原文:http://tecdat.cn/?p=3897
文本分析:主题建模
library(tidyverse)
theme_set( theme_bw())
目标
- 定义主题建模
- 解释Latent Dirichlet分配以及此过程的工作原理
- 演示如何使用LDA从一组已知主题中恢复主题结构
- 演示如何使用LDA从一组未知主题中恢复主题结构
- 确定为k
- 选择适当参数的方法
- ķ
主题建模
通常,当我们在线搜索信息时,有两种主要方法:
- 关键字 - 使用搜索引擎并输入与我们想要查找的内容相关的单词
- 链接 - 使用网络的网络结构在页面之间移动。链接的页面可能共享相似或相关的内容。
另一种方法是通过主题搜索和探索文档。例如,David Blei建议搜索“纽约时报”的完整历史。广泛的主题可能与文章中的各个部分(外交政策,国家事务,体育)有关,但这些部分内或之间可能存在特定主题(中国外交政策,中东冲突,美国与俄罗斯的关系)。如果文档按这些主题分组,我们可以跟踪NYT随时间报告这些问题的演变,或者检查不同主题的讨论是如何相互交叉的。
为此,我们需要有关每篇文章主题的详细信息。对该语料库进行手工编码将非常耗时,更不用说在开始编码之前需要知道文档的主题结构。对于绝大多数的corpa来说,这不是一种可行的方法。
相反,我们可以使用概率主题模型,分析原始文本文档中的单词的统计算法来揭示语料库和单个文档本身的主题结构。在分析之前,它们不需要对文档进行任何手工编码或标记 - 相反,算法来自对文本的分析。
潜在的Dirichlet分配
LDA假定语料库中的每个文档都包含在整个语料库中找到的混合主题。主题结构是隐藏的 - 我们只能观察文档和文字,而不是主题本身。因为结构是隐藏的(也称为潜在的),所以该方法试图在给定已知单词和文档的情况下推断主题结构。
食物和动物
假设您有以下句子:
- 我早餐吃了香蕉和菠菜冰沙。
- 我喜欢吃西兰花和香蕉。
- 龙猫和小猫很可爱。
- 我姐姐昨天收养了一只小猫。
- 看看这只可爱的仓鼠嚼着一块西兰花。
Latent Dirichlet分配是一种自动发现这些句子所包含的主题的方法。例如,给定这些句子并询问2个主题,LDA可能会产生类似的东西
- 句子1和2:100%主题A.
- 句子3和4:100%主题B.
- 句子5:60%主题A,40%主题B.
- 主题A:30%西兰花,15%香蕉,10%早餐,10%咀嚼,......
- 主题B:20%的龙猫,20%的小猫,20%的可爱,15%的仓鼠,......
您可以推断出主题A是关于食物的主题,主题B是关于可爱动物的主题。但是,LDA没有以这种方式明确地确定主题。它所能做的就是告诉你特定单词与主题相关的概率。
LDA文档结构
LDA将文档表示为以某些概率吐出单词的主题混合。它假设文档以下列方式生成:在编写每个文档时,您
- 确定单词数N.
- ñ 该文件将有
- 为文档选择主题混合(根据固定K
- 集上的Dirichlet概率分布
- ķ主题)。例如,假设我们上面有两个食物和可爱的动物主题,你可以选择由1/3食物和2/3可爱动物组成的文件。
- 通过以下方式生成文档中的每个单词:
- 首先选择一个主题(根据您在上面采样的分布;例如,您可以选择1/3概率的食物主题和2/3概率的可爱动物主题)。
- 然后使用主题生成单词本身(根据主题的多项分布)。例如,食物主题可能输出概率为30%的“西兰花”,概率为15%的“香蕉”,依此类推。
假设这个文档集合的生成模型,LDA然后尝试从文档中回溯以找到可能已经生成集合的一组主题。
食物和动物
我们怎么能在前面的例子中生成句子?生成文档D时
d:
- 决定D
- d 将是关于食物的1/2和关于可爱动物的1/2。
- 选择5为D中
- 的单词数
- d。
- 从食物主题中选择第一个单词,然后给出“西兰花”这个词。
- 选择第二个词来自可爱的动物主题,它给你“熊猫”。
- 选择第三个词来自可爱的动物话题,给你“可爱”。
- 选择第四个词来源于食物主题,给你“樱桃”。
- 从食物主题中选出第五个词,给你“吃”。
因此,在LDA模型下生成的文件将是“西兰花熊猫可爱的樱桃吃”(请记住,LDA使用的是词袋模型)。
通过LDA学习主题结构
现在假设您有一组文档。你选择了一些固定数量的K.
