K-means聚类 的 Python 实现
K-means聚类是一个聚类算法用来将 n 个点分成 k 个集群。
算法有3步:
1.初始化– K 个初始质心会被随机生成
2.分配 – K 集群通过关联到最近的初始质心生成
3.更新 –重新计算k个集群对应的质心
分配和更新会一直重复执行直到质心不再发生变化。
最后的结果是点和质心之间的均方差达到最小。
以 k=3 为例演示这个过程:
初始化

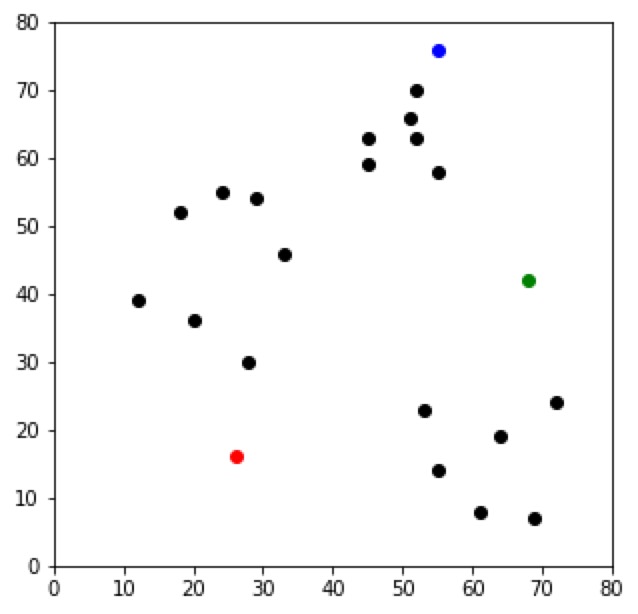
分配:

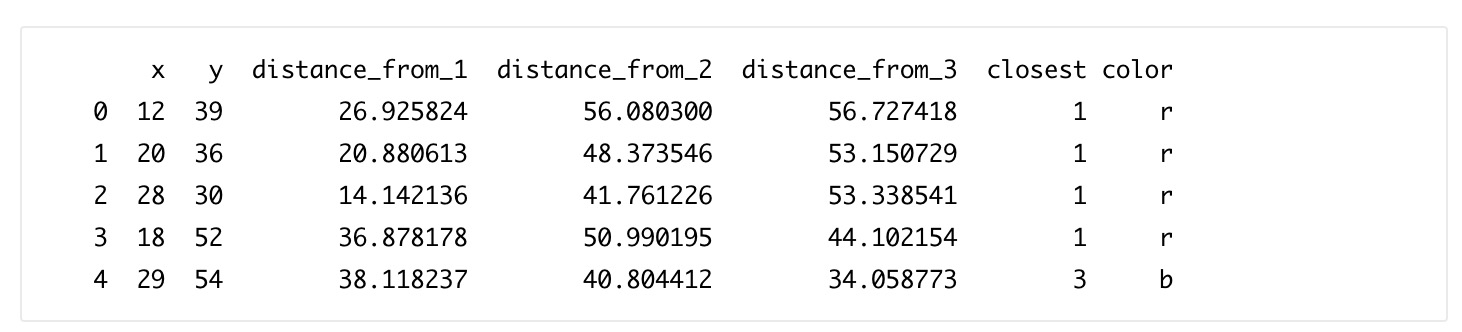
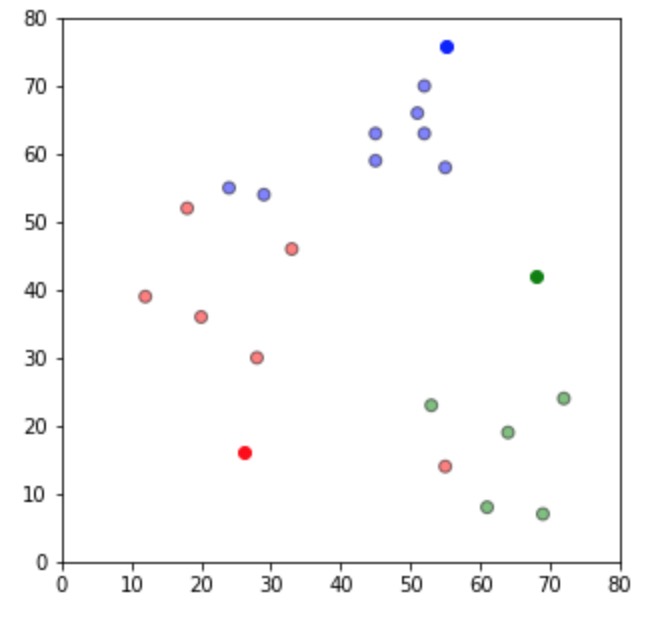
更新:

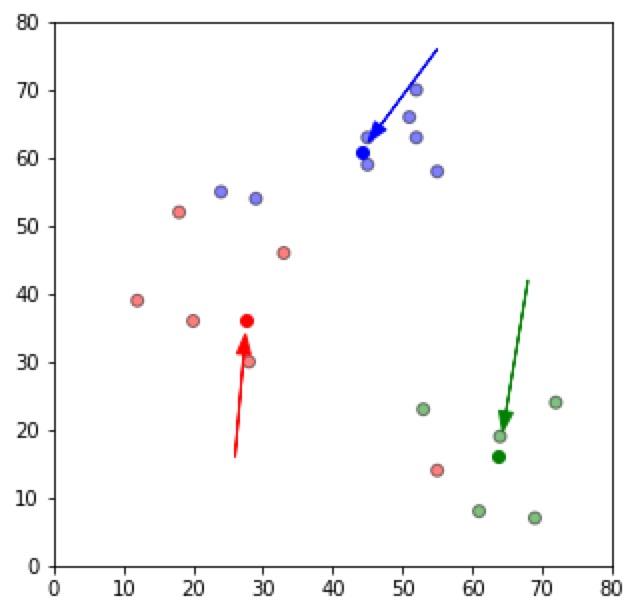
重新分配:

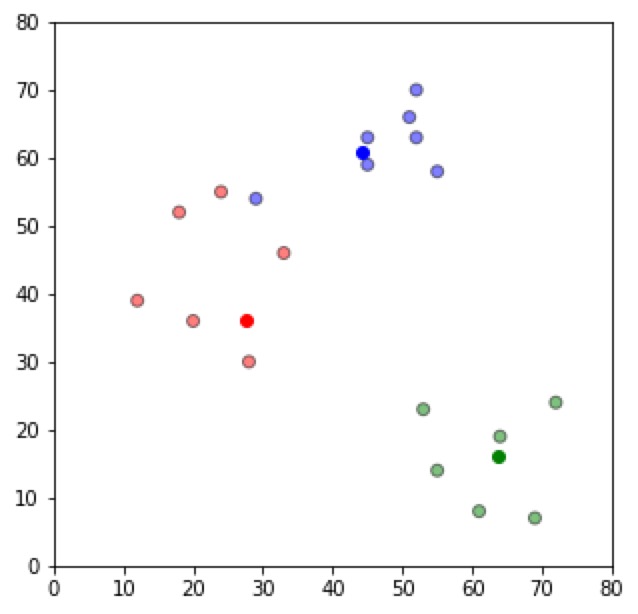
可以看到一个红色的点,变成了绿色的;一个蓝色的点变成了红色的。
我们更加接近最终目标了。
现在重复这个过程,直到每一个集群都没有变化为止。
继续这个过程:
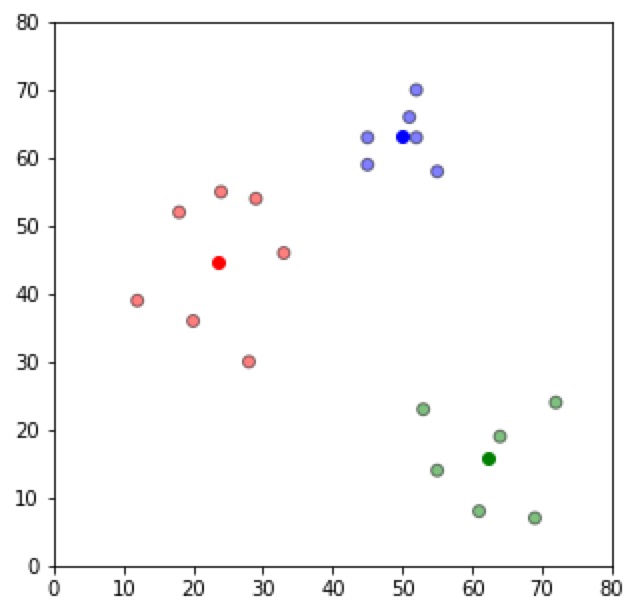
现在得到3个清晰地集群和3个质点在这三个集群的中间。
结论:
1.k-means 可以尝试不同的初始化质点来获取更好的 label.
2.如果数据集有一定的对称性,一些数据可能会被错误的标记。
3.k-means 依赖欧氏距离,所以对尺度非常敏感,所以如果存在缩放问题,要对数据进行归一化处理。