DB:数据库(database):存储数据的“仓库”。它保存了一系列有组织的数据。
DBMS:数据库管理系统(Database Management System)。数据库是通过DBMS创建和操作的容器
1. 基于共享文件系统的DBMS (Access )
2.基于客户机——服务器的DBMS (MySQL、Oracle、SqlServer)
SQL:结构化查询语言(Structure Query Language):专门用来与数据库通信的语言。
SQL:
1、DML(Data Manipulation Language):数据操纵语句,
用于添加、删除、修改、查询数据库记录,并检查数据完整性
INSERT:添加数据到数据库中
UPDATE:修改数据库中的数据
DELETE:删除数据库中的数据
SELECT:选择(查询)数据
SELECT是SQL语言的基础,最为重要。
2、DDL(Data Definition Language):数据定义语句,用于库和表的创建、修改、删除。
CREATE TABLE:创建数据库表
ALTER TABLE:更改表结构、添加、删除、修改列长度
DROP TABLE:删除表
CREATE INDEX:在表上建立索引
DROP INDEX:删除索引
3、DCL(Data Control Language):数据控制语句,用于定义用户的访问权限和安全级别。
GRANT:授予访问权限
REVOKE:撤销访问权限
COMMIT:提交事务处理
ROLLBACK:事务处理回退
SAVEPOINT:设置保存点
LOCK:对数据库的特定部分进行锁定
Mysql:
启动:net start mysql服务名 停止:net stop mysql服务名
MySQL服务端的登录和退出
mysql –h 主机名 –u用户名 –p密码
exit
语法规范:
不区分大小写
每句话用;或g结尾
各子句一般分行写
关键字不能缩写也不能分行
用缩进提高语句的可读性
类型一样 隐式转换

常用命令:

查看表的结构 desc tb_emp;
show tables;
删除表: droptable表名
insert into 表名(列名列表) values(列对应的值的列表);
注意:插入varchar或date型的数据要用单引号引起
修改记录: update 表名 set 列1 = 列1的值, 列2 = 列2的值 where ...
删除记录: delete from 表名 where ....
去重:DISTINCT
数据处理之查询:
• 基本的SELECT语句
SELECT *|{[DISTINCT] column|expression [alias],...} FROM table;
SELECT 标识选择哪些列。
FROM 标识从哪个表中选择。
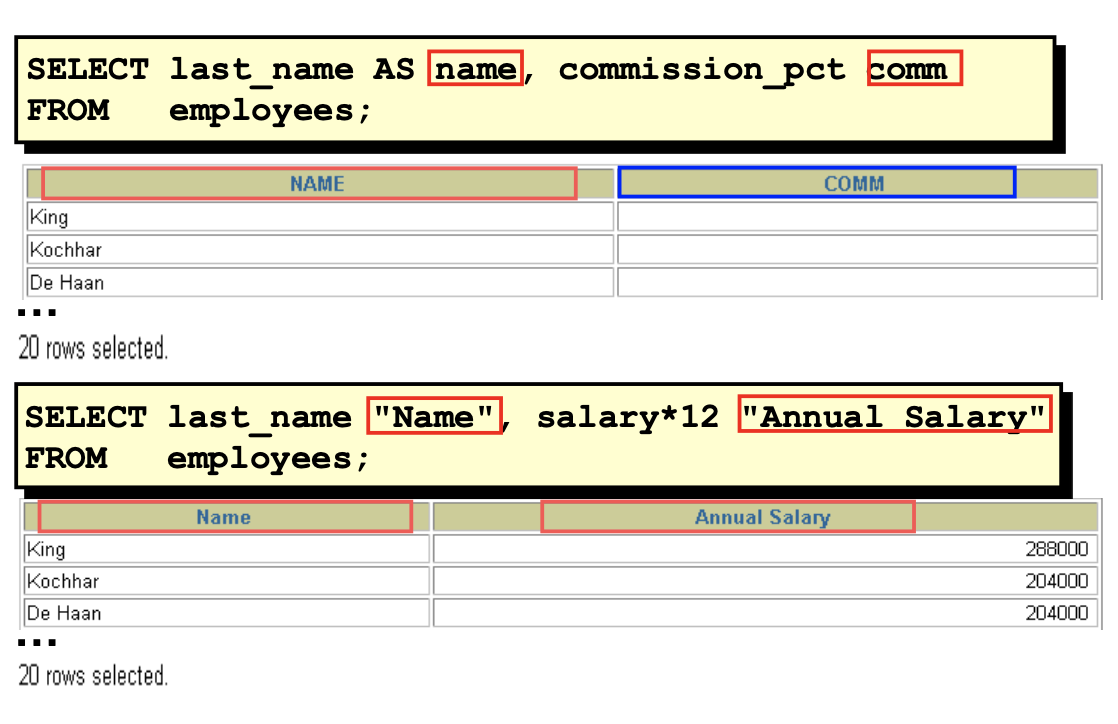
列的别名:
• 重命名一个列。
• 便于计算 列的别名:
• 紧跟列名
• 过滤和排序数据
使用WHERE 子句,将不满足条件的行过滤掉