ķ要发现的主题,并希望使用LDA来学习每个文档的主题表示以及与每个主题相关联的单词。你怎么做到这一点?一种方式(称为崩溃的吉布斯采样)如下:
- 浏览每个文档,并将文档中的每个单词随机分配给K中的一个
- ķ 主题
- 请注意,此随机分配已经为您提供了所有主题的所有文档和单词分布的主题表示。但由于它是随机的,这不是一个非常准确的结构。
- 换句话说,在这一步中,我们假设除了当前单词之外的所有主题分配都是正确的,然后使用我们的文档生成模型更新当前单词的赋值。
- 重复上一步骤很多次(真的很多次,比如最少10,000次),你最终会达到一个大致稳定的状态,你的任务非常好
- 您可以使用这些分配来估计两件事:
- 每个文档的主题混合(通过计算分配给该文档中每个主题的单词的比例)
- 与每个主题相关的单词(通过计算分配给每个主题的单词的比例)
具有已知主题结构的LDA
如果先验地知道一组文档的主题结构,则LDA可能是有用的。例如,假设您有四本书:
- 查尔斯狄更斯的远大前程
- HG威尔斯的世界大战
- 朱尔斯凡尔纳在海底的二万个联盟
- 简奥斯汀的傲慢与偏见
一个破坏者已经闯入你的家,并将书籍撕成了单独的章节,并将它们留在一个大堆中。我们可以使用LDA和主题建模来发现章节与不同主题(即书籍)的关系。
我们将使用gutenbergr包检索这四本书:
titles <- c("Twenty Thousand Leagues under the Sea", "The War of the Worlds",
%in% titles) %>%
gutenberg_download(meta_fields = "title")
作为预处理,我们将这些分为章节,使用tidytext unnest_tokens将它们分成单词,然后删除stop_words。我们将每一章都视为一个单独的“文档” 。
library(tidytext)
library(stringr)
by_chapter <- books %>%
group_by(title) %>%
mutate(chapter = cumsum( str_detect(text, regex("^chapter ", ignore_case = TRUE)))) %>%
ungroup() %>%
filter(chapter > 0)
anti_join(stop_words) %>%
count(title_chapter, word, sort = TRUE) %>%
ungroup()
## Joining, by = "word"
word_counts
## # A tibble: 104,721 × 3
## title_chapter word n
## <chr> <chr> <int>
## 1 Great Expectations_57 joe 88
## 2 Great Expectations_7 joe 70
## 3 Great Expectations_17 biddy 63
## 4 Great Expectations_27 joe 58
## 5 Great Expectations_38 estella 58
## 6 Great Expectations_2 joe 56
## 7 Great Expectations_23 pocket 53
## 8 Great Expectations_15 joe 50
## 9 Great Expectations_18 joe 50
## 10 The War of the Worlds_16 brother 50
## # ... with 104,711 more rows
使用topicmodels包装进行潜在Dirichlet分配
现在,这个数据框架是一个整洁的形式,每行每个文档一个术语。但是,topicmodels包需要一个DocumentTermMatrix(来自tm包)。我们可以将每行一个令牌表转换为DocumentTermMatrixwith tidytext的cast_dtm:
chapters_dtm
## <<DocumentTermMatrix (documents: 193, terms: 18215)>>
## Non-/sparse entries: 104721/3410774
## Sparsity : 97%
## Maximal term length: 19
## Weighting : term frequency (tf)
现在我们准备使用该topicmodels包创建一个四主题LDA模型。
chapters_lda <- LDA(chapters_dtm, k = 4, control = list(seed = 1234))
