【Game Engine Architecture 7】
1、SRT Transformations
When a quaternion is combined with a translation vector and a scale factor (either a scalar for uniform scaling or a vector for nonuniform scaling), then we have a viable alternative to the 4 x 4 matrix representation of affine transformations. We sometimes call this an SRT transform.

2、Dual Quaternions
A rigid transformation is a transformation involving a rotation and a translation.
A dual quaternion is like an ordinary quaternion, except that its four components are dual numbers instead of regular real-valued numbers. A dual number can be written as the sum of a non-dual part and a dual part as follows: ˆa = a + e^b. Here e is a magical number called the dual unit, defined in such a way that e^2 = 0 (yet without e itself being zero). This is analogous to the imaginary number.
3、Rotations and Degrees of Freedom(DOF)
"six degrees of freedom" This refers to the fact that a three-dimensional object (whose motion is not artificially constrained) has three degrees of freedom in its translation (along the x-, y- and z-axes) and three degrees of freedom in its rotation (about the x-, y- and z-axes), for a total of six degrees.
4、Plances
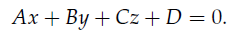
plane normal. If the vector [A B C ] is normalized to unit length, then the normalized vector [a b c]= n, and the normalized parameter d = D/ sqrt(A2 + B2 + C2) is just the distance from the plane to the origin. The sign of d is positive if the plane’s normal vector n is pointing toward the origin (i.e., the origin is on the “front” side of the plane) and negative if the normal is pointing away from the origin.
we need only the normal vector n = [ a b c ] and the distance from the origin d. The four-element vector L = [ n d ] = [ a b c d ] is a compact and convenient way to represent and store a plane in memory. Note that when P is written in homogeneous coordinates with w = 1, the equation (L P) = 0 is yet another way of writing (n P) = -d. These equations are satisfied for all points P that lie on the plane L.
5、Axis-Aligned Bounding Boxes (AABB)
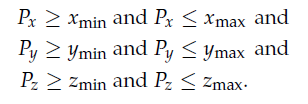
6、Oriented Bounding Boxes (OBB)
testing whether or not a point lies within an OBB, but one common approach is to transform the point into the OBB’s “aligned” coordinate system and then use an AABB intersection test as presented above.
7、Frusta
Testing whether a point lies inside a frustum is a bit involved, but the basic idea is to use dot products to determine whether the point lies on the front or back side of each plane. If it lies inside all six planes, it is inside the frustum.
A helpful trick is to transform the world-space point being tested by applying the camera’s perspective projection to it. This takes the point from world space into a space known as homogeneous clip space. In this space, the frustum is just an axis-aligned cuboid (AABB). This permits much simpler in/out tests to be performed.
8、Random Number Generation
random number generators don’t actually generate random numbers— they merely produce a complex, but totally deterministic, predefined sequence of values. For this reason, we call the sequences they produce pseudorandom, and technically speaking we should really call them “pseudorandom number generators” (PRNG). What differentiates a good generator from a bad one is how long the sequence of numbers is before it repeats (its period), and how well the sequences hold up under various well-known randomness tests.
9、Linear Congruential Generators
this algorithm is sometimes used in the C standard library’s rand() function.
The numbers produced do not meet many of the criteria widely accepted as desirable, such as a long period, low- and high-order bits that have similarly long periods
10、Mersenne Twister
It was designed to have a colossal period of 2^19937-1 = 4.3 x 10^6001. It is fast.
Various implementations of the Twister are available on the web, including a particularly cool one that uses SIMD vector instructions for an extra speed boost, called SFMT (SIMD-oriented fast Mersenne Twister).
11、C++ Static Initialization Order
In C++, global and static objects are constructed before the program’s entry point. However, these constructors are called in a totally unpredictable order. The destructors of global and static class instances are called after main() and once again they are called in an unpredictable order.
所以全局单例模式,在C++中不合适。如下:

12、Construct On Demand
A static variable that is declared within a function will not be constructed before main() is called, but rather on the first invocation of that function. So if our global singleton is function-static, we can control the order of construction for our global
singletons.