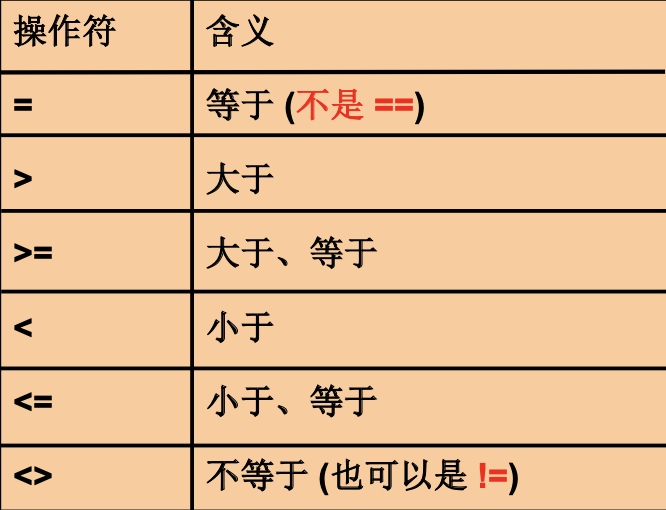
比较运算:
• 分组函数



使用 LIKE 运算选择类似的值
选择条件可以包含字符或数字:
% 代表零个或多个字符(任意个字符)。 _ 代表一个字符。
‘%’和‘-’可以同时使用

使用 IS (NOT) NULL 判断空值。





ORDER BY子句
使用 ORDER BY 子句排序
ASC(ascend): 升序
DESC(descend): 降序
• ORDERBY子句在SELECT语句的结尾。



分组查询
组函数类型
AVG() COUNT() MAX() MIN() SUM()

可以对数值型数据使用AVG 和 SUM 函数。

可以对任意数据类型的数据使用 MIN 和 MAX 函数。
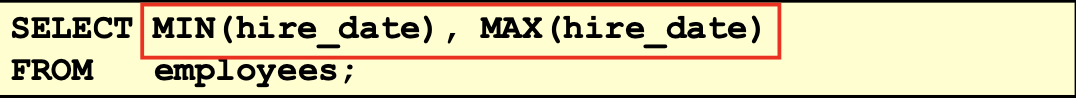
COUNT(*) 返回表中记录总数,适用于任意数据类型。

分组数据: GROUP BY 子句语法
可以使用GROUP BY子句将表中的数据分成若干组

WHERE一定放在FROM后面
在SELECT 列表中所有未包含在组函数中的列都应该包含 在 GROUP BY 子句中。

在GROUP BY子句中包含多个列
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中

在GROUP BY子句中包含多个列

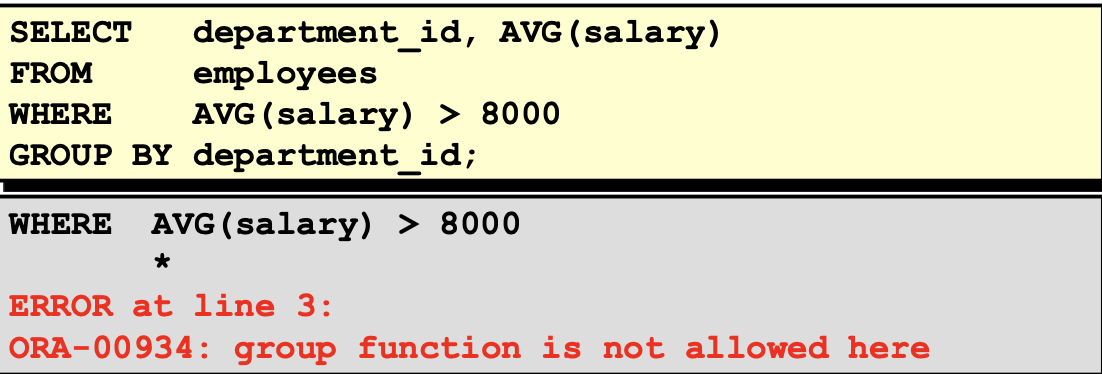
非法使用组函数:
不能在 WHERE 子句中使用组函数。
可以在 HAVING 子句中使用组函数。
过滤分组: 过滤分组
过滤分组: HAVING 子句
使用 HAVING 过滤分组:
1. 行已经被分组。
2. 使用了组函数。
3. 满足HAVING 子句中条件的分组将被显示。


多表查询
笛卡尔集
笛卡尔集会在下面条件下产生:
– 省略连接条件
– 连接条件无效
– 所有表中的所有行互相连接
为了避免笛卡尔集, 可以在 WHERE 加入有效的连接条件。
Mysql 连接
使用连接在多个表中查询数据。