chapters_lda
## A LDA_VEM topic model with 4 topics.
- 在这种情况下,我们知道有四个主题,因为有四本书; 这是了解潜在主题结构的价值
- seed = 1234设置随机迭代过程的起点。如果我们没有设置一致的种子,那么每次运行脚本时我们都可以估算出略有不同的模型
现在tidytext让我们可以选择使用从包中借来的和动词来返回整洁的分析。特别是,我们从动词开始。tidyaugmentbroomtidy
library(tidytext)
chapters_lda_td <- tidy(chapters_lda)
chapters_lda_td
## # A tibble: 72,860 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 joe 5.830326e-17
## 2 2 joe 3.194447e-57
## 3 3 joe 4.162676e-24
## 4 4 joe 1.445030e-02
## 5 1 biddy 7.846976e-27
## 6 2 biddy 4.672244e-69
## 7 3 biddy 2.259711e-46
## 8 4 biddy 4.767972e-03
## 9 1 estella 3.827272e-06
## 10 2 estella 5.316964e-65
## # ... with 72,850 more rows
请注意,这已将模型转换为每行一个主题的每个主题格式。对于每种组合,模型都具有β(β
β),该术语从该主题生成的概率。
我们可以使用dplyr's top_n来查找每个主题中的前5个术语:
top_terms <- chapters_lda_td %>%
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)
top_terms
## # A tibble: 20 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 elizabeth 0.014107538
## 2 1 darcy 0.008814258
## 3 1 miss 0.008706741
## 4 1 bennet 0.006947431
## 5 1 jane 0.006497512
## 6 2 captain 0.015507696
## 7 2 nautilus 0.013050048
## 8 2 sea 0.008850073
## 9 2 nemo 0.008708397
## 10 2 ned 0.008030799
## 11 3 people 0.006797400
## 12 3 martians 0.006512569
## 13 3 time 0.005347115
## 14 3 black 0.005278302
## 15 3 night 0.004483143
## 16 4 joe 0.014450300
## 17 4 time 0.006847574
## 18 4 pip 0.006817363
## 19 4 looked 0.006365257
## 20 4 miss 0.006228387
该模型适用于可视化:
top_terms %>%
mutate(term = reorder(term, beta)) %>%
ggplot( aes(term, beta, fill = factor(topic))) +
geom_bar(alpha = 0.8, stat = "identity", show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip()
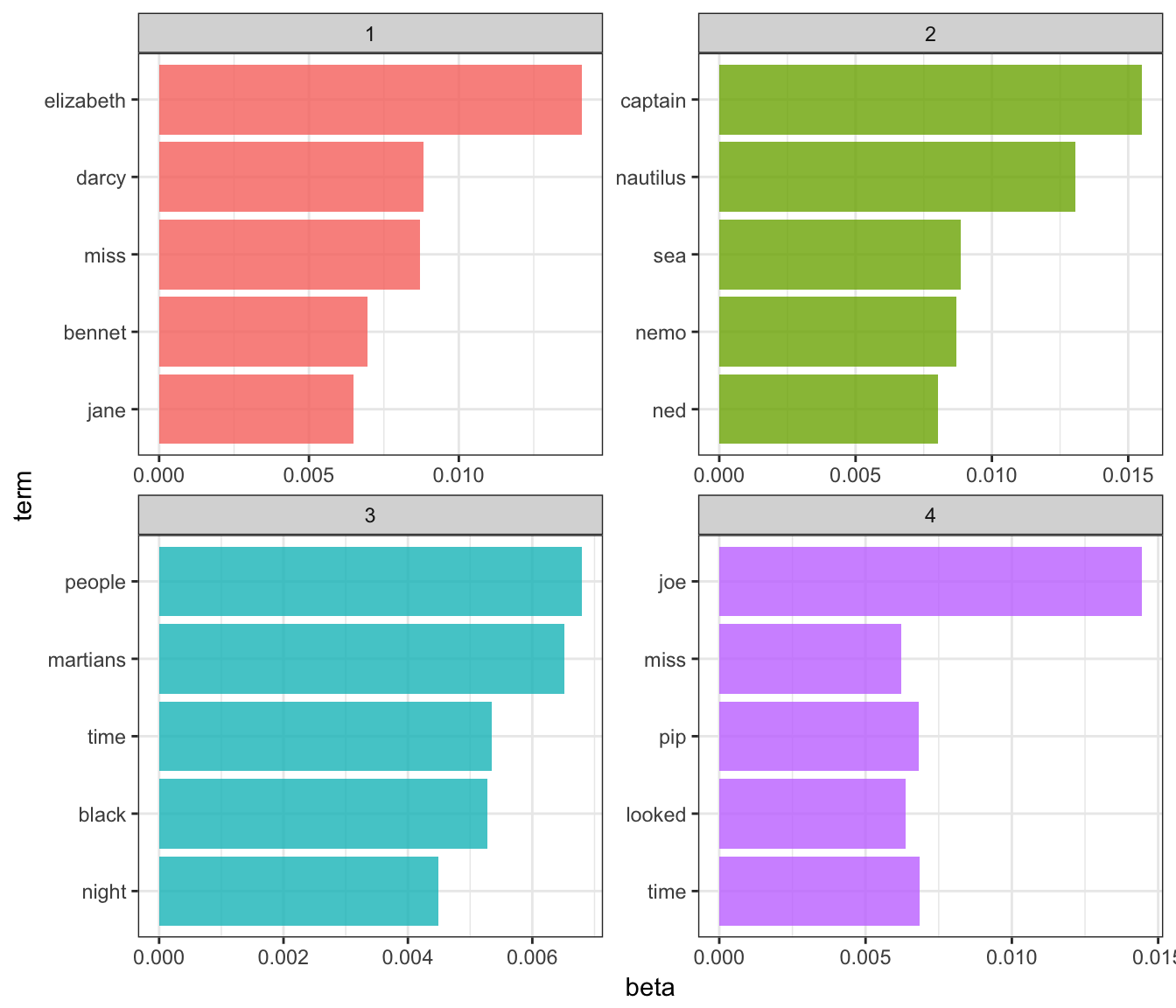
- 这些主题与四本书非常明显相关
- “nemo”,“sea”和“nautilus”属于海底二万里
- “jane”,“darcy”和“elizabeth”属于Pride and Prejudice
- 来自远大前程的 “pip”和“joe”
- 来自世界大战的 “火星人”,“黑人”和“夜晚”
- 另请注意,LDA()不会为每个主题分配任何标签。它们只是主题1,2,3和4. 我们可以推断这些与每本书有关,但它仅仅是我们的推论。
按文档分类
每一章都是本分析中的“文件”。因此,我们可能想知道哪些主题与每个文档相关联。我们可以把这些章节放回正确的书中吗?