class RenderManager { public: // Get the one and only instance. static RenderManager& get() { // This function-static will be constructed on the // first call to this function. static RenderManager sSingleton; return sSingleton; } RenderManager() { // Start up other managers we depend on, by // calling their get() functions first... VideoManager::get(); TextureManager::get(); // Now start up the render manager. // ... } ~RenderManager() { // Shut down the manager. // ... } };
Unfortunately, this still gives us no way to control destruction order.
13、A Simple Approach That Works
the simplest “brute-force” approach is to define explicit start-up and shut-down functions for each singleton manager class. These functions take the place of the constructor and destructor, and in fact we should arrange for the constructor and destructor to do absolutely nothing. That way, the start-up and shut-down functions can be explicitly called in the required order from within main()
把 constructor、destructor 的功能移到 startup、shutdown 中。由 main函数来依次调用,从而解决order问题。
class RenderManager { public: RenderManager(){ // do nothing } ~RenderManager(){ // do nothing } void startUp() { // start up the manager... } void shutDown() { // shut down the manager... } // ... }; class PhysicsManager { /* similar... */ }; class AnimationManager { /* similar... */ }; class MemoryManager { /* similar... */ }; class FileSystemManager { /* similar... */ }; // ... RenderManager gRenderManager; PhysicsManager gPhysicsManager; AnimationManager gAnimationManager; TextureManager gTextureManager; VideoManager gVideoManager; MemoryManager gMemoryManager; FileSystemManager gFileSystemManager; // ... int main(int argc, const char* argv) { // Start up engine systems in the correct order. gMemoryManager.startUp(); gFileSystemManager.startUp(); gVideoManager.startUp(); gTextureManager.startUp(); gRenderManager.startUp(); gAnimationManager.startUp(); gPhysicsManager.startUp(); // ... // Run the game. gSimulationManager.run(); // Shut everything down, in reverse order. // ... gPhysicsManager.shutDown(); gAnimationManager.shutDown(); gRenderManager.shutDown(); gFileSystemManager.shutDown(); gMemoryManager.shutDown(); return 0; }
OGRE 采用的是这种方式,在 OgreRoot 中依次创建。
Naughty Dog’s Uncharted and The Last of Us Series,也采用类似的方法。
14、Memory Management
Memory affects performance in two ways:
1)Dynamic memory allocation, via malloc() or C++’s global operator new is a very slow operation. We can improve the performance of our code by either avoiding dynamic allocation altogether or by making use of custom memory allocators that greatly reduce allocation costs.
malloc() 很慢。
2)memory access pattern.
15、Optimizing Dynamic Memory Allocation
malloc() or free() must first context switch from user mode into kernel mode, process the request and then contextswitch back to the program. These context switches can be extraordinarily expensive.
malloc() 有 context switch,导致开销很大。
a custom allocator can satisfy requests from a preallocated memory block (itself allocated using malloc()). This allows it to run in user mode and entirely avoid the cost of context-switching into the operating system.
预 allocate,使得 context switch 被避免。
16、Stack-Based Allocators
We simply allocate a large contiguous block of memory using malloc() or global new, or by declaring a global array of bytes (in which case the memory is effectively allocated out of the executable’s BSS segment).
