概述
Velero(以前称为Heptio Ark)是一个开源工具,可以安全地备份和还原,执行灾难恢复以及迁移 Kubernetes 群集资源和持久卷,可以在 TKE 集群或自建 Kubernetes 集群中部署 Velero 用于:
- 备份集群并在丢失的情况下进行还原。
- 将集群资源迁移到其他集群。
- 将生产集群复制到开发和测试集群。
更多关于 Velero 介绍,请参阅 Velero 官网,本文将介绍使用 Velero 实现 TKE 集群间的无缝迁移复制集群资源的操作步骤。
迁移原理
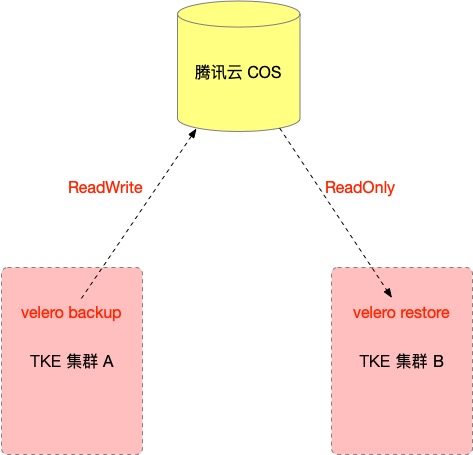
在需要被迁移的集群和目标集群上都安装 Velero 实例,并且两个集群的 Velero 实例指向相同的腾讯云 COS 对象存储位置,使用 Velero 在需要被迁移的集群执行备份操作生成备份数据存储到腾讯云 COS ,然后在目标集群上使用 Velero 执行数据的还原操作实现迁移,迁移原理如下:
前提条件
- 已 注册腾讯云账户。
- 已开通腾讯云 COS 服务。
- 已有需要被迁移的 TKE 集群(以下称作集群 A),已创建迁移目标的 TKE 集群(以下称作集群 B),创建 TKE 集群请参阅 创建集群。
- 集群 A 和 集群 B 都需要安装 Velero 实例(1.5版本以上),并且共用同一个腾讯云 COS 存储桶作为 Velero 后端存储,安装步骤请参阅 配置存储和安装 Velero 。
注意事项
-
从 1.5 版本开始,Velero 可以使用 Restic 备份所有pod卷,而不必单独注释每个 pod。默认情况下,此功能允许用户使用 restic 备份所有 pod 卷,但以下卷情况除外:
- 挂载默认
Service Account Secret的卷 - 挂载的
hostPath类型卷 - 挂载 Kubernetes
secrets和configmaps的卷
本示例需要 Velero 1.5 以上版本且启用 restic 来备份持久卷数据,请确保在安装 Velero 阶段开启
--use-restic和--default-volumes-to-restic参数,安装步骤请参阅 配置存储和安装 Velero 。 - 挂载默认
-
在执行迁移过程中,请不要对两边集群资源做任何 CRUD 操作,以免在迁移过程中造成数据差异,最终导致迁移后的数据不一致。
-
尽量保证集群 B 和集群 A 工作节点的CPU、内存等规格配置相同或不要相差太大,以免出现迁移后的 Pods 因资源原因无法调度导致 Pending 的情况。
操作步骤
在集群 A 创建备份
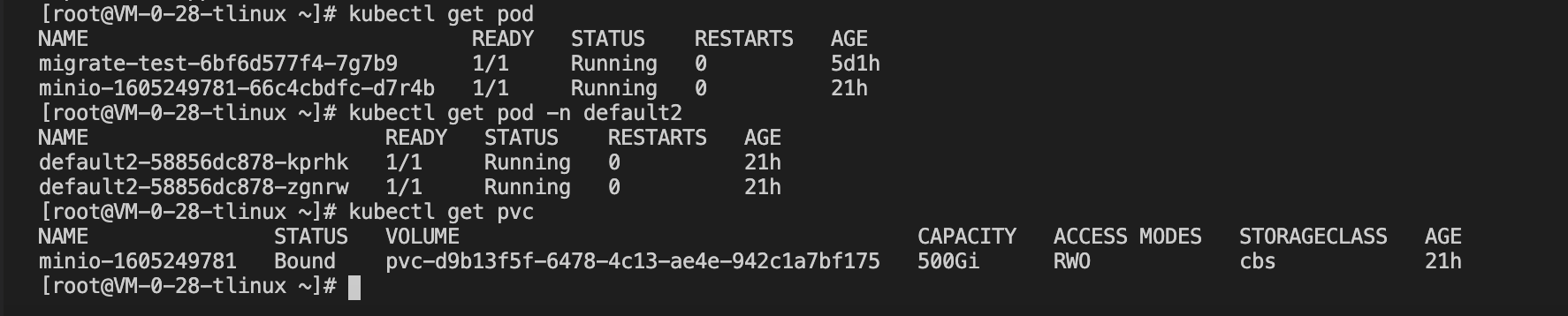
可以手动执行备份操作,也可以给 velero 设置定期自动备份,设置方法可以使用 velero schedule -h 查看。本示例将以 default 、default2 命名空间的资源情况作比较验证,下图可以看到集群 A 中两个命名空间下的 Pods 和 PVC 资源情况:
提示:可以指定在备份期间执行一些自定义 Hook 操作。比如,需要在备份之前将运行应用程序的内存中的数据持久化到磁盘。 有关备份 Hook 的更多信息请参阅 备份 Hook 。
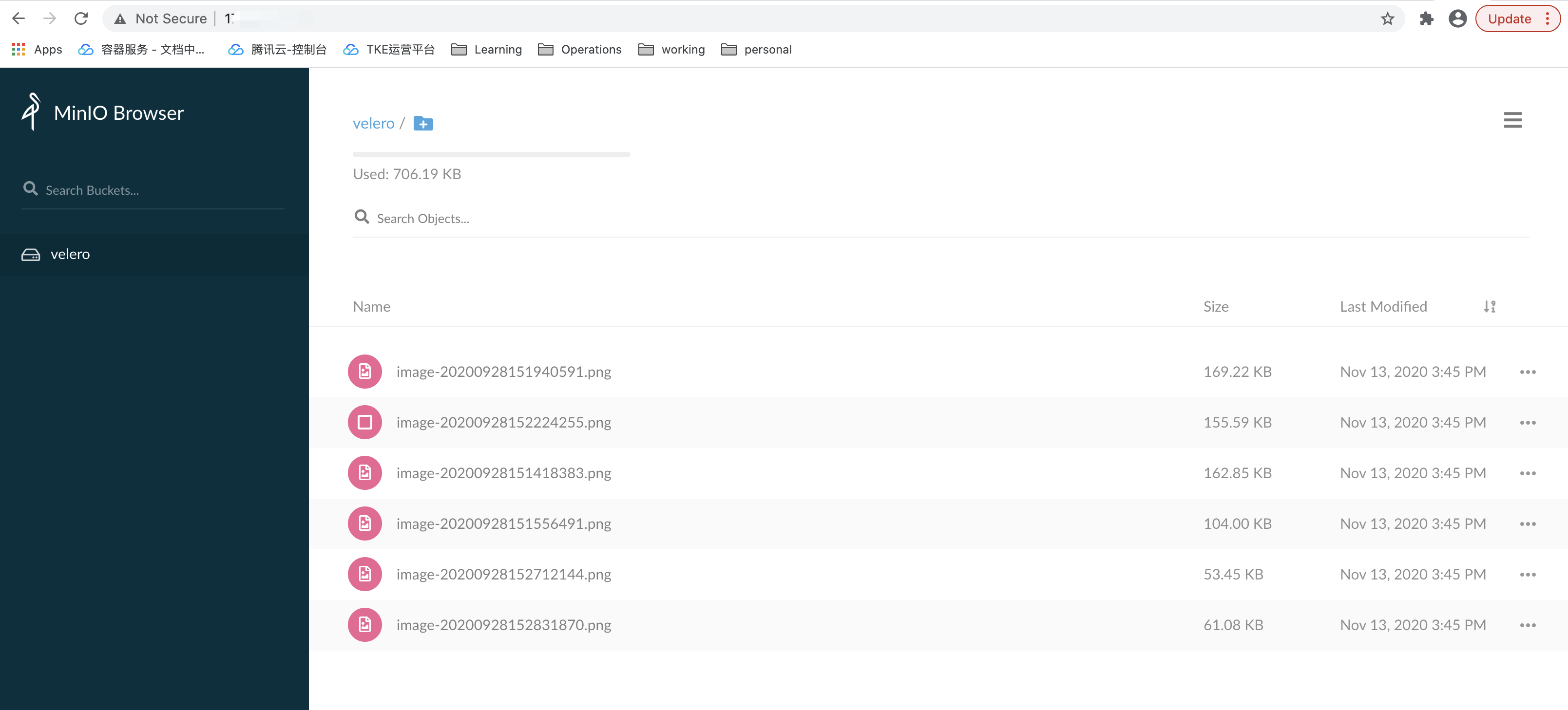