chapters_lda_gamma
## # A tibble: 772 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 Great Expectations_57 1 1.351886e-05
## 2 Great Expectations_7 1 1.470726e-05
## 3 Great Expectations_17 1 2.117127e-05
## 4 Great Expectations_27 1 1.919746e-05
## 5 Great Expectations_38 1 3.544403e-01
## 6 Great Expectations_2 1 1.723723e-05
## 7 Great Expectations_23 1 5.507241e-01
## 8 Great Expectations_15 1 1.682503e-02
## 9 Great Expectations_18 1 1.272044e-05
## 10 The War of the Worlds_16 1 1.084337e-05
## # ... with 762 more rows
设置matrix = "gamma"返回一个整理版本,每行每个主题一个文档。现在我们已经有了这些文档分类,我们可以看到我们的无监督学习在区分四本书方面做得如何。首先,我们将文档名称重新分为标题和章节:
chapters_lda_gamma <- chapters_lda_gamma %>%
separate(document, c("title", "chapter"), sep = "_", convert = TRUE)
chapters_lda_gamma
## # A tibble: 772 × 4
## title chapter topic gamma
## * <chr> <int> <int> <dbl>
## 1 Great Expectations 57 1 1.351886e-05
## 2 Great Expectations 7 1 1.470726e-05
## 3 Great Expectations 17 1 2.117127e-05
## 4 Great Expectations 27 1 1.919746e-05
## 5 Great Expectations 38 1 3.544403e-01
## 6 Great Expectations 2 1 1.723723e-05
## 7 Great Expectations 23 1 5.507241e-01
## 8 Great Expectations 15 1 1.682503e-02
## 9 Great Expectations 18 1 1.272044e-05
## 10 The War of the Worlds 16 1 1.084337e-05
## # ... with 762 more rows
然后我们检查每个章节的正确部分:
ggplot(chapters_lda_gamma, aes(gamma, fill = factor(topic))) +
geom_histogram() +
facet_wrap(~ title, nrow = 2)
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