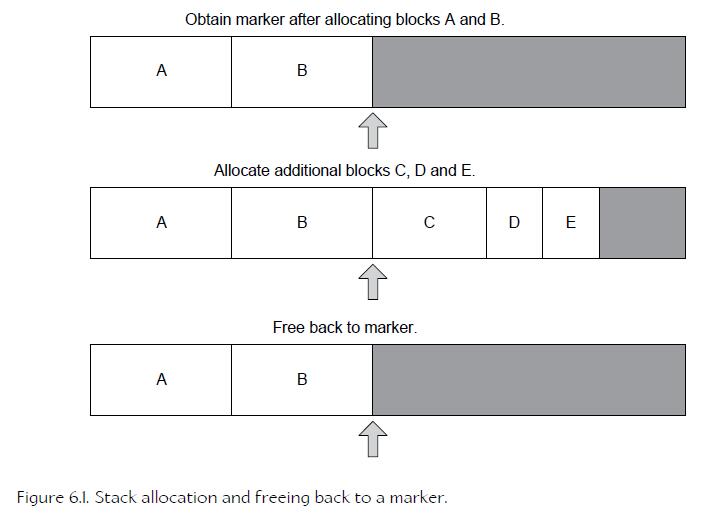
下面是 StackAllocator 的声明:
class StackAllocator { public: // Stack marker: Represents the current top of the // stack. You can only roll back to a marker, not to // arbitrary locations within the stack. typedef U32 Marker; // Constructs a stack allocator with the given total // size. explicit StackAllocator(U32 stackSize_bytes); // Allocates a new block of the given size from stack // top. void* alloc(U32 size_bytes); // Returns a marker to the current stack top. Marker getMarker(); // Rolls the stack back to a previous marker. void freeToMarker(Marker marker); // Clears the entire stack (rolls the stack back to // zero). void clear(); private: // ... };
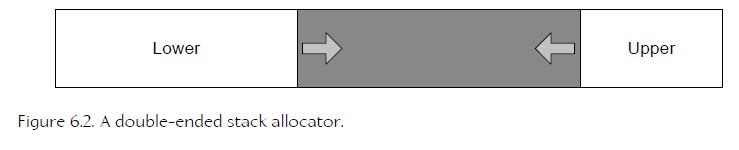
17、Double-Ended Stack Allocators
The bottom stack is used for loading and unloading levels (race tracks), while the top stack is used for temporary memory blocks that are allocated and freed every frame. This allocation scheme worked extremely well and ensured that Hydro Thunder never suffered from memory fragmentation problems.
18、Pool Allocator
A pool allocator works by preallocating a large block of memory whose size is an exact multiple of the size of the elements that will be allocated.
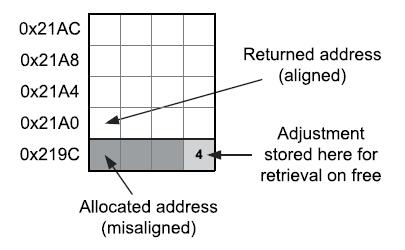
19、Aligned Allocations
All memory allocators must be capable of returning aligned memory blocks. This is relatively straightforward to implement. We simply allocate a little bit more memory than was actually requested, shift the address of the memory block upward slightly so that it is aligned properly, and then return the shifted address.
In most implementations, the number of additional bytes allocated is equal to the alignment minus one.
下面是获取对齐地址的实现:
// Shift the given address upwards if/as necessary to // ensure it is aligned to the given number of bytes. inline uintptr_t AlignAddress(uintptr_t addr, size_t align) { const size_t mask = align - 1; assert((align & mask) == 0); // pwr of 2 return (addr + mask) & ~mask; } // Shift the given pointer upwards if/as necessary to // ensure it is aligned to the given number of bytes. template<typename T> inline T* AlignPointer(T* ptr, size_t align) { const uintptr_t addr = reinterpret_cast<uintptr_t>(ptr); const uintptr_t addrAligned = AlignAddress(addr, align); return reinterpret_cast<T*>(addrAligned); } // Aligned allocation function. IMPORTANT: 'align' // must be a power of 2 (typically 4, 8 or 16). void* AllocAligned(size_t bytes, size_t align) { // Determine worst case number of bytes we'll need. size_t worstCaseBytes = bytes + align - 1; // Allocate unaligned block. U8* pRawMem = new U8[worstCaseBytes]; // Align the block. return AlignPointer(pRawMem, align); }
20、Freeing Aligned block
The smallest shift we’ll ever make is one byte, so that’s the minimum space we’ll have to store the offset.