在 WHERE 子句中写入连接条件。
在表中有相同列时,在列名之前加上表名前缀
等值连接

区分重复的列名
使用表名前缀在多个表中区分相同的列。
在不同表中具有相同列名的列可以用表的别名加以区分。
如果使用了表别名,则在select语句中需要使用表别名代替表名
表别名最多支持32个字符长度,但建议越少越好
表的别名
使用别名可以简化查询。
使用表名前缀可以提高执行效率。

连接多个表
连接 n个表,至少需要 n-1个连接条件。 例如:连接 三个表,至少需要两个连接条件。
使用ON 子句创建连接
自然连接中是以具有相同名字的列为连接条件的。
可以使用 ON 子句指定额外的连接条件。
这个连接条件是与其它条件分开的。
ON 子句使语句具有更高的易读性。
Join连接
内连接 [inner] join on
自连接 根据自己表查到的数据再通过查到饿数据在自己表里再找
外连接:查询一个表有。一个表没有的场景
外连接
• 左外连接 left [outer] join on

• 右外连接 right [outer] join on

加 Where条件:取一半
不支持
常见函数;
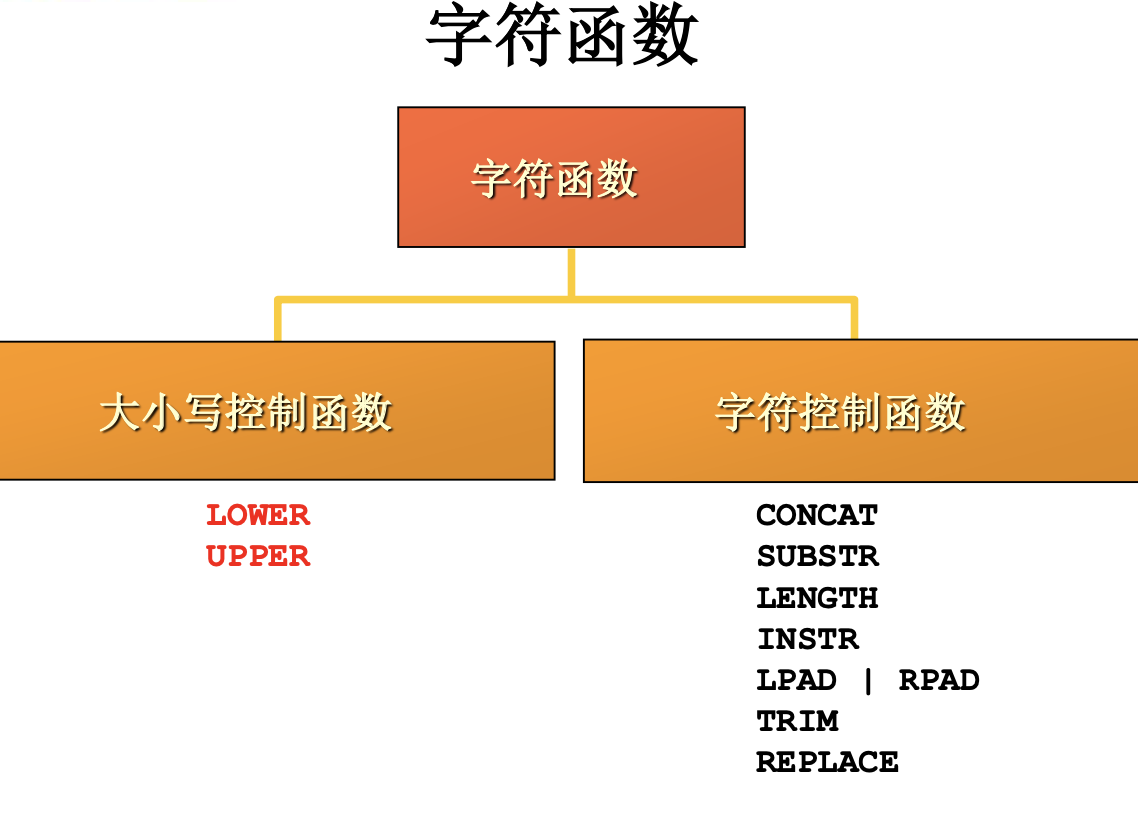
字符函数
数学函数
日期函数
其他函数【补充】
流程控制函数【补充】
条件表达式
• 在 SQL 语句中使用IF-THEN-ELSE 逻辑
• 使用方法:
– CASE 表达式