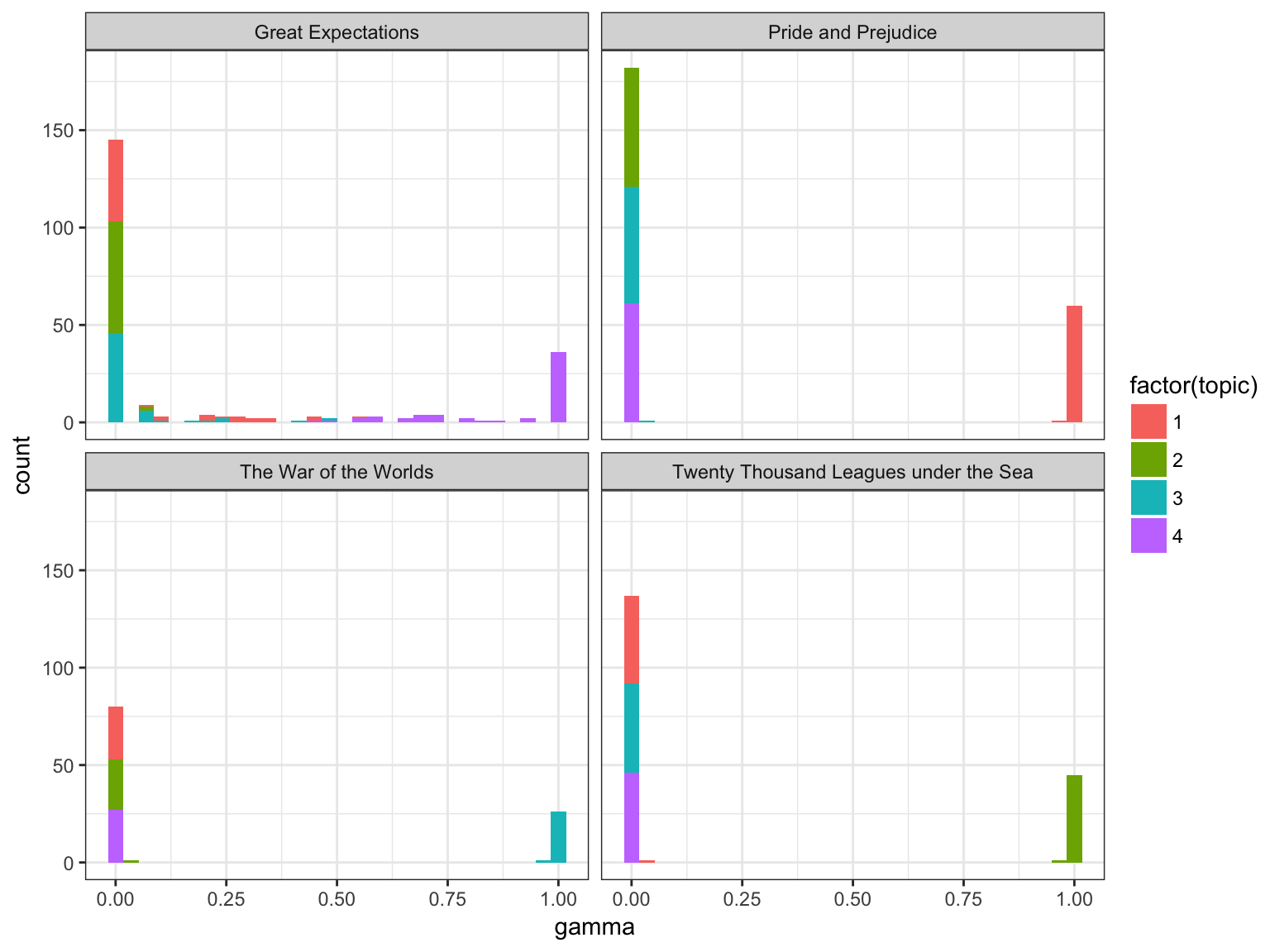
我们注意到,几乎所有来自“ 傲慢与偏见”,“世界大战 ”和“ 海底二万里 ”的章节都被唯一地确定为每个章节。
chapter_classifications <- chapters_lda_gamma %>%
group_by(title, chapter) %>%
top_n(1, gamma) %>%
ungroup() %>%
arrange(gamma)
chapter_classifications
## # A tibble: 193 × 4
## title chapter topic gamma
## <chr> <int> <int> <dbl>
## 1 Great Expectations 54 3 0.4803234
## 2 Great Expectations 22 4 0.5356506
## 3 Great Expectations 31 4 0.5464851
## 4 Great Expectations 23 1 0.5507241
## 5 Great Expectations 33 4 0.5700737
## 6 Great Expectations 47 4 0.5802089
## 7 Great Expectations 56 4 0.5984806
## 8 Great Expectations 38 4 0.6455341
## 9 Great Expectations 11 4 0.6689600
## 10 Great Expectations 44 4 0.6777974
## # ... with 183 more rows
我们可以通过找到每个的共识书来确定这一点,我们在前面的可视化中注意到它是正确的:
book_topics
## # A tibble: 4 × 2
## consensus topic
## <chr> <int>
## 1 Great Expectations 4
## 2 Pride and Prejudice 1
## 3 The War of the Worlds 3
## 4 Twenty Thousand Leagues under the Sea 2
然后我们看到哪些章节被错误识别:
chapter_classifications %>%
inner_join(book_topics, by = "topic") %>%
count(title, consensus) %>%
knitr:: kable()
标题共识ñ很大的期望很大的期望57很大的期望傲慢与偏见1很大的期望世界大战1傲慢与偏见傲慢与偏见61世界大战世界大战27海底二万里海底二万里46
我们看到,“ 远大前程”中只有几章被错误分类。
按字分配: augment
主题建模期望最大化算法中的一个重要步骤是将每个文档中的每个单词分配给一个主题。文档中的单词越多分配给该主题,通常,权重(gamma)将在该文档主题分类上进行。
我们可能希望采用原始文档 - 单词对,并找出每个文档中的哪些单词被分配到哪个主题。这是augment动词的工作。
标题很大的期望傲慢与偏见世界大战海底二万里很大的期望4977038761845年77傲慢与偏见1372297五世界大战00225617海底二万里0五039629
我们注意到,“ 傲慢与偏见”,“ 海底二万里联盟”和“ 世界大战”的几乎所有词语都被正确分配,而“远大前程”则有相当多的错误分配。
什么是最常犯的错误词?