其中,集群中的 minio 对象存储服务使用了持久卷,并且已经上传了一些图片数据,如下图所示:
执行下面命令来备份集群中不包含 velero 命名空间(velero 安装的默认命名空间)资源的其他所有资源,如果想自定义需要备份的集群资源范围,可使用 velero create backup -h 查看支持的资源筛选参数。
velero backup create <BACKUP-NAME> --exclude-namespaces <NAMESPACE>
本示例我们创建一个 “default-all” 的集群备份,备份过程如下图所示:

备份任务状态显示是 “Completed” 时,说明备份任务完成,可以通过 velero backup logs | grep error 命令检查是否有备份操作发生错误,没有输出则说明备份过程无错误发生,如下图所示:
注意:请确保备份过程未发生任何错误,假如 velero 在执行备份过程中发生错误,请排查解决后重新执行备份。

备份完成后,临时将备份存储位置更新为只读模式(非必须,这可以防止在还原过程中 Velero 在备份存储位置中创建或删除备份对象):
kubectl patch backupstoragelocation default --namespace velero
--type merge
--patch '{"spec":{"accessMode":"ReadOnly"}}'
在集群 B 执行还原
在执行还原操作前集群 B 中 default 、default2 命名空间下没有任何工作负载资源,查看结果如下图:

临时将集群 B 中 Velero 备份存储位置也更新为只读模式(非必须,这可以防止在还原过程中 Velero 在备份存储位置中创建或删除备份对象):