子查询
概念:出现在其他语句内部的select语句,称为子 查询或内查询
内部嵌套其他select语句的查询,称为外查询或主 查询
select first_name from employees where
department_id in(
select department_id from departments where location_id=1700
)
• 子查询要包含在括号内。
• 将子查询放在比较条件的右侧。
• 单行操作符对应单行子查询,多行操作符对应 多行子查询。
非法使用子查询:
![]()
子查询中的空值问题:
![]()
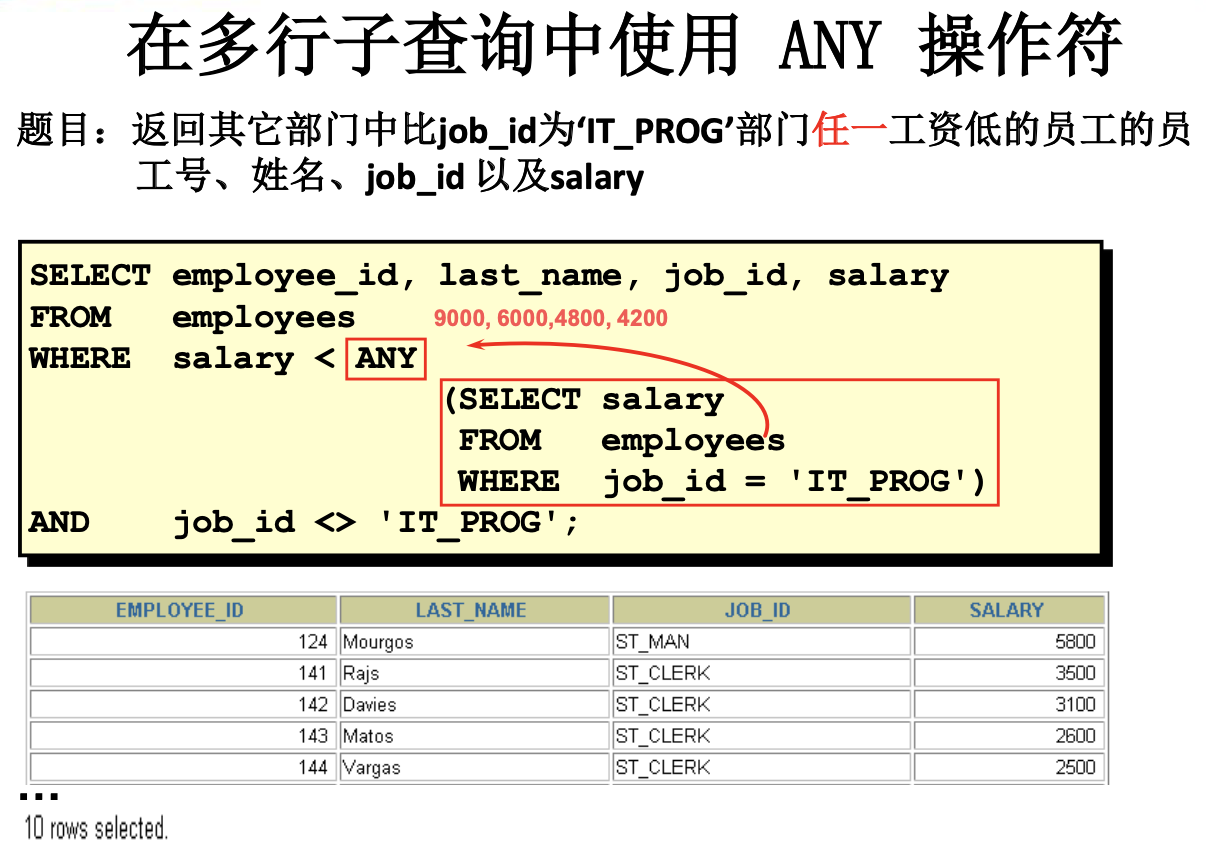
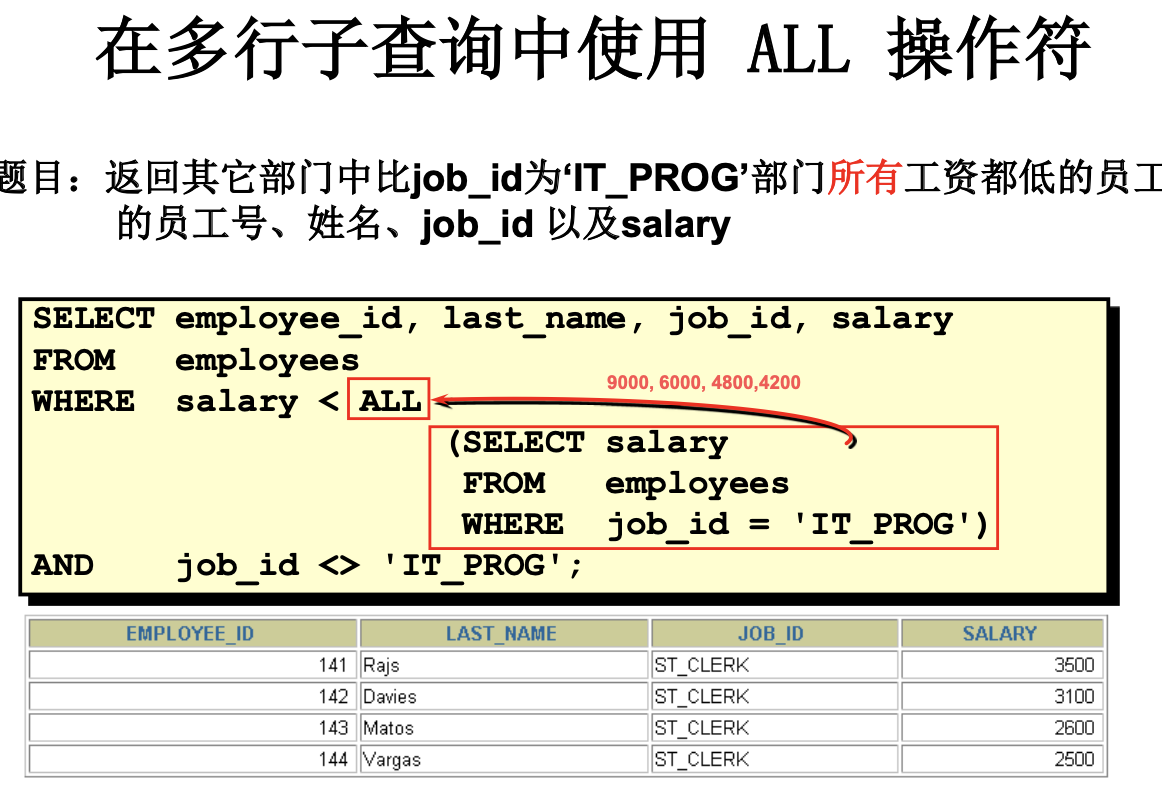
多行子查询
返回多行。
使用多行比较操作符。