wrong_words <- assignments %>%
filter(title != consensus)
wrong_words
## # A tibble: 4,535 × 6
## title chapter term count .topic
## <chr> <int> <chr> <dbl> <dbl>
## 1 Great Expectations 38 brother 2 1
## 2 Great Expectations 22 brother 4 1
## 3 Great Expectations 23 miss 2 1
## 4 Great Expectations 22 miss 23 1
## 5 Twenty Thousand Leagues under the Sea 8 miss 1 1
## 6 Great Expectations 31 miss 1 1
## 7 Great Expectations 5 sergeant 37 1
## 8 Great Expectations 46 captain 1 2
## 9 Great Expectations 32 captain 1 2
## <chr> <chr> <chr> <dbl>
## 1 Great Expectations Pride and Prejudice love 44
## 2 Great Expectations Pride and Prejudice sergeant 37
## 3 Great Expectations Pride and Prejudice lady 32
## 4 Great Expectations Pride and Prejudice miss 26
## 5 Great Expectations The War of the Worlds boat 25
## 6 Great Expectations Pride and Prejudice father 19
## 7 Great Expectations The War of the Worlds water 19
## 8 Great Expectations Pride and Prejudice baby 18
## 9 Great Expectations Pride and Prejudice flopson 18
## 10 Great Expectations Pride and Prejudice family 16
## # ... with 3,490 more rows
注意这里的“flopson”这个词; 这些错误的词语并不一定出现在他们错误分配的小说中。实际上,我们可以确认“flopson”只出现在Great Expectations中:
## 1 Great Expectations_22 flopson 10
## 2 Great Expectations_23 flopson 7
## 3 Great Expectations_33 flopson 1
该算法是随机的和迭代的,它可能会意外地落在跨越多本书的主题上。
具有未知主题结构的LDA
通常在使用LDA时,您实际上并不知道文档的基础主题结构。通常,这就是您首先使用LDA分析文本的原因。LDA在这些情况下仍然有用,但我们必须执行其他测试和分析,以确认LDA发现的主题结构是一个很好的结构。
美联社的文章
