1、Hive的内表
Hive 的内表,就是正常创建的表,在 http://www.cnblogs.com/raphael5200/p/5208437.html 中已经提到;
2、Hive的外表
创建Hive 的外表,需要使用关键字 External:
CREATE EXTERNAL TABLE [IF NOT EXISTS] [db_name.]table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...)
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
下面看一个例子:
create External table food_ex ( id int, name string, category string, price double ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' lines terminated by ' ';
-- 加载数据 load data local inpath '/opt/food.txt' overwrite into table food_ex;
select * from food_ex;


这两个,左边是外表,右边是内表从大体上看似乎没什么区别,但是他的主要区别在于删除操作上:
内表删除表或者分区元数据和数据都删了
外表删除表元数据删除,数据保留
下面分别执行两条语句:
drop table food; drop table food_ex;
执行这两条语句以后,两个表都删除了,但是结果却不一样,访问NameNode的50070端口:
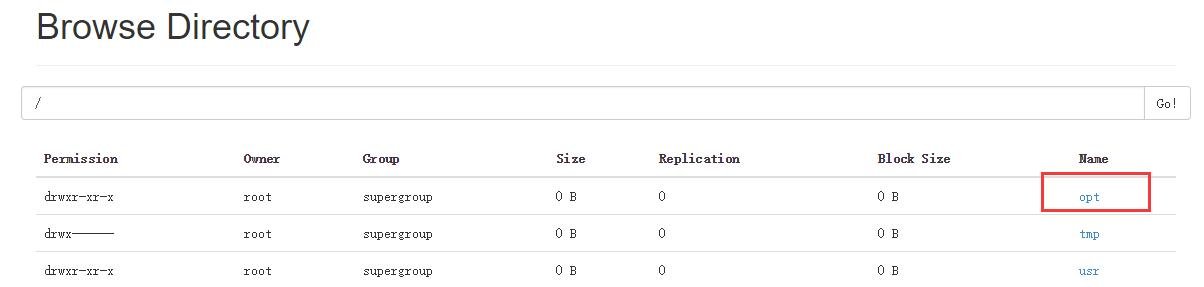
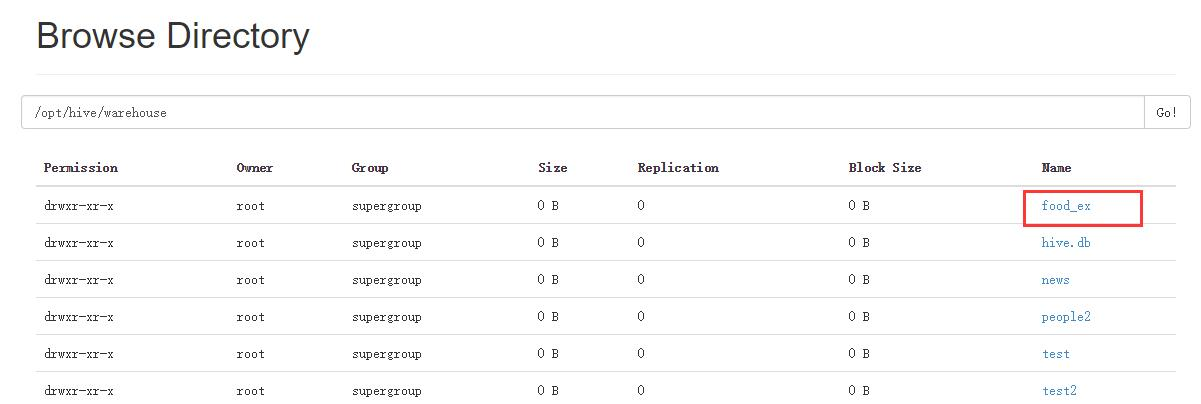

可以看到,虽然都执行了表删除语句,内表删除后是把元数据和数据都删除了,而外表却只删除了元数据(表的信息)但真实数据却保留了下来;
3、Hive的分区partition
必须在表定义时创建partition
a、单分区建表语句:
create table day_table (id int, content string) partitioned by (dt string);
单分区表,按天分区,在表结构中存在id,content,dt三列。 以dt为文件夹区分
例:
create table log_info ( ip string ) PARTITIONED BY(times string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' lines terminated by ' ';
# 下面是log_info 的表结构信息,分区已经创建
hive> desc log_info;
OK
ip string
times string
# Partition Information
# col_name data_type comment
times string
Time taken: 0.077 seconds, Fetched: 7 row(s)
b、 双分区建表语句
create table day_hour_table (id int, content string) partitioned by (dt string, hour string);
双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。 先以dt为文件夹,再以hour子文件夹区分
create table log_info2 ( ip string ) PARTITIONED BY(days string,hours string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' lines terminated by ' ';
# 下面是log_info2 的表结构信息,分区已经创建
hive> desc log_info2;
OK
ip string
days string
hours string
# Partition Information
# col_name data_type comment
days string
hours string
Time taken: 0.08 seconds, Fetched: 9 row(s)
c、Hive添加分区表语法 (表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... ALTER TABLE day_table ADD PARTITION (dt='2008-08-08', hour='08') location '/path/pv1.txt'
d、Hive删除分区语法:
ALTER TABLE table_name DROP PARTITION partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。
ALTER TABLE day_hour_table DROP PARTITION (dt='2008-08-08', hour='09');
alter table log_info drop partition (times='20160222');
e、Hive数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例:
单分区数据加载
load data local inpath '/opt/log' overwrite into table log_info partition(times='20160223'); load data local inpath '/opt/log2' overwrite into table log_info partition(times='20160222');
hive> select * from log_info; OK 23.45.66.77 20160222 45.66.11.8 20160222 2.3.4.5 20160223 4.56.77.31 20160223 34.55.6.77 20160223 34.66.11.6 20160223 Time taken: 0.125 seconds, Fetched: 6 row(s)
在Hive中会根据分区的名称新建两个分区目录

双分区数据加载
load data local inpath '/opt/log3' overwrite into table log_info2 partition(days='23',hours='12');
hive> select * from log_info2; OK 12.3.33.66 23 12 23.44.56.6 23 12 12.22.33.4 23 12 8.78.99.4 23 12 233.23.211.2 23 12 Time taken: 0.069 seconds, Fetched: 5 row(s)

当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录 基于分区的查询的语句:
SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08';
f、Hive查看分区语句:
hive> show partitions day_hour_table; OK dt=2008-08-08/hour=08 dt=2008-08-08/hour=09 dt=2008-08-09/hour=09
hive> show partitions log_info; OK times=20160222 times=20160223 Time taken: 0.06 seconds, Fetched: 2 row(s)