http://blog.csdn.net/yerenyuan_pku/article/details/72944611
本文我只是简单介绍一下SolrCloud,如果大家要是感兴趣的话,可以参考SolrCloud之分布式索引及与Zookeeper的集成这篇文章进行学习哟!
SolrCloud的概述
Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库;Solr是以Lucene为基础实现的文本检索应用服务;SolrCloud是Solr4.0版本开发出的具有开创意义的基于Solr和Zookeeper的分布式搜索方案,主要思想是使用Zookeeper作为集群的配置信息中心。也可以说,SolrCloud是Solr的一种部署方式,除SolrCloud之外,Solr还可以以单机方式和多机Master-Slaver方式进行部署。分布式索引是指当索引越来越大,一个单一的系统无法满足磁盘需求的时候,或者一次简单的查询实在要耗费很多时间的时候,我们就可以使用Solr的分布式索引了。在分布式索引中,原来的大索引,将会分成多个小索引,Solr可以将这些小索引返回的结果合并,然后返回给客户端。
对此,我个人对SolrCloud的理解是:SolrCloud(Solr云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时可使用SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高的时候,这时就需要使用SolrCloud来满足这些需求。SolrCloud是基于Solr和Zookeeper(来管理Solr集群的)的分布式搜索方案,它的主要思想是使用Zookeeper作为集群的配置信息中心。Zookeeper有以下几个特色功能:
- 集中式的配置信息。
- 自动容错。
- 近实时搜索。
- 查询时自动负载均衡。
SolrCloud中完整索引(Collection)的逻辑图
SolrCloud中完整索引(Collection)的逻辑图如下图所示。 
在SolrCloud模式下Collection是访问Cluster的入口,这个入口有什么用呢?比如说集群里面有好多台机器,那么访问这个集群通过哪个地址呢,必须有一个接口地址,Collection就是这个接口地址。可见Collection是一个逻辑存在的东西,因此是可以跨Node的,在任意节点上都可以访问Collection。Shard其实也是逻辑存在的,因此Shard也是可以跨Node的;1个Shard下面可以包含0个或者多个Replica,但1个Shard下面能且只能包含一个Leader,如果Shard下面的Leader挂掉了,会从Replica里面再选举一个Leader。
SolrCloud的工作模式
首先来看下索引和Solr实体对照图。 
SolrCloud中包含有多个Solr Instance,而每个Solr Instance中包含有多个Solr Core,Solr Core对应着一个可访问的Solr索引资源,每个Solr Core对应着一个Replica或者Leader,这样,当Solr Client通过Collection访问Solr集群的时候,便可通过Shard分片找到对应的Replica即SolrCore,从而就可以访问索引文档了。
在SolrCloud模式下,同一个集群里所有Core的配置是统一的,Core有Leader和Replica两种角色,每个Core一定属于一个Shard,Core在Shard中扮演Leader还是Replica由Solr内部Zookeeper自动协调。
访问SolrCloud的过程:Solr Client向Zookeeper咨询Collection的地址,Zookeeper返回存活的节点地址供访问,插入数据的时候由SolrCloud内部协调数据分发(内部使用一致性哈希)。
Solr集群的系统架构
Solr集群的系统架构如下图所示。 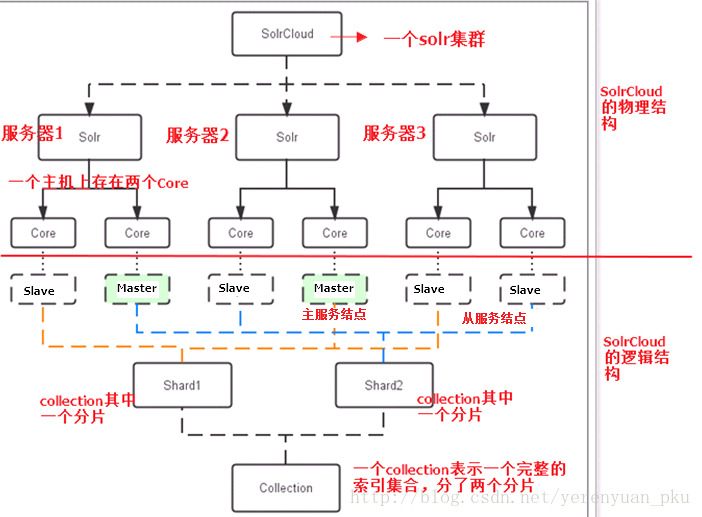
下面我稍微分析一下SolrCloud的物理结构和逻辑结构。
物理结构
三个Solr实例( 每个实例包括两个Core),组成一个SolrCloud。
逻辑结构
索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replica,Leader是由zookeeper选举产生,zookeeper控制每个shard上三个Core的索引数据一致,解决高可用问题。用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
collection
Collection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。比如:针对商品信息搜索可以创建一个collection,collection=shard1+shard2+….+shardX。
Core
每个Core是Solr中一个独立运行单位,提供索引和搜索服务。一个shard需要由一个Core或多个Core组成。由于collection由多个shard组成,所以collection一般由多个core组成。
Master或Slave
Master是master-slave结构中的主结点(通常说主服务器),Slave是master-slave结构中的从结点(通常说从服务器或备服务器)。同一个Shard下master和slave存储的数据是一致的,这是为了达到高可用目的。
Shard
Collection的逻辑分片,每个Shard被化成一个或者多个Replica,通过选举确定哪个是Leader