该topicmodels软件包包括由美联社在1992年发布的文章样本的文档术语矩阵。让我们将它们加载到R中并将它们转换为整齐的格式。
## 1 1 adding 1
## 2 1 adult 2
## 3 1 ago 1
## 4 1 alcohol 1
## 5 1 allegedly 1
## 6 1 allen 1
## 7 1 apparently 2
## 8 1 appeared 1
## 9 1 arrested 1
## 10 1 assault 1
## # ... with 302,021 more rows
AssociatedPress最初是在文档术语矩阵中,正是我们对主题建模所需要的。为什么要先整理一下?因为原始的dtm包含停用词 - 我们想在建模数据之前删除它们。让我们删除停用词,然后将数据转换回文档术语矩阵。
## Sparsity : 99%
## Maximal term length: 18
## Weighting : term frequency (tf)
选择kķ
请记住,对于LDA,您需要事先指定基础主题结构中的主题数。
k = 4ķ=4
让我们估算美联社文章的LDA模型,设定k
=
## A LDA_VEM topic model with 4 topics.
每个主题的顶级术语是什么样的?
ap_lda_td <- tidy(ap_lda)
top_terms <- ap_lda_td %>%
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)
top_terms
## # A tibble: 20 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 soviet 0.009502197
## 2 1 government 0.009198486
## 3 1 president 0.007046753
## 4 1 united 0.006507324
## 5 1 people 0.005402784
## 6 2 people 0.007454587
## 7 2 police 0.006433472
## 8 2 city 0.003996852
## 9 2 time 0.003369658
## 10 2 school 0.003058213
## 11 3 court 0.006850723
## 12 3 bush 0.006510244
## 13 3 president 0.005777216
## 14 3 federal 0.005512805
## 15 3 house 0.004657550
## 16 4 percent 0.023766679
## 17 4 million 0.012489935
## 18 4 billion 0.009864418
## 19 4 market 0.008402463
## 20 4 prices 0.006693626
top_terms %>%
) +
coord_flip()
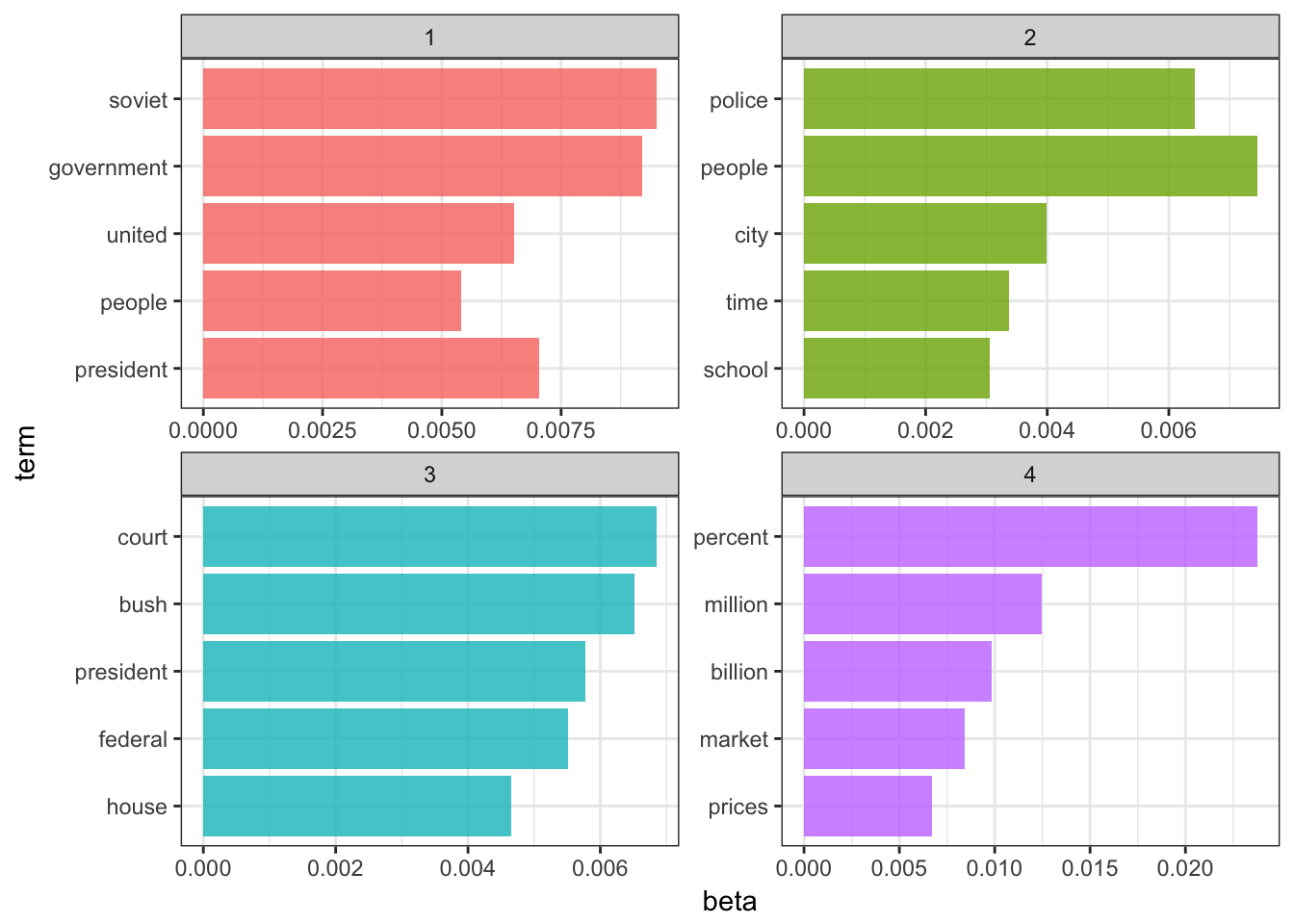
很公平。这四个主题通常用于描述:
- 美苏关系
- 犯罪和教育
- 美国(国内)政府
- 这是经济,愚蠢
k = 12ķ=12
如果我们设置k
=
12
会发生什么
ķ=12?我们的结果如何变化?