kubectl patch backupstoragelocation default --namespace velero
--type merge
--patch '{"spec":{"accessMode":"ReadOnly"}}'
提示:可以选择指定在还原期间或还原资源后执行自定义 Hook 操作。例如,可能需要在数据库应用程序容器启动之前执行自定义数据库还原操作。 有关还原 Hook 的更多信息请参阅 还原 Hook。
在还原操作之前,需确保集群 B 中 的 Velero 资源与云存储中的备份文件同步。默认同步间隔是1分钟,可以使用--backup-sync-period 来配置同步间隔。可以使用下面命令查看集群 A 的备份是否已同步:
velero backup get <BACKUP-NAME>
获取备份成功检查无误后,执行下面命令还原所有内容到集群 B 中:
velero restore create --from-backup <BACKUP-NAME>
本示例执行还原过程如下图:

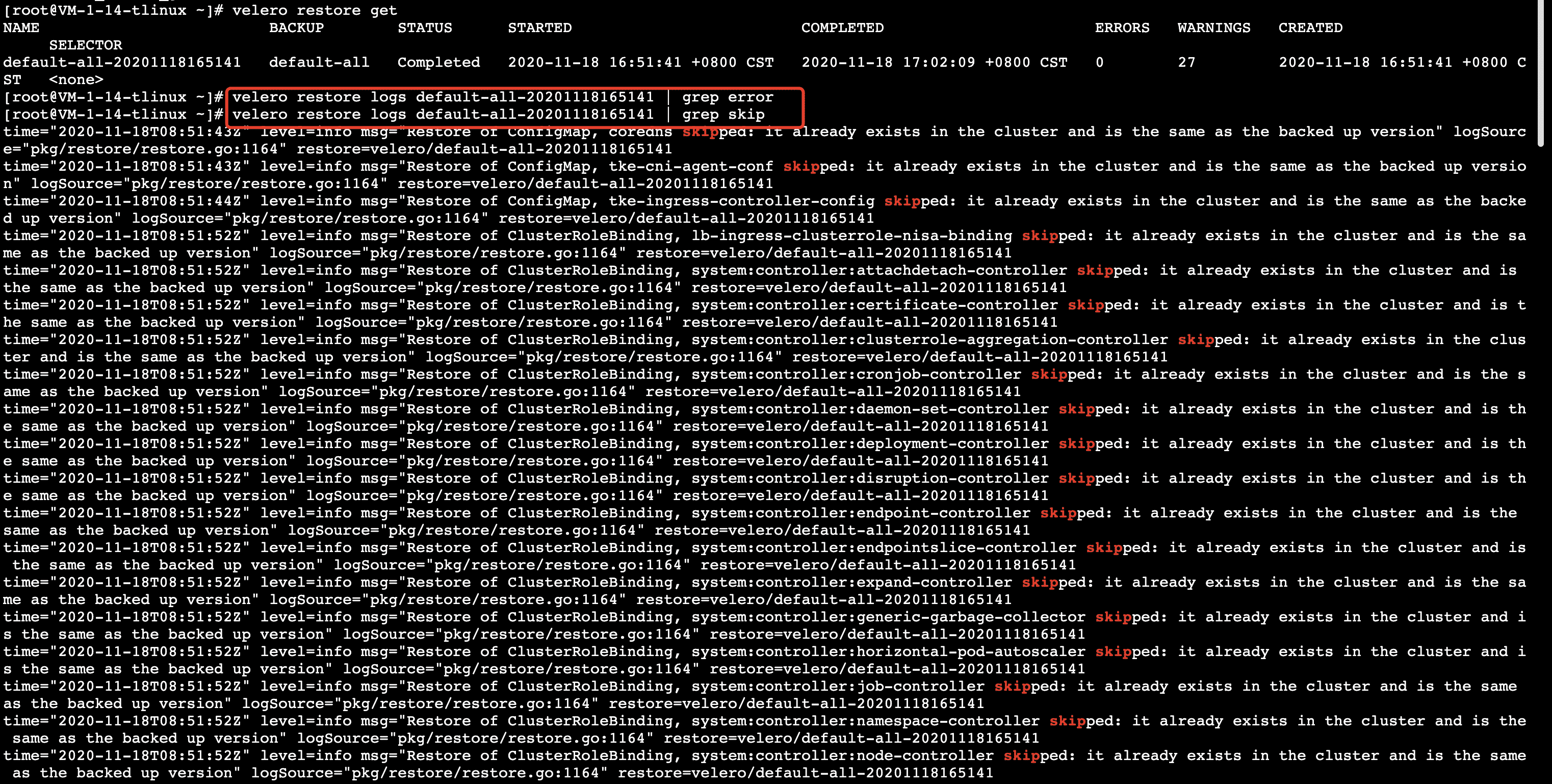
等待还原任务完成后查看还原日志, 可以使用下面命令查看还原是否有报错和跳过信息:
# 查看迁移时是否有错误的还原信息
velero restore logs <BACKUP-NAME> | grep error
# 查看迁移时跳过的还原操作
velero restore logs <BACKUP-NAME> | grep skip
