交叉熵损失函数
交叉熵损失函数常作为深度学习分类任务的损失函数,本文主要对交叉熵进行了一个较为详细的了解。
交叉熵的几种表达形式
交叉熵的loss函数形式是比较统一的,之所以经常见到不同形式的交叉熵主要取决于你的分类任务是二分类还是多分类。
Binary CrossEntropy
[L = -frac{1}{n} sum_i^n{{y_i log{a_i} + (1-y_i) log{(1-a_i)}}}
]
Categorical CrossEntropy
[�egin{aligned}
L & = -frac{1}{n} sum_i^n{y_{i1}}log{a_{i1}} + {y_{i2}log{a_{i2}} + ... + {y_{im}}log{a_{im}}} \
& = -frac{1}{n} sum_i^n sum_j^m {y_{ij}} log{a_{ij}}
end{aligned}]
其中,n是样本数,m是类别数
对数似然函数与交叉熵的关系
注:以下比较是在单个样本下的对数似然函数公式及交叉熵公式
二元分布下对数似然函数的公式为
[L = ylnp(x) + (1-y)ln(1-p(x))
]
交叉熵的公式为
[H(p, q) = -sum{ p(x)log q(x) }
]
看起来两者公式是非常一致的。
这里X的分布模型即样本集的真实分布模型(p(x)),这里模型(q(x))即想要模拟真实分布模型的机器学习模型。可以说交叉熵是直接衡量两个分布,或者说两个model之间的差异。而似然函数则是解释以model的输出为参数的某分布模型对样本集的解释程度。因此,可以说这两者是“同貌不同源”,但是“殊途同归”啦。
均方误差与交叉熵误差(sigmoid为激活函数)
为什么常常使用交叉熵误差而不是均方误差作为神经网络的损失函数?可以从两个函数的梯度上看出一些端倪。
均方误差(MSE)与梯度更新
首先是均方误差,均方误差的损失函数为
[L=frac{1}{2n} {sum_{i}{||a_i - y_i||^2}}
]
(n)为样本数量,(a_i)为神经网络对当前样本的预测值,(y_i)为当前样本的标签。(a_i = sigma(z_i) = sigmoid(z_i) = sigmoid(wx_i+b))。
简化上式为(n=1)的情况,此时
[L = frac{(a-y)^2}{2}
]
那么参数(w)和(b)的梯度分别为
[�egin{aligned}
frac{partial{L}}{partial{w}} & = 2 * 1/2 * (a-y) * sigma'(z) * (wx+b)'_w \
& = (a-y) * sigma'(z) * x
end{aligned}]
[�egin{aligned}
frac{partial{L}}{partial{b}} & = 2 * 1/2 * (a-y) * sigma'(z) * (wx+b)'_b \
& = (a-y) * sigma'(z) * 1
end{aligned}]
交叉熵误差与梯度更新
其次是交叉熵误差,交叉熵误差的损失函数为
[L = -frac{1}{n} sum_i{{y_i log{a_i} + (1-y_i) log{(1-a_i)}}}
]
同样简化上式为(n=1)的情况,此时
[L = -(y log{a} + (1-y) log{(1-a)})
]
计算w和b的梯度为
[�egin{aligned}
frac{partial{L}}{partial{w}} & = -[frac{y}{a} * sigma'(z) * x -frac{1-y}{1-a}*sigma'(z)*x]\
& = -[ sigma'(z)*x*(frac{y}{a} - frac{1-y}{1-a}) ] \
& = -[ sigma(z)(1-sigma(z))*x*(frac{y}{a}-frac{1-y}{1-a}) ] \
& = -[ a(1-a)*x*(frac{y}{a}-frac{1-y}{1-a}) ] \
& = -x[ a(1-a)frac{y-a}{a(1-a)} ] \
& = x(a-y) \
end{aligned}]
[�egin{aligned}
frac{partial{L}}{partial{b}} & = -[ frac{y}{a}*sigma'(x)-frac{1-y}{1-a}*sigma'(x)] \
& = a - y \
end{aligned}]
对比与结论
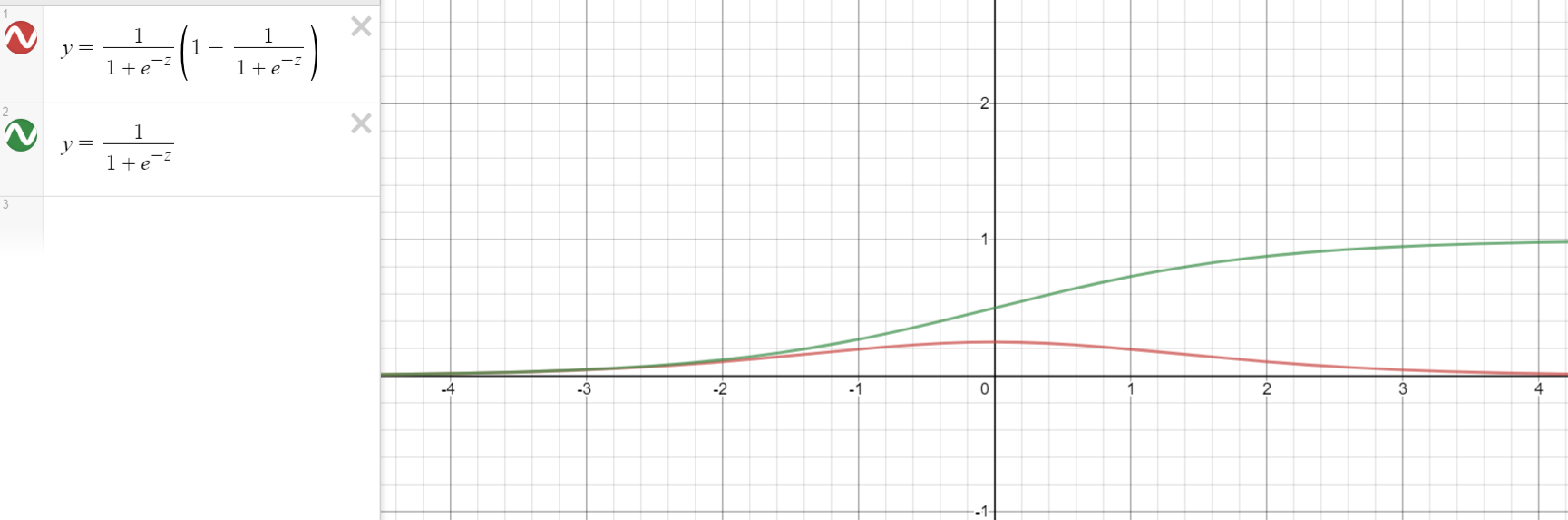
