缓存的处理步骤
=================摘自《HTTP权威指南》=====================
现代的商业化代理缓存相当的复杂。这些缓存构建的非常有效,可以支持HTTP和其他一些技术的各种高级特性,但除了一些微妙的细节外,web缓存的基本工作原理大多很简单。对一条HTTP GET报文的基本缓存处理过程包括7个步骤(图7-11)
1、 接收—缓存从网络中读取抵达的请求报文;
2、 解析—缓存对报文进行解析,提取出URL和各种首部;
3、 查询—缓存查看是否有本地缓存可用,如果没有,就获取一份副本(并将其保存在本地);
4、 新鲜度检测—缓存查看已缓存的副本是否足够新鲜,如果不是,就询问服务器是否有任何更新;
5、 创建响应—缓存会用新的首部和已缓存的主体来构建一条响应报文;
6、 发送—缓存通过网络将响应回送给客户端;
7、 日志—缓存可选地创建一个日志文件条目来描述这个事务;

1、 第一步—接收
缓存检测到一条连接上的活动,读取输入数据。高性能的缓存会同时从多条输入连接上读取数据,在整条报文抵达之前开始对事务进行处理。
2、 第二部—解析
缓存将请求报文解析为片段,将首部的各个部分放入易于操作的数据结构中。这样缓存软件更容易处理首部字段并修改它们了。
3、 第三步—查找
缓存获取了URL,查找本地副本。本地副本可能存储在内存、本地磁盘,甚至附近的另一台计算机中。专业级的缓存会使用快速算法来确定本地缓存中是否有某个对象。如果本地没有这个文档,它可以根据情形和配置,到原始服务器或父代理中去取,或者返回一条错误信息。
已缓存对象中包含了服务器响应主体和原始服务器的响应首部,这样就会在缓存命中时返回正确的服务器首部。已缓存对象还包含了一些元数据(metadata),用来记录对象在缓存中停留了多长时间,以及它被用过了多少次等。
4、 第四步—新鲜度检测
HTTP通过缓存将服务器文档的副本保留一段时间。在这段时间里,都认为这份文档是“新鲜的”,缓存可以在不联系服务器的情况下,直接提供该文档。但一旦已缓存的副本停留的时间过长,超过了文档的新鲜度限制(freshness limit),就认为文档“过时”了,在提供该文档前,缓存要再次与服务器确认,以查看文档是否发生了变化。客户端发送给缓存的所有请求首部自身都可以强制缓存进行再验证,或者完全避免验证,这使得事情变得更加复杂了。
HTTP有一组非常复杂的新鲜度检测规则,缓存产品支持的大量配置选项,以及与非HTTP新鲜度标准进行互通的需要则使问题变得更严重了。
5、 第五步—创建响应
我们希望缓存的响应看起来就像来自原始服务器一样,缓存将已缓存的服务器响应首部作为响应首部的起点。然后缓存就对这些基础首部进行了修改和扩充。
缓存负责对这些首部进行改造,以便与客户端的要求相匹配。比如,服务器返回的可能是一条HTTP 1.0响应(甚至是HTTP 0.9响应),而客户端期待的是一条HTTP 1.1响应,在这种情况下,缓存必须对首部进行响应的转换。缓存还会向其中插入新鲜度信息(Cache-control、Age以及Expires首部),而且通常会包含一个Via首部来说明请求是由一个代理缓存提供的。
注意:缓存不应该调整Date首部。Date首部表示的是原始服务器最初产生这个对象的日期。
6、 第六步—发送
一旦响应首部准备好了,缓存就将响应回送给客户端。和所有代理服务器一样,代理缓存要管理与客户端之间的连接。高性能的缓存会尽力高效的发送数据,通常可以避免在本地缓存和网络I/O缓冲区之间进行文档内容的复制。
7、 日志
大多数缓存都会保存日志文件以及与缓存的使用有关的一些统计数据。每个缓存事务结束之后,缓存都会更新缓存命中和未命中数目的统计数据(以及其他相关的度量值)并将条目插入一个用来显示请求类型、URL和所发生时间的日志文件。
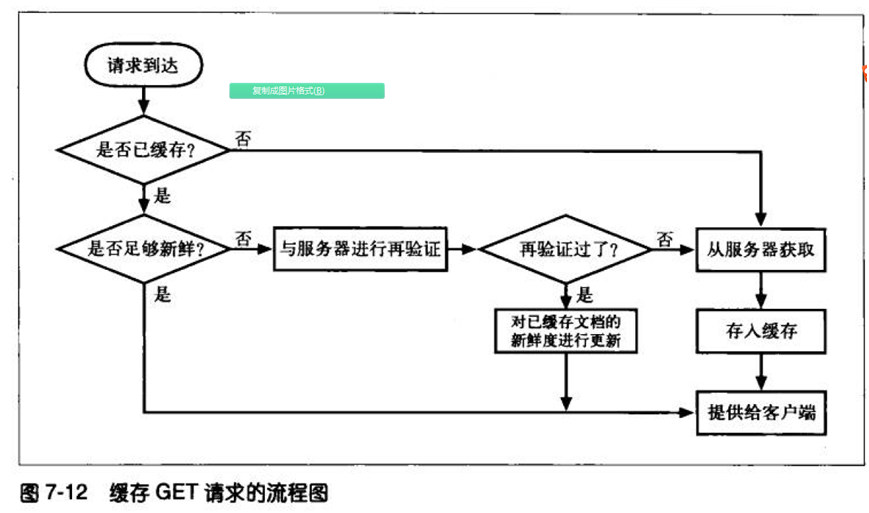
8、 缓存处理流程图
图7-12以简化的形式显示了缓存是如何处理请求以获取一个方法为GET的URL的。