从下图可以看出没有发生错误的还原步骤,但是有很多 “skipped” 步骤,是因为我们在备份集群资源时备份了不包含 velero 命名空间的所有集群资源,有一些同类型同名的集群资源已经存在了,如 kube-system下的集群资源,当还原过程中有资源冲突时,velero 会跳过还原的操作步骤。所以实际上还原过程是正常的,可以忽略这些 “skipped” 日志,假如有特殊情况可以分析下日志看看。
迁移结果核验
查看校验集群 B 执行迁移操作后的集群资源,可以看到 default 、default2 命名空间下的 pods 和 PVC 资源已按预期迁移成功:

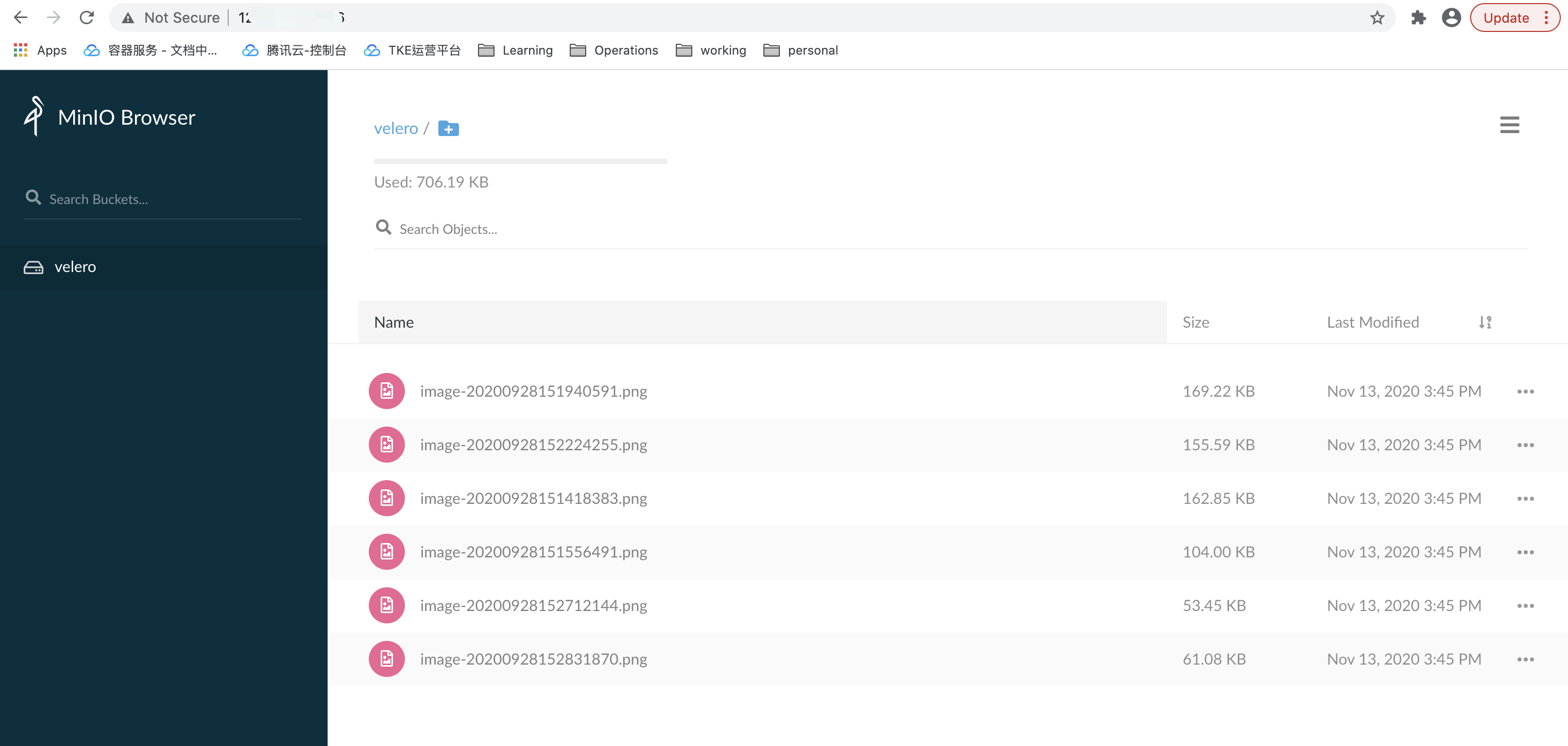
再通过 Web 管理页面登录集群 B 中的 monio 服务,可以看到 minio 服务中的图片数据没有丢失,说明持久卷数据也已按预期迁移成功。
至此,我们完成了 TKE 集群间资源的迁移,迁移操作完成后,请不要忘记把备份存储位置恢复为读写模式(集群 A 和 集群B),以便下次备份任务可以成功使用:
kubectl patch backupstoragelocation default --namespace velero
--type merge
--patch '{"spec":{"accessMode":"ReadWrite"}}'
总结
本文主要介绍了在 TKE 集群间使用 Velero 迁移集群资源的原理、注意事项和操作方法,成功的将示例集群 A 中的集群资源无缝迁移到集群 B 中,整个迁移过程非常简单方便,是一种非常友好的集群资源迁移方案。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!