创建和管理表
创建数据库
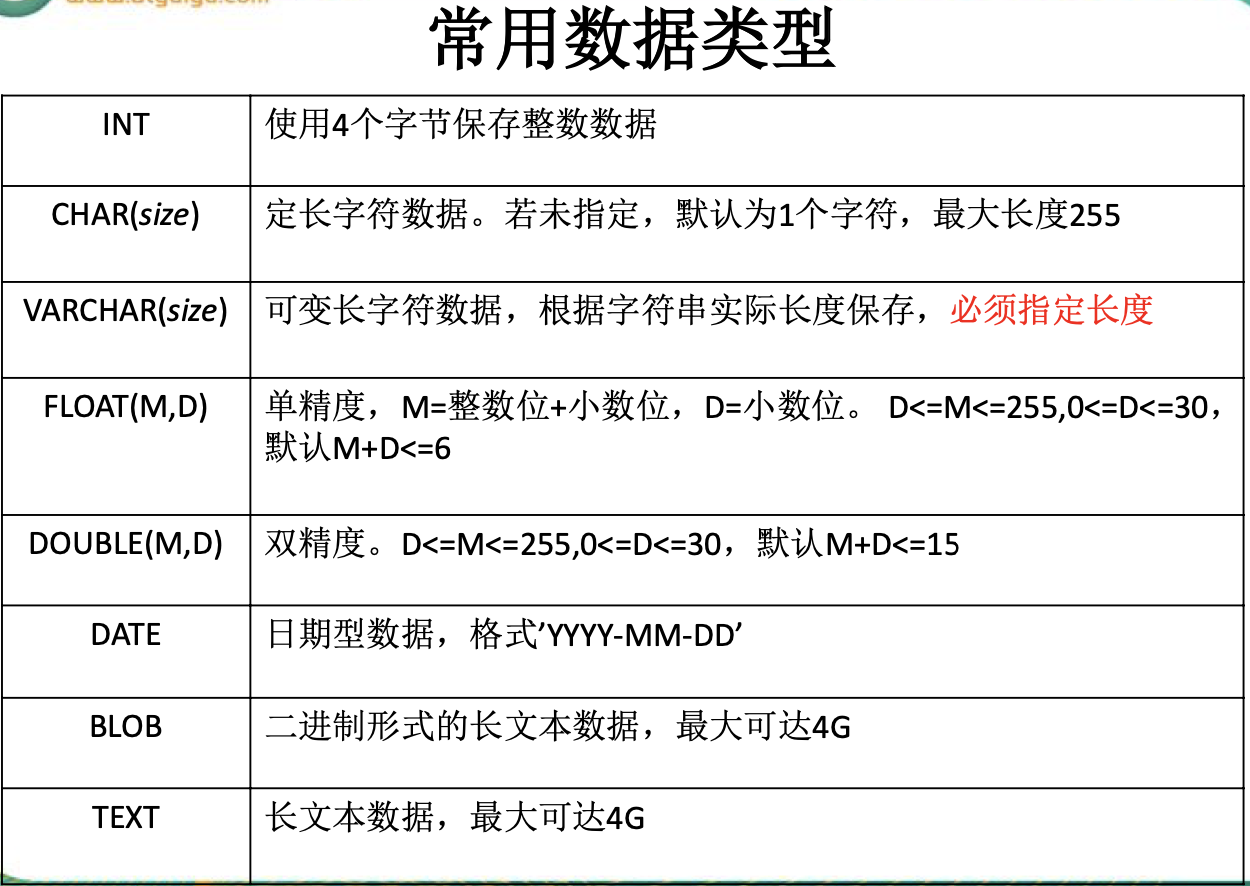
创建表
描述各种数据类型
修改表的定义
删除,重命名和清空表