// Aligned allocation function. IMPORTANT: 'align' // must be a power of 2 (typically 4, 8 or 16). void* AllocAligned(size_t bytes, size_t align) { // Allocate 'align' more bytes than we need. size_t actualBytes = bytes + align; // Allocate unaligned block. U8* pRawMem = new U8[actualBytes]; // Align the block. If no alignment occurred, // shift it up the full 'align' bytes so we // always have room to store the shift. U8* pAlignedMem = AlignPointer(pRawMem, align); if (pAlignedMem == pRawMem) pAlignedMem += align; // Determine the shift, and store it. // (This works for up to 256-byte alignment.) ptrdiff_t shift = pAlignedMem - pRawMem; assert(shift > 0 && shift <= 256); pAlignedMem[-1] = static_cast<U8>(shift & 0xFF); return pAlignedMem; } void FreeAligned(void* pMem) { if (pMem) { // Convert to U8 pointer. U8* pAlignedMem = reinterpret_cast<U8*>(pMem); // Extract the shift. ptrdiff_t shift = pAlignedMem[-1]; if (shift == 0) shift = 256; // Back up to the actual allocated address, // and array-delete it. U8* pRawMem = pAlignedMem - shift; delete[] pRawMem; } }
21、Single-Frame Allocators
the allocator will be cleared at the start of every frame.
StackAllocator g_singleFrameAllocator; // Main Game Loop while (true) { // Clear the single-frame allocator's buffer every // frame. g_singleFrameAllocator.clear(); // ... // Allocate from the single-frame buffer. We never // need to free this data! Just be sure to use it // only this frame. void* p = g_singleFrameAllocator.alloc(nBytes); // ... }
You need to realize that a memory block allocated out of the single-frame buffer will only be valid during the current frame. Programmers must never cache a pointer to a single-frame memory block across the frame boundary!
22、Double-Buffered Allocators
A double-buffered allocator allows a block of memory allocated on frame i to be used on frame (i +1). To accomplish this, we create two single-frame stack allocators of equal size and then ping-pong between them every frame.
class DoubleBufferedAllocator { U32 m_curStack; StackAllocator m_stack[2]; public: void swapBuffers() { m_curStack = (U32)!m_curStack; } void clearCurrentBuffer() { m_stack[m_curStack].clear(); } void* alloc(U32 nBytes) { return m_stack[m_curStack].alloc(nBytes); } // ... }; DoubleBufferedAllocator g_doubleBufAllocator; // Main Game Loop while (true) { // Clear the single-frame allocator every frame as // before. g_singleFrameAllocator.clear(); // Swap the active and inactive buffers of the double- // buffered allocator. g_doubleBufAllocator.swapBuffers(); // Now clear the newly active buffer, leaving last // frame's buffer intact. g_doubleBufAllocator.clearCurrentBuffer(); // ... // Allocate out of the current buffer, without // disturbing last frame's data. Only use this data // this frame or next frame. Again, this memory never // needs to be freed. void* p = g_doubleBufAllocator.alloc(nBytes); // ... }
This kind of allocator is extremely useful for caching the results of asynchronous processing on a multicore game console like the Xbox 360, Xbox One, PlayStation 3 or PlayStation 4.
23、Avoiding Fragmentation with Stack and Pool Allocators
A stack allocator is impervious to fragmentation because allocations are always contiguous:

Pool allocator,最小分配单位为 itemSize,从而不会产生内存碎片中的,因内存太小而分配失败的问题。

24、Defragmentation and Relocation
When differently sized objects are being allocated and freed in a random order, neither a stack-based allocator nor a pool-based allocator can be used.
stack-based allocator、pool-based allocator 不能解决所有问题。
Defragmentation involves coalescing all of the free “holes” in the heap by shifting allocated blocks from higher memory addresses down to lower addresses (thereby shifting the holes up to higher addresses).
