一.不使用spark
1 package cn.scala_base.collection
2 import scala.io.Source.fromFile;
3 import scala.io.Source
4 import scala.collection.mutable.Map
5
6 /**
7 * 借助scala实现wordcount
8 */
9 object WordCount {
10 val wordMap = Map[String, Int]();
11
12 def putMap(tuple: Tuple2[Array[String], Int]) {
13 val arr = tuple._1;
14 for (x <- arr) {
15 if (wordMap.contains(x)) {
16 var count = wordMap(x).toInt + 1;
17 wordMap(x) = count;
18 } else {
19 wordMap += (x -> 1);
20 }
21 }
22
23 }
24
25 def putMap2(tuple: Tuple2[String, Int]) {
26 val str = tuple._1;
27 if (wordMap.contains(str)) {
28 var count = wordMap(str).toInt + 1;
29 wordMap(str) = count;
30 } else {
31 wordMap += (str -> 1);
32 }
33
34 }
35
36 def main(args: Array[String]): Unit = {
37
38 //读取文本
39 val text1 = Source.fromFile("D:/inputword/hello.txt", "gbk").getLines();
40 val text2 = Source.fromFile("D:/inputword/one.txt", "gbk").getLines();
41 val text3 = Source.fromFile("D:/inputword/two.txt", "gbk").getLines();
42
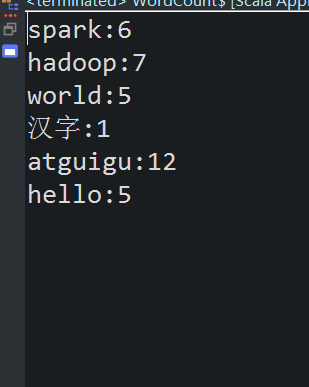
43 /**
44 * 单词总数;35
45 * atguigu 12
46 * hadoop 7
47 * hello 5
48 * spark 6
49 * world 5
50 *
51 */
52
53 /* //统计每个文件的总单词数
54 val res1 = List(text1,text2,text3).map(_.map(_.mkString).flatMap(_.split(" ")).map((_,1)).map(_._2).reduceLeft(_+_));
55 println(res1);//List(18, 10, 7)*/
56
57 //精确统计三个文件中每个单词出现的总次数
58
59 //如果数据源是iternator,最后一步应该使用foreach对元素进行操作
60 val res = List(text1, text2, text3).map(_.map(_.split(" ")).map((_, 1)).foreach(putMap(_)));
61
62 //或者 flatMap把切割后的数组中的元素取出,变成单个的字符串
63 // val res = List(text1,text2,text3).map(_.flatMap(_.split(" ")).map((_,1)).foreach(putMap2(_)) )
64
65 //遍历
66 for (key <- wordMap.keySet) {
67 println(key + ":" + wordMap(key));
68 }
69
70 }
71
72 }
二.在spark集群上运行wordcount
新建一个maven工程
pom.xml
1 <dependencies>
2 <dependency>
3 <groupId>junit</groupId>
4 <artifactId>junit</artifactId>
5 <version>4.9</version>
6 </dependency>
7
8 <dependency>
9 <groupId>org.apache.spark</groupId>
10 <artifactId>spark-core_2.11</artifactId>
11 <version>2.0.2</version>
12 </dependency>
13
14 <dependency>
15 <groupId>org.apache.spark</groupId>
16 <artifactId>spark-sql_2.11</artifactId>
17 <version>2.0.2</version>
18 </dependency>
19
20 <dependency>
21 <groupId>org.apache.spark</groupId>
22 <artifactId>spark-hive_2.11</artifactId>
23 <version>2.0.2</version>
24 <scope>provided</scope>
25 </dependency>
26
27 <dependency>
28 <groupId>io.hops</groupId>
29 <artifactId>hadoop-client</artifactId>
30 <version>2.7.3</version>
31 <scope>provided</scope>
32 </dependency>
33 </dependencies>
34
35 <build>
36 <plugins>
37 <plugin>
38 <groupId>org.scala-tools</groupId>
39 <artifactId>maven-scala-plugin</artifactId>
40 <version>2.15.2</version>
41 <executions>
42 <execution>
43 <goals>
44 <goal>compile</goal>
45 <goal>testCompile</goal>
46 </goals>
47 </execution>
48 </executions>
49 </plugin>
50 </plugins>
51 </build>
1 object WordCountCluster {
2 def main(args: Array[String]): Unit = {
3
4 val conf = new SparkConf().setAppName("WordCountCluster");
5
6 val sc = new SparkContext(conf);
7
8 val lines = sc.textFile("hdfs://hadoop002:9000/word.txt",1);
9
10 //切割
11 val fields = lines.flatMap(_.split(" "));
12
13 //映射成元组
14 val wordTuple = fields.map((_,1));
15
16 //统计
17 val result = wordTuple.reduceByKey(_+_);
18 result.foreach(r => println(r._1+":"+r._2));
19
20 }
21 }
导出jar并上传,同时上传word.txt到hdfs上
编写scalawordcount.sh
1 /opt/module/spark-2.0.2-bin-hadoop2.7/bin/spark-submit
2 --class spark_base.wordcount.WordCountCluster
3 --num-executors 3
4 --driver-memory 800m
5 --executor-memory 1000m
6 --executor-cores 3
7 /opt/module/spark-test/scala/scala-wc.jar
chmod 777 scalawordcount.sh
./scalawordcount.sh