在实践中,使用Jenkins发送测试报告,收到邮件,邮件内容中的中文为乱码,邮件发送的方式是在Jenkins发邮件设置中设置邮件内容为:${FILE,path="report_ug.html"} ,其中report_ug.html 就是报告内容的html
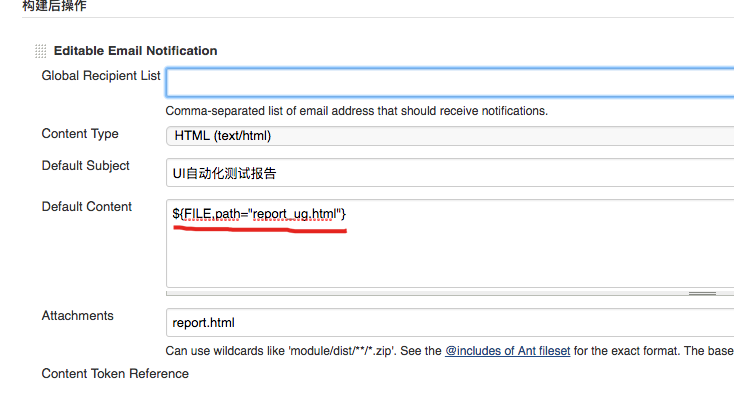
report_ug.html java生成方式:代码就是生成一个html字符串,把这个字符串保存为report_ug.html 文件
public class Test { public static void main(String[] args) { String content ="<html> " + " <head> " + " <meta http-equiv="content-type" content="text/html;charset=utf-8" /> " + " </head> " + "<body lang=ZH-CN> " + " 还有乱码么a安抚?:.发送。; utf-8 is there any wrong code ? 18888899999 " + "</body> " + "</html>"; FileOperation.write(ConfigUtil.getAutoCofigRootPath()+"report_ug.html",content,"GBK"); } }
发送的邮件显示为乱码:

网上查找解决办法,但是由于Jenkins管理权限在其他部门,而且使用比较久,也不会随意变更一些什么设置,只有只有从代码上解决问题
首先,网上有的说html保存的时候要以GBK编码方式保存,但是不知道为什么,怎么保存GBK编码方式的html文件都不能解决问题。最后找到从代码上解决的办法,那就是把html文件中的所有中文,以Unicode编码16进制编码保存。
中文 Unicode编码16进制 编码查询地址为:http://www.mytju.com/classcode/tools/encode_gb2312.asp,如查找“还有乱码么”的ascii为:

这样,就需要把html中的每个中文找出来,并转换成Unicode编码16进制编码,在这个编码前面加个"&#x" ,后面加个";" ,如:“还”字的编码为“8FD8”,在html中保存为:"还"
Java 代码需要处理的步骤为:
1、遍历字符串,如果是中文,就转换为16进制Unicode编码
2、遍历字符串,如果是中文标点,就转换为16进制Unicode编码
3、重新组装html
import java.io.UnsupportedEncodingException; import java.util.regex.Matcher; import java.util.regex.Pattern; public class Convert { public static String stringToUnicode16(String s) { // 先把字符串转换为ASCII码 //保存重新组装的html代码 StringBuffer temp = new StringBuffer(); // 把字符中转换为字符数组 char[] chars = s.toCharArray(); for (int i = 0; i < chars.length; i++) { if (isChinese(String.valueOf(chars[i])) || isChinesePunctuation(chars[i])) { temp.append("&#x" + Integer.toHexString((int) chars[i]) + ";"); } else { temp.append(String.valueOf(chars[i])); } } return temp.toString(); } public static boolean isChinese(String str) { //判断是否是中文 String regEx = "[u4e00-u9fa5]"; Pattern pat = Pattern.compile(regEx); Matcher matcher = pat.matcher(str); boolean flg = false; if (matcher.find()) flg = true; return flg; } // 根据UnicodeBlock方法判断中文标点符号 public static boolean isChinesePunctuation(char c) { Character.UnicodeBlock ub = Character.UnicodeBlock.of(c); if (ub == Character.UnicodeBlock.GENERAL_PUNCTUATION || ub == Character.UnicodeBlock.CJK_SYMBOLS_AND_PUNCTUATION || ub == Character.UnicodeBlock.HALFWIDTH_AND_FULLWIDTH_FORMS || ub == Character.UnicodeBlock.CJK_COMPATIBILITY_FORMS || ub == Character.UnicodeBlock.VERTICAL_FORMS) { return true; } else { return false; } } }
这样,html中的中文就以16进制Unicode编码 保存。
调用方式为:
import com.paxunke.smart.utils.*; public class Test { public static void main(String[] args) { String content = "<html> " + " <head> " + " <meta http-equiv="content-type" content="text/html;charset=utf-8" /> " + " </head> " + "<body lang=ZH-CN> " + " 还有乱码么a安抚?:.发送。; utf-8 is there any wrong code ? 18888899999 " + "</body> " + "</html>"; String temp = Convert.stringToUnicode16(content); System.out.println(temp); FileOperation.write(ConfigUtil.getAutoCofigRootPath() + "report_ug.html", temp, "GBK"); } }
执行,打印的html文件内容为:
<html> <head> <meta http-equiv="content-type" content="text/html;charset=utf-8" /> </head> <body lang=ZH-CN> 还有乱码么a安抚?:.发送。; utf-8 is there any wrong code ? 18888899999 </body> </html>
再把这个文件在Jenkins中发送邮件,乱码问题解决
