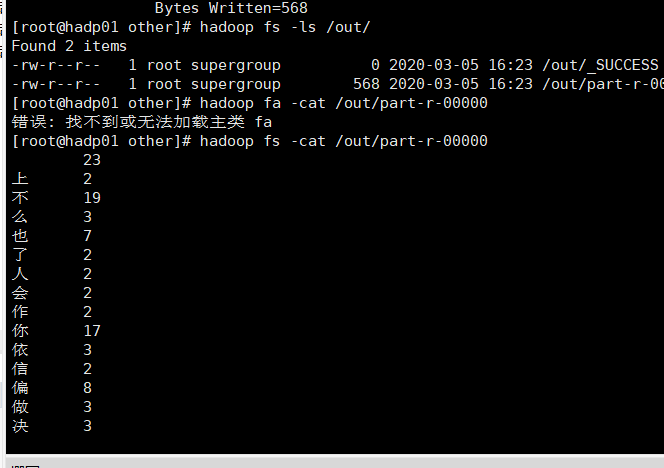
3.4 运行成功如下
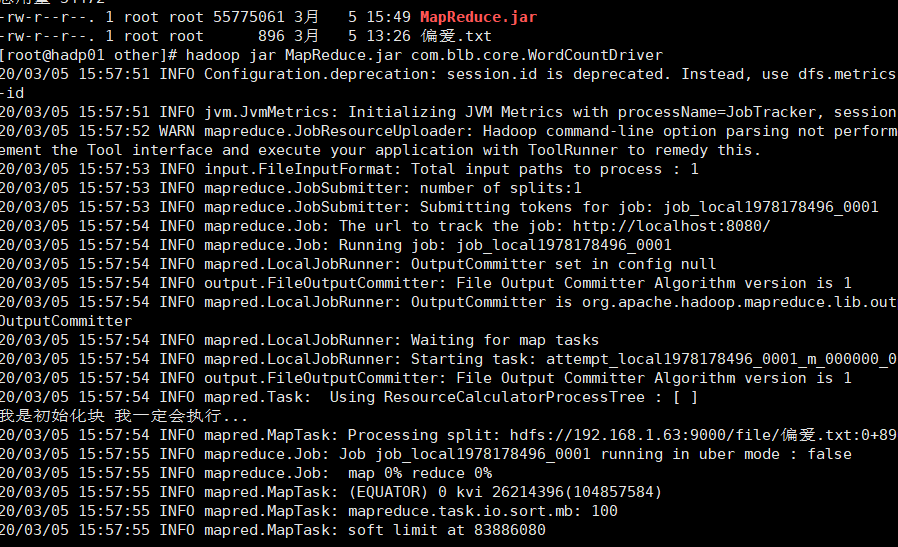
3.5 最终结果