对比上述两个损失函数对参数w和b求导后的结果可以看出,均方误差求导后的梯度始终跟(sigma'(z))是有关系的,而交叉熵误差则不然。可见,关键就出在激活函数
[sigma(x) = sigmoid(z) = frac{1}{1+e^{-z}}
]
sigmoid的函数图像存在两端导数趋于零的特性,因此当z的值较大时,(sigma'(z))的值会趋于零,进而降低神经网络的收敛速度,因此不建议使用均方误差作为神经网络分类问题的损失函数。因此,结论为,当神经网络最后一层的激活函数是sigmoid函数时,使用二进制交叉熵损失函数可以解决sigmoid梯度消失的问题。
多分类交叉熵函数的梯度更新(softmax为激活函数)
首先明确softmax激活函数的表达式,当样本数n=1时,softmax函数可以表达为 $$a_{j} = frac{e^{z_j}}{sum_k^m{e^{z_k}}}$$
对应的多分类交叉熵损失函数表达式为
[L = -sum_j^m y_j ln{a_j}
]
对损失函数求导有,
[�egin{aligned}
frac{partial{L}}{partial{z_j}} & = frac{partial{L}}{partial{a_q}} * frac{partial{a_q}}{partial{z_j}} \
& = frac{partial{(-sum{y_q log{a_q}})}}{partial{a_q}} * frac{partial{a_q}}{partial{z_j}} \
& = -sum_q^m{y_q * frac{1}{a_q}} * frac{partial{a_q}}{partial{z_j}} \
end{aligned}]
此时有两个情况需要考虑,
[�egin{aligned}frac{partial{a_q}}{partial{z_j}} = frac{partial{a_j}}{partial{z_j}} & = frac{partial{frac{e^{z_j}}{sum_k^m{e^{z_k}}}}}{partial{z_j}} \
& = frac{ e^{z_j}sum_k^m{e^{z_k}} - e^{z_j}e^{z_j} }{sum_k^m{e^{z_k}}sum_k^m{e^{z_k}}} \
& = frac{ e^{z_j}(sum_k^m{e^{z_k}} - e^{z_j})}{sum_k^m{e^{z_k}}sum_k^m{e^{z_k}}} \
& = frac{ e^{z_j}}{sum_k^m{e^{z_k}}}frac{ sum_k^m{e^{z_k}} - e^{z_j}}{sum_k^m{e^{z_k}}} \
& = frac{ e^{z_j}}{sum_k^m{e^{z_k}}}(1 - frac{ e^{z_j}}{sum_k^m{e^{z_k}}}) \
& = a_j(1-a_j) \
end{aligned}]
[�egin{aligned}
frac{partial{a_q}}{partial{z_j}} & = frac{partial{frac{e^{z_q}}{sum_k^m{e^{z_k}}}}}{partial{z_j}}\
& = frac{0 - e^{z_q}e^{z_j}}{sum_k^m{e^{z_k}}}\
& = frac{0 - e^{z_q}e^{z_j}}{sum_k^m{e^{z_k}}sum_k^m{e^{z_k}}}\
& = - frac{ e^{z_q}}{sum_k^m{e^{z_k}}}frac{ e^{z_j}}{sum_k^m{e^{z_k}}}\
& = - a_q a_j\
end{aligned}]
整合上式之后可以得到最终的结论
[�egin{aligned}
frac{partial{L}}{partial{z_j}} = frac{partial{L}}{partial{a_q}} * frac{partial{a_q}}{partial{z_j}} & = -sum_q^m{y_q * frac{1}{a_q}} * frac{partial{a_q}}{partial{z_j}} \
& = -frac{y_j}{a_j}a_j(1-a_j) + a_q a_jsum_{q
eq{j}}frac{y_q}{a_q}\
& = y_j(a_j-1) + a_jsum_{q
eq{j}}y_q\
& = -y_j + a_jsum_{q}y_q\
& = a_j - y_j\
end{aligned}]
由上式可见,交叉熵与softmax的配合在梯度反向传播的时候计算量非常小,十分高效。
References