使用子查询创建表
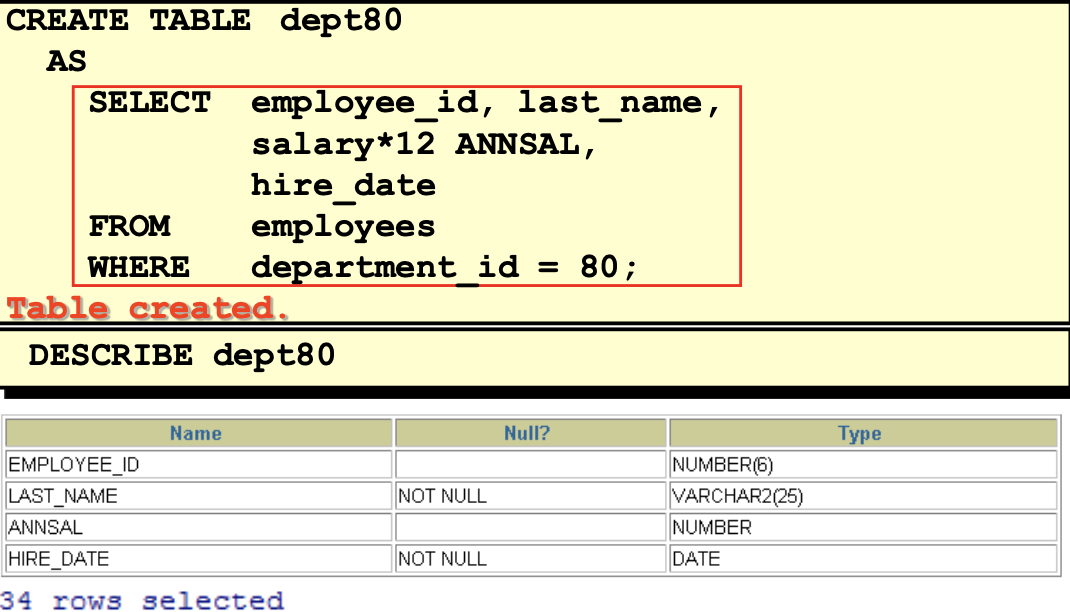
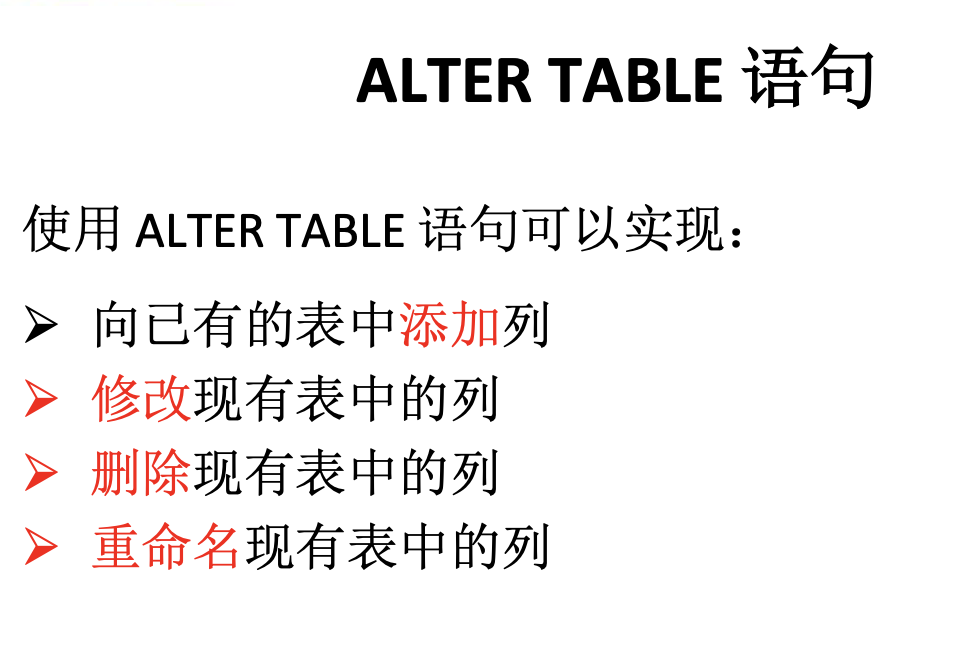
ALTER TABLE dept80
ADD job_id varchar(15);
ALTER TABLE dept80
MODIFY (last_name VARCHAR(30));
ALTER TABLE dept80
DROP COLUMN job_id;
重命名一个列
ALTER TABLE dept80
CHANGE department_name dept_name varchar(15);
删除表
数据和结构都被删除
所有正在运行的相关事务被提交
所有相关索引被删除
DROP TABLE 语句不能回滚
清空表
TRUNCATE TABLE
语句: 删除表中所有的数据
释放表的存储空间
TRUNCATE语句不能回滚
可以使用 DELETE 语句删除数据,可以回滚
执行RENAME语句改变表, 视图的名称
ALTER table dept RENAME TO detail_dept;
必须是对象的拥有者
约束和分页
描述约束
创建和维护约束
数据库分页
为了保证数据的一致性和完整性,SQL规范以约 束的方式对表数据进行额外的条件限制。
约束是表级的强制规定
可以在创建表时规定约束(通过 CREATE TABLE 语句),或者在表创建之后也可以(通 过 ALTER TABLE 语句)
约束
有以下六种约束:
– NOT NULL 非空约束,规定某个字段不能为空
– UNIQUE 唯一约束,规定某个字段在整个表中是唯一的 – PRIMARY KEY 主键(非空且唯一)
– FOREIGN KEY 外键
– CHECK 检查约束
– DEFAULT 默认值
注意: MySQL不支持check约束,但可以使用check约束,而没有任何效果; 具体细节可以参阅W3Cschool手册
根据约束数据列的限制,约束可分为: – 单列约束:每个约束只约束一列
– 多列约束:每个约束可约束多列数据
根据约束的作用范围,约束可分为:
– 列级约束只能作用在一个列上,跟在列的定义后面
– 表级约束可以作用在多个列上,不与列一起,而是 单独定义
MySQL中使用limit实现分页
SELECT * FROM table LIMIT(PageNo - 1)*PageSize,PageSize;
limit子句必须放在整个查询语句的最后!
事务
事务的概念和特性
事务的隔离级别
事务由单独单元的一个或多个SQL语句组成,
在这 个单元中,每个MySQL语句是相互依赖的。
而整个单独单 元作为一个不可分割的整体,
如果单元中某条SQL语句一 旦执行失败或产生错误,
整个单元将会回滚。
所有受到影 响的数据将返回到事物开始以前的状态;如果单元中的所
有SQL语句均执行成功,则事物被顺利执行。
show engines;
在mysql中用的最多的存储引擎有:innodb, myisam ,memory 等。
其中innodb支持事务,而 myisam、memory等不支持事务
事务的ACID(acid)属性
1. 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么 都发生,要么都不发生。