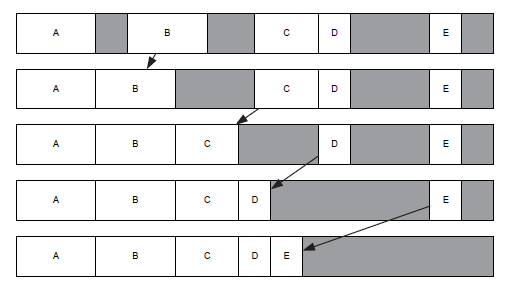
![]()
if we are going to support memory defragmentation in our game engine, programmers must either carefully keep track of all the pointers manually so they can be relocated, or pointers must be abandoned in favor of something inherently more amenable to relocation, such as smart pointers or handles.
smart pointer、handle 不需要显式更新,因为其内部会自动更新。
Naughty Dog’s engines have supported defragmentation. Handles are used wherever possible to avoid the need to relocate pointers. However, in some cases raw pointers cannot be avoided. These pointers are carefully tracked and relocated manually whenever a memory block is shifted due to defragmentation. A few of Naughty Dog’s game object classes are not relocatable for various reasons.
顽皮狗的引擎,尽可能使用 handle,裸指针细心track,并且 relocate manually,
25、Amortizing Defragmentation Costs
we needn’t fully defragment the heap all at once. Instead, the cost can be amortized over many frames. We can allow up to N allocated blocks to be shifted each frame, for some small value of N like 8 or 16.
26、Preincrement versus Postincrement
p++ 比 ++p 性能更高。
This means that writing ++p introduces a data dependency into your code—the CPU must wait for the increment operation to be completed before its value can be used in the expression. On a deeply pipelined CPU, this introduces a stall. On the other hand, with p++ there is no data dependency. The value of the variable can be used immediately, and the increment operation can happen later or in parallel with its use. Either way, no stall is introduced into the pipeline.
within the “update” expression of a for loop, there should be no difference between pre- and postincrement. This is because any good compiler will recognize that the value of the variable isn’t used in update_expr.
27、Folly
Folly is an open source library developed by Andrei Alexandrescu and the engineers at Facebook. Its goal is to extend the standard C++ library and the Boost library (rather than to compete with these libraries), with an emphasis on ease of use and the development of high-performance software.
28、Loki
There is a rather esoteric branch of C++ programming known as template meta-programming. I highly recommend that all software engineers read Andrei’s ground-breaking book, Modern C++ Design [3], from which the Loki library was born.
29、Dynamic Arrays and Chunky Allocation
Dynamic arrays are probably best used during development, when you are as yet unsure of the buffer sizes you’ll require. They can always be converted into fixed size arrays once suitable memory budgets have been established.
30、Dictionaries and Hash Tables

31、Implementing a Closed Hash Table
quadratic probing,当发生冲突时,尝试 (i+/-j^2),可以解决 Clump up 问题。
32、Robin Hood Hashing
Robin Hood hashing is another probing method for closed hash tables that has gained popularity recently. This probing scheme improves the performance of a closed hash table, even when the table is nearly full.
33、Hashed String Ids
At Naughty Dog, we started out using a variant of the CRC-32 algorithm to hash our strings, and we encountered only a handful of collisions during many years of development on Uncharted and The Last of Us. And when a collision did occur, fixing it was a simple matter of slightly altering one of the strings (e.g., append a “2” or a “b” to one of the strings, or use a totally different but synonymous string). That being said, Naughty Dog has moved to a 64-bit hashing function for The Last of Us Part II and all of our future game titles; this should essentially eliminate the possibility of hash collisions, given the quantity and typical lengths of the strings we use in any one game.
34、Some Implementation Ideas
At Naughty Dog, we permit runtime hashing of strings, but we also use C++11’s user-defined literals feature to transform the syntax "any_string"_sid directly into a hashed integer value at compile time.