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)
top_terms
## # A tibble: 60 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 military 0.011691176
## 2 1 united 0.011598436
## 3 1 iraq 0.010618221
## 4 1 president 0.009498227
## 5 1 american 0.008253379
## 6 2 dukakis 0.009819260
## 7 2 bush 0.007300830
## 8 2 campaign 0.006366915
## 9 2 people 0.006098596
## 10 2 school 0.005208529
## # ... with 50 more rows
+
coord_flip()
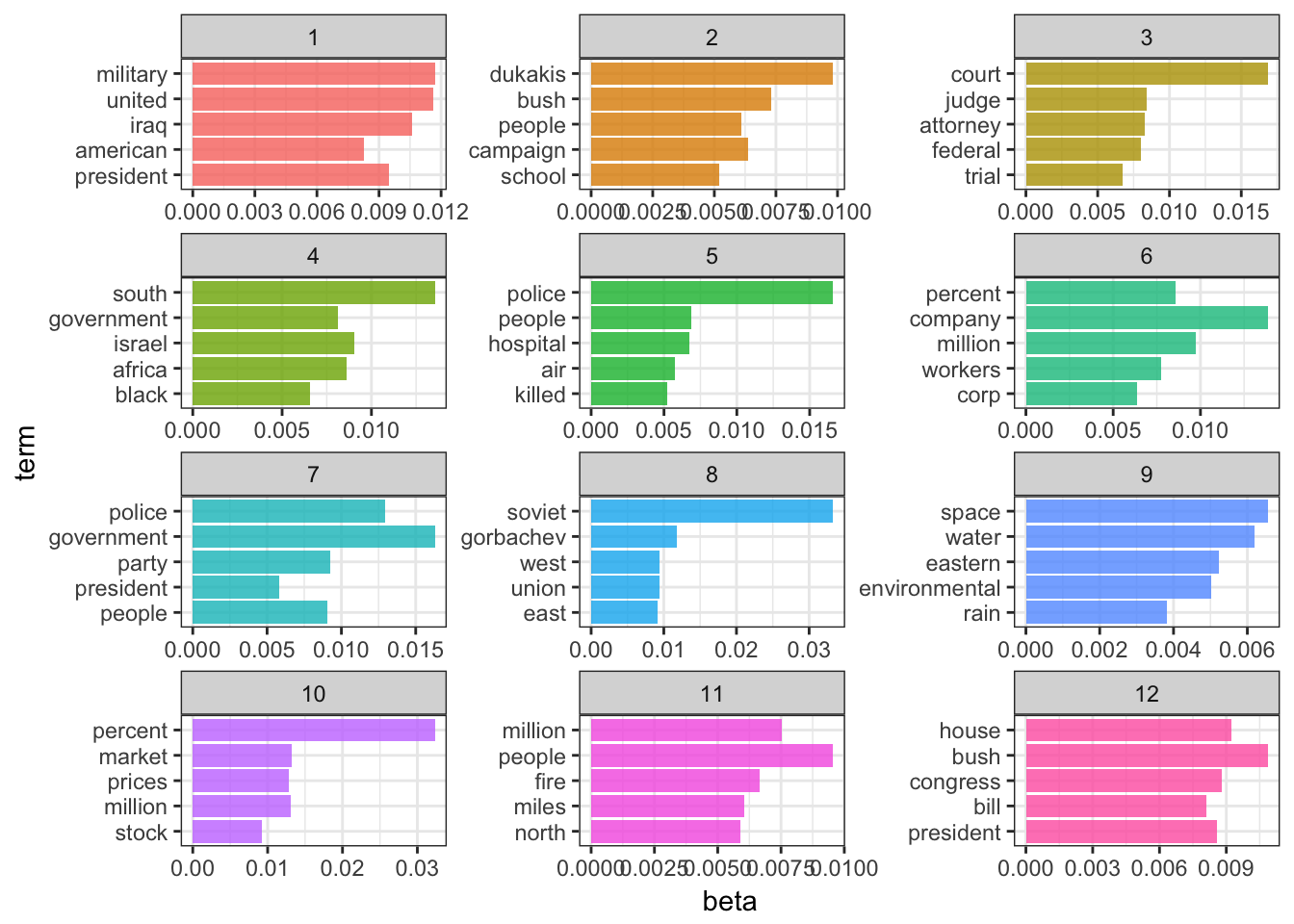
嗯。嗯,这些主题似乎更具体,但不易解码。
- 伊拉克战争(I)
- 布什的连任竞选活动
- 联邦法院
- 种族隔离和南非
- 犯罪
- 经济
- ???
- 前苏联
- 环境
- 股市
- 野火?
- 布什 - 国会关系(也许是国内政策?)
唉,这是LDA的问题。k的
几个不同的值
ķ可能看似合理,但通过增加k
ķ我们牺牲清晰度。是否有任何统计指标可以帮助我们确定最佳主题数量?
困惑
好吧,有点。LDA的某些方面是由直觉思维(或者也许是真实性)驱动的。但是我们可以提供一些帮助。困惑是概率模型预测样本的程度的统计量度。适用于LDA,对于给定的k
值
ķ,你估计LDA模型。然后给出由主题表示的理论单词分布,将其与实际主题混合或文档中单词的分布进行比较。
topicmodels包括perplexity为给定模型计算该值的函数。
perplexity(ap_lda)
## [1] 2301.814
但是,统计数据本身有点无意义。这种统计数据的好处在于比较不同模型的不同k的
困惑
ķ秒。具有最低困惑度的模型通常被认为是“最佳”。
让我们估算美联社数据集上的一系列LDA模型。在这里,我利用purrr和map函数迭代生成AP语料库的一系列LDA模型,在每个模型中使用不同数量的主题。1
n_topics <- c(2, 4, 10, 20, 50, 100)
ap_lda_compare <- n_topics %>%
map(LDA, x = ap_dtm, control = list(seed = 1109))
geom_point() +
y = "Perplexity")
