读流程
HBase读数据流程如图3所示
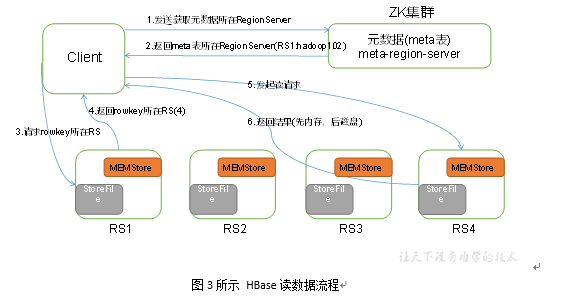
1)Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息;
2)根据namespace、表名和rowkey在meta表中找到对应的region信息;
3)找到这个region对应的regionserver;
4)查找对应的region;
5)先从MemStore找数据,如果没有,再到BlockCache里面读;
6)BlockCache还没有,再到StoreFile上读(为了读取的效率);
7)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。
2 写流程
Hbase写流程如图2所示
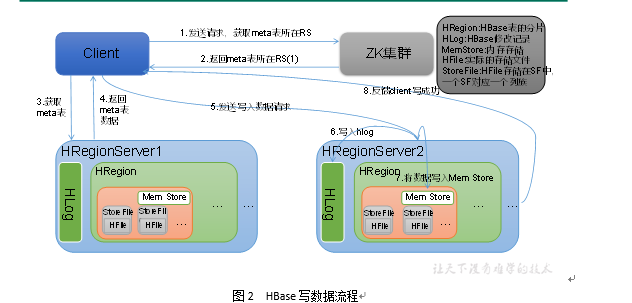
1)Client向HregionServer发送写请求;
2)HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复;
3)HregionServer将数据写到内存(MemStore);
4)反馈Client写成功。
3 数据Flush过程
1)当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
2)并将数据存储到HDFS中;
3)在HLog中做标记点。
4 数据合并过程
1)当数据块达到4块,Hmaster触发合并操作,Region将数据块加载到本地,进行合并;
2)当合并的数据超过256M,进行拆分,将拆分后的Region分配给不同的HregionServer管理;
3)当HregionServer宕机后,将HregionServer上的hlog拆分,然后分配给不同的HregionServer加载,修改.META.;
4)注意:HLog会同步到HDFS。