1、标记清除算法
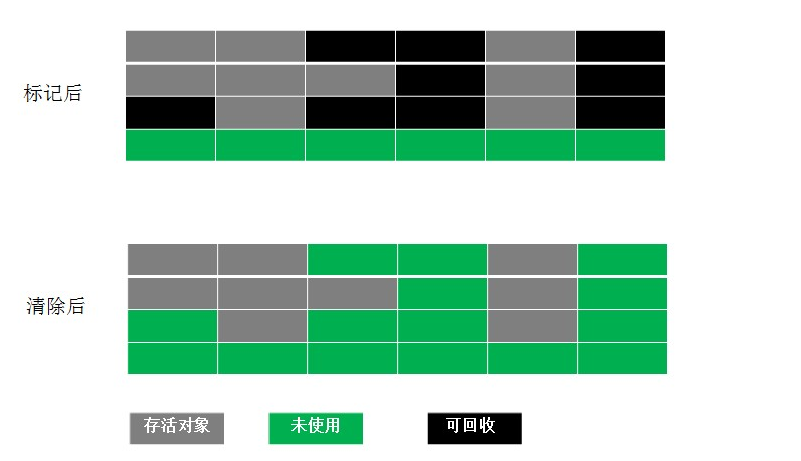
标记清除算法是Java虚拟机垃圾收集最基础的算法,该算法分为标记和清除两个阶段:首先标记出所有需要回收的对象,在标记完成后,统一对所有标记完成的对象进行回收。标记清除法主要有两个不足:一个是效率问题,标记和清除的效率都不高;;另一个是空间问题,如下图可以看出标记清除之后会产生大量的不连续的的内存碎片,内存碎片过多会导致大对象无法分配到足够的连续内存,从而不得不提前触发垃圾收集行为。
2、复制算法
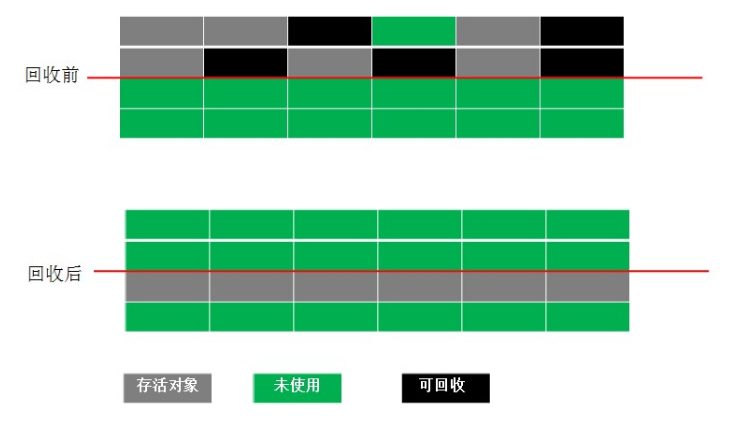
复制算法是建立在标记清除法的基础之上,为了解决标记清除法的效率以及内存碎片问题;其核心思想是将内存分为大小相等的两块,每次使用其中的一块内存。在垃圾收集时,将正在使用的内存中的需要清除的对象进行标记,将不需要清除的对象复制到另外一块内存上,然后在已使用过的内存进行垃圾回收。这样每次都是对整个内存中的一半内存进行回收,内存分配时不用考虑内存碎片等复杂问题,只需要将对象的指针按照顺序移动到另外一块内存区域中即可,实现简单,运行高效。复制算法的代价是将内存缩小为原来的一半。
现在的虚拟机都是采用这种算法来回收新生代(Survivor区就是这样进行垃圾收集的),因为绝大多数对象(90%以上的对象)都是朝生夕死,所以并不能按照1:1的比例来分配新生代内存空间,而是将新生代内存分为一块较大的Eden区和两块较小的Survivor区,每次使用Eden区和其中一块Survivor区,当发生垃圾收集时,将Eden区和Survivor区中存活的对象复制到另外一块Survivor区上。,然后清除Eden空间和已使用的Survivor区的内存。HotSpot虚拟机的Eden区和Survivor区默认的比例为8:1,也就说新生代中可用内存总是占用整个新生代的90%,这样浪费的内存就比较有限。
3、标记整理(标记压缩)算法
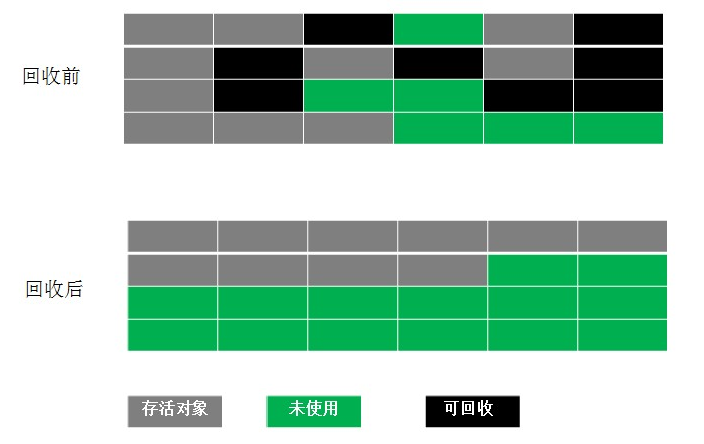
复制算法在对象存活率较高时,需要进行比较多的复制操作,效率将会降低,最主要的是复制算法会浪费内存空间。标记整理算法是在标记清除算法的基础之上发展的,标记整理算法分为标记和整理两个阶段:首先使用标记阶段,标记出所有不需要进行收集对象;然后是整理阶段,移动所有存活的对象,且按照内存地址次序进行排列,然后将末端内存地址以后的内存全部回收。标记整理完成后,当需要给新对象分配内存时,虚拟机只需要持有一个内存的起始地址即可。不难看出,标记整理算法不仅可以弥补标记清除算法当中,内存碎片的缺点,也可以消除复制算法当中,内存减半的代价,但是标记整理算法唯一的缺点就是效率不高,不仅需要标记所有存活对象,还要整理存活对象的引用地址,从效率上来说,标记整理算法低于复制算法(这也是为什么FullGC系统开销要远远大于YGC)。
4、分代算法
当前商业虚拟机基本上都是使用分代垃圾收集算法,其思想就是根据对象的生命周期将内存划分为不同的几个内存区域。一般是把Java的堆空间划分为年轻代和年老代,这样就可以根据各个年代的特点选择不同的垃圾收集算法;而年轻代又划分为Eden区和两块Survivor区。当虚拟机创建一个对象的时候,总是在Eden区操作,当Eden区满了之后,经过一次YoungGC(简称YGC,也称之为MinorGC),对象进入其中一块Survivor区,然后对象在两个Survivor来回复制,在新生代中,由于每次垃圾收集时都会有大量的对象死去,只有少量的对象存活,所以在新生代中选择复制算法进行垃圾收集。当对象经过若干次YGC之后,如果仍然存活,将会进入老年代,因为老年代的对象存活率较高,因此选择标记整理算法进行垃圾收集。