2. 一致性(Consistency) 事务必须使数据库从一个一致性状态变换到另外一个一致性状态。
3. 隔离性(Isolation) 事务的隔离性是指一个事务的执行不能被其他事务干扰,
即一个 事务内部的操作及使用的数据对并发的其他事务是隔离的,并发 执行的各个事务之间不能互相干扰。
4. 持久性(Durability) 持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,
接下来的其他操作和数据库故障不应该对其有任何影响
1.以第一个 DML 语句的执行作为开始
2.以下面的其中之一作为结束: COMMIT 或 ROLLBACK 语句
DDL 或 DCL 语句(自动提交) 用户会话正常结束
系统异常终了
对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时,
如果没有采取必要的隔离机制, 就会导致各种并发问题:
脏读: 对于两个事务 T1, T2, T1 读取了已经被 T2 更新
但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的.
不可重复读: 对于两个事务T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了.
幻读: 对于两个事务T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插 入了一些新的行. 之后,
如果 T1 再次读取同一个表, 就会多出几行.
数据库事务的隔离性: 数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题.
一个事务与其他事务隔离的程度称为隔离级别.
数据库规定了多种事务隔 离级别, 不同隔离级别对应不同的干扰程度,
隔离级别越高, 数据一致性就 越好, 但并发性越弱.
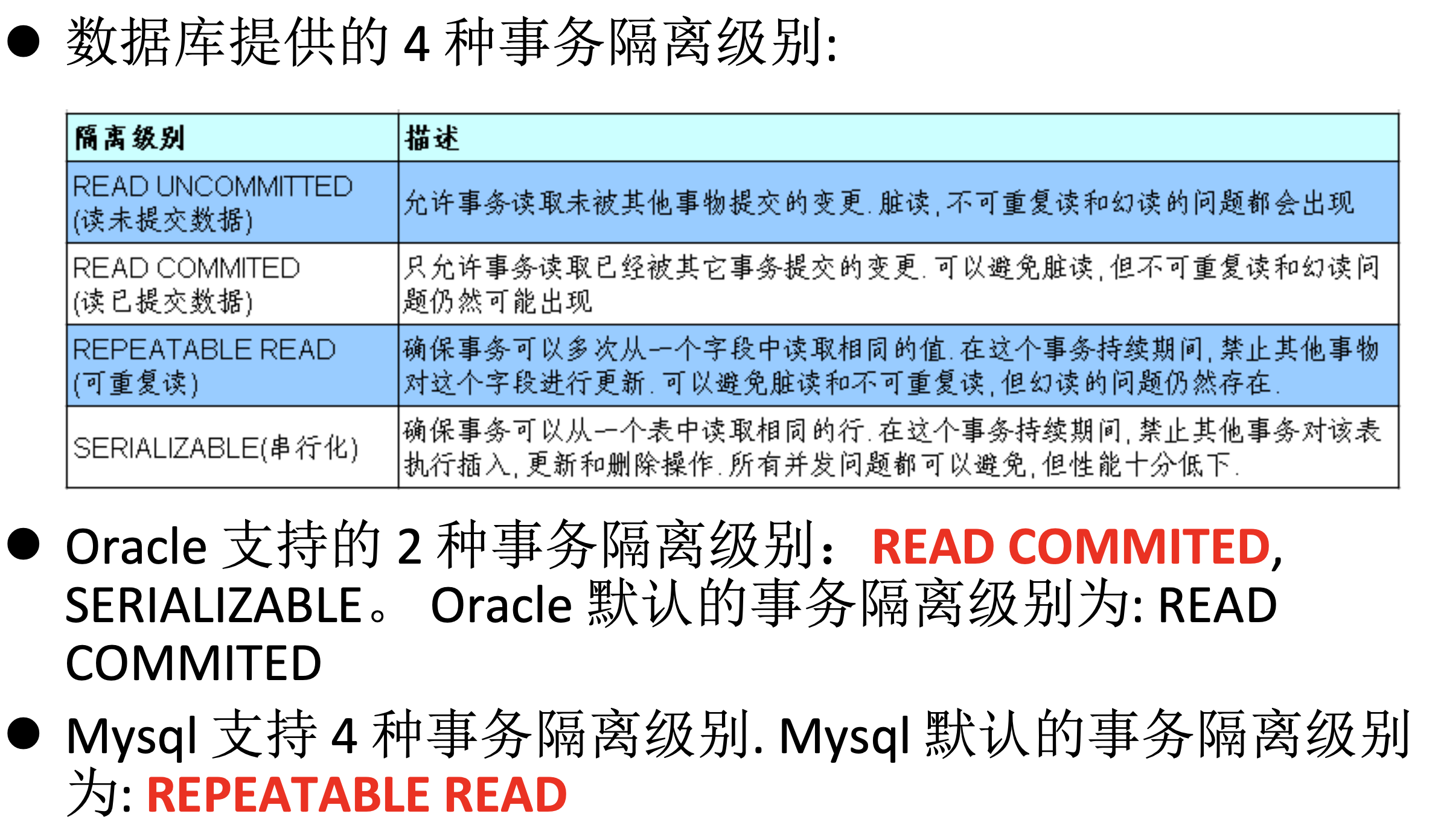
看当前的隔离级别:
SELECT @@tx_isolation;
设置当前 mySQL 连接的隔离级别:
set transaction isolation level read committed;
设置数据库系统的全局的隔离级别:
set global transaction isolation level read committed;
视图
MySQL从5.0.1版本开始提供视图功能。
一种虚拟 存在的表,行和列的数据来自定义视图的查询中使用的表 ,
并且是在使用视图时动态生成的,只保存了sql逻辑,不保存查询结果
应用场景:
– 多个地方用到同样的查询结果
– 该查询结果使用的sql语句较复杂
CREATE VIEW my_v1
AS
SELECT studentname,majorname FROM student s
INNER JOIN major m ON s.majorid=m.majorid WHERE s.majorid=1;
视图的好处:
重用sql语句
简化复杂的sql操作,不必知道它的查询细节
保护数据,提高安全性




存储过程和函数
什么是存储过程和函数
使用存储过程和函数的好处
创建存储过程和函数
修改存储过程和函数
调用存储过程和函数
查看存储过程和函数
存储过程和函数:
事先经过编译并存储在数据库中的一段sql语句的
集合。
使用好处:
1、简化应用开发人员的很多工作
2、减少数据在数据库和应用服务器之间的传输 减少了编译次数
3、提高了数据处理的效率



流程控制结构


索引是什么?
1MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
MySql中的索引
mysql默认存储引擎innodb只显式支持B-Tree( 从技术上来说是B+Tree)索引
普通索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
聚簇索引(聚集索引):并不是一种单独的索引类型,而是一种数据存储方式。
具体细节取决于不同的实现,InnoDB的聚簇索引其实就是在同一个结构中保存了B-Tree索引(技术上来说是B+Tree)和数据行。
非聚簇索引:不是聚簇索引,就是非聚簇索引
mysql优化
策略1.尽量全值匹配
策略2.最佳左前缀法则
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
策略3.不在索引列上做任何操作
不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
策略4.范围条件放最后
存储引擎不能使用索引中范围条件右边的列
策略5.覆盖索引尽量用
尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
策略6.不等于要甚用
mysql 在使用不等于(!= 或者<>)的时候无法使用索引会导致全表扫描
策略7.Null/Not 有影响
注意null/not null对索引的可能影响
like以通配符开头('%abc...')mysql索引失效会变成全表扫描的操作
策略九 字符类型加引号
字符串不加单引号索引失效
策略10.OR改UNION效率高
