在LeetCode上刷一道题,题目如下:
3. 无重复字符的最长子串
给定一个字符串,请你找出其中不含有重复字符的?最长子串?的长度。
示例?1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是?"wke",所以其长度为 3。
?
请注意,你的答案必须是 子串 的长度,"pwke"?是一个子序列,不是子串。
我想到,如果忽略重复的情况,纯对无符号字符串进行分词,是怎么做的?
考虑了一下,思路比较简单:
先从单个字符开始,统计词频,然后对词频大于1的进行扩展,扩展处理的词长为2的,再统计词频,然后如此类推,一致推到所有的最高长度词都词频为1了,才结束。
如图所示:
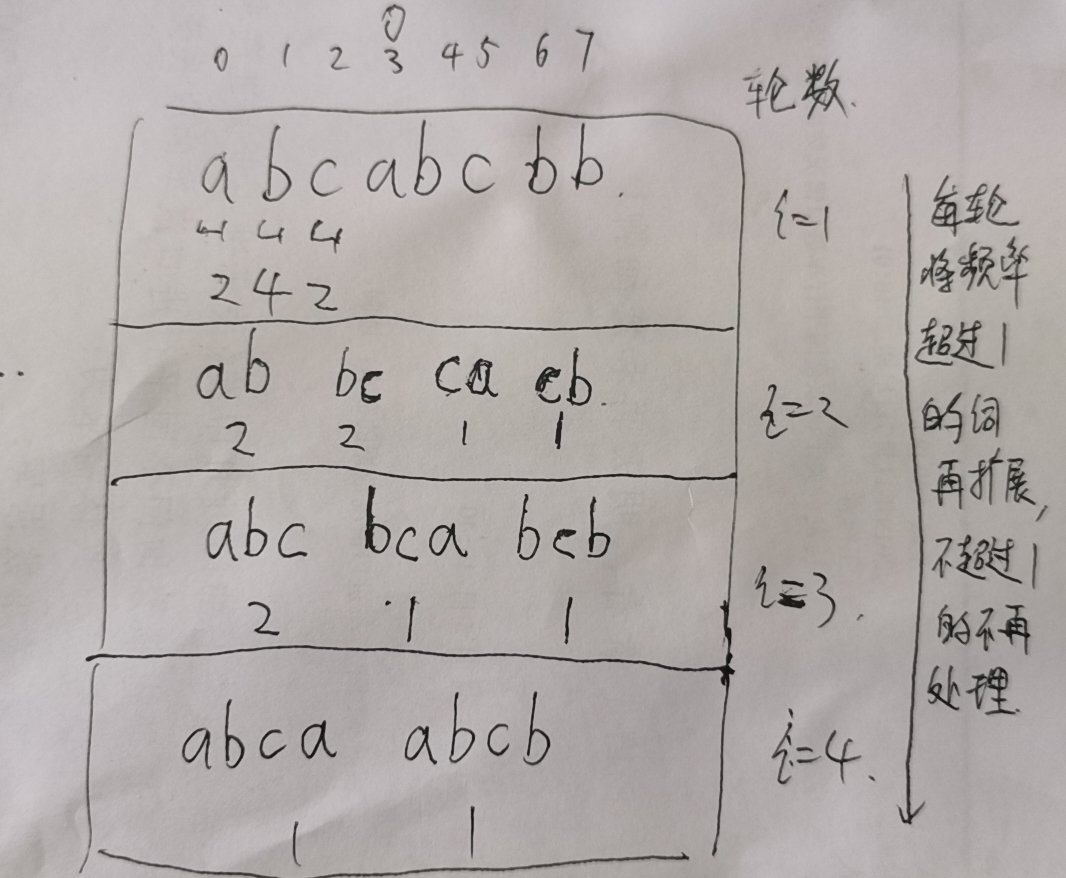
最终代码如下:
#该函数为,i为扩充出的词的长度,i=2,就是ab,bc,de这种两个长度的词; #然后在sc中找值不为1的键值对,检查长度为i的键在s中出现后续词的数量,并插入到sc字典中 #返回此层结果的最大词频 def fillSc(sc:dict,s:list,i:int)->int: maxlens=0 #最大词频 if len(sc)==0: #如果sc字典为空,则开始把单字进行填充 for b in s: sc[b]= s.count(b) if s.count(b)>maxlens: #判断该词频率,如果频率是最高的,就保存下来 maxlens=s.count(b) else: #否则在sc字典中找到词长为i的词,进行探索 for x in list(sc.keys()): if len(x)!=i: #如果为词长与预设不符,则不再继续,而是跳过 continue else: m=int(sc[x]) #m为词x出现的次数 if m>1:#词频为1的,不再处理,只处理词频高于1的 n=0 #取词的位置 for k in range(0,m,1): if s.index(x,n,)+len(x)<len(s)-1: #判断是否到了s字符串的结尾 x1=x+s[s.index(x,n,)+len(x)] #形成后续词,即x为ab时,取abc,如果存在多个ab,则接连取 n=s.index(x,n,)+len(x)#后续词出现的位置 sc[x1]=s.count(x1)#补充进sc列表 if s.count(x1)>maxlens: #判断该词频率,如果频率是最高的,就保存下来 maxlens=s.count(x1) return maxlens s="abcabcbb" #原始字符串 sc={} #空字典,用于存储分出来的词和词频 i=0 #当前层数,也就是当前词的长度,例如a是1,ab是2,abc是3 maxl=2 #最大词频数,初始值设置为2,是为了避免while循环不启动 while maxl>1: maxl=fillSc(sc,s,i) i=i+1 for x in list(sc.keys()): #将sc字典中的全部输出 print(x,",",sc[x])
输出结果如下:
a , 2 b , 4 c , 2 ab , 2 bc , 2 ca , 1 cb , 1 abc , 2 bca , 1 bcb , 1 abca , 1 abcb , 1
心得体会如下:
1、对python的语法和方法还是不熟悉,导致了非常大的麻烦,经过这个例子,对字典的理解更深入了,虽然感觉不如c#的对应类型好用。
2、代码编辑器很麻烦,开始用vscode怎么也配置不上,重装了后,没有自动代码提示,也没有代码颜色高亮等,等再配置完了,这些有了,但代码执行不起来了,提示有空行在核心代码库里面。最后只能重装了anaconda3,直接用spyder来写,调试和代码执行也很麻烦。如果用vs和c#来写,估计连四分之一的时间都用不了。