Here’s one possible implementation of internString():
typedef U32 StringId; extern StringId internString(const char* str); static HashTable<StringId, const char*> gStringIdTable; StringId internString(const char* str) { StringId sid = hashCrc32(str); HashTable<StringId, const char*>::iterator it = gStringIdTable.find(sid); if (it == gStringTable.end()) { // This string has not yet been added to the // table. Add it, being sure to copy it in case // the original was dynamically allocated and // might later be freed. gStringTable[sid] = strdup(str); } return sid; }
35、UTF-16
Each character in a UTF-16 string is represented by either one or two 16-bit values. UTF-16
UTF-16 要么是2字节,要么是4字节。
In UTF-16, the set of all possible Unicode code points is divided into 17 planes containing 2^16 code points each. The first plane is known as the basic multilingual plane (BMP). It contains the most commonly used code points across a wide range of languages. As such, many UTF-16 strings can be represented entirely by code points within the first plane, meaning that each character in such a string is represented by only one 16-bit value. However, if a character from one of the other planes (known as supplementary planes) is required in a string, it is represented by two consecutive 16-bit values.
BMP的字符只需要2个字节,其他plane的字符需要4个字节。
The UCS-2 (2-byte universal character set) encoding is a limited subset of the UTF-16 encoding, utilizing only the basic multilingual page. As such, it cannot represent characters whose Unicode code points are numerically higher than 0xFFFF. This simplifies the format, because every character is guaranteed to occupy exactly 16 bits (two bytes). In other words, UCS-2 is a fixed-length character encoding, while in general UTF-8 and UTF-16 are variable-length encodings.
When storing UTF-16 text on-disc, it’s common to precede the text data with a byte order mark (BOM) indicating whether the individual 16-bit characters are stored in littleor big-endian format. (This is true of UTF-32 encoded string data as well, of
course.)
36、char versus wchar_t
The wchar_t type is a “wide” character type, intended to be capable of representing any valid code point in a single integer. As such, its size is compiler- and system-specific. It could be eight bits on a system that does not support Unicode at all. It could be 16 bits if the UCS-2 encoding is assumed for all wide characters, or if a multi-word encoding like UTF-16 is being employed. Or it could be 32 bits if UTF-32 is the “wide” character encoding of choice.
wchar_t 的size 不确定,与 compiler、system 相关。
37、Unicode under Windows
The Windows API defines three sets of character/string manipulation functions: one set for single-byte character set ANSI strings (SBCS), one set for multibyte character set (MBCS) strings, and one set for wide character set strings.
windows 定义了3种字符操作函数:SBCS,MBCS, Wide Character.
Throughout the Windows API, a prefix or suffix of “w,” “wcs” or “W” indicates a wide character set (UTF-16) encoding; a prefix or suffix of “mb” indicates a multibyte encoding; and a prefix or suffix of “a” or “A,” or the lack of any prefix or suffix, indicates an ANSI or Windows code pages encoding.
The C++ standard library uses a similar convention—for example, std::string is its ANSI string class, while std::wstring is its wide character equivalent.
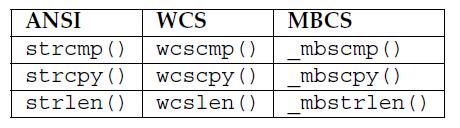
The generic character data type TCHAR is defined to be a typedef to char when building your application in “ANSI mode,” and it’s defined to be a typedef to wchar_t when building your application in “Unicode mode.”
38、Other Localization Concerns
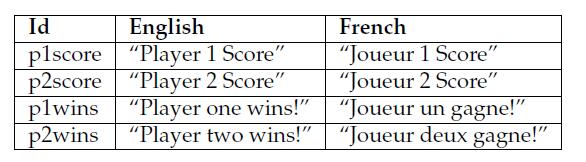

At runtime, you’ll need to provide a simple function that returns the Unicode string in the “current” language, given the unique id of that string:
void drawScoreHud(const Vector3& score1Pos, const Vector3& score2Pos) { renderer.displayTextOrtho(getLocalizedString("p1score"), score1Pos); renderer.displayTextOrtho(getLocalizedString("p2score"), score2Pos); // ... }
39、Per-User Options
On a Windows machine, each user has a folder under C:Users containing information such as the user’s desktop, his or her My Documents folder, his or her Internet browsing history and temporary files and so on. A hidden subfolder named AppData is used to store per-user information on a per application basis; each application creates a folder under AppData and can use it to store whatever per-user information it requires.
40、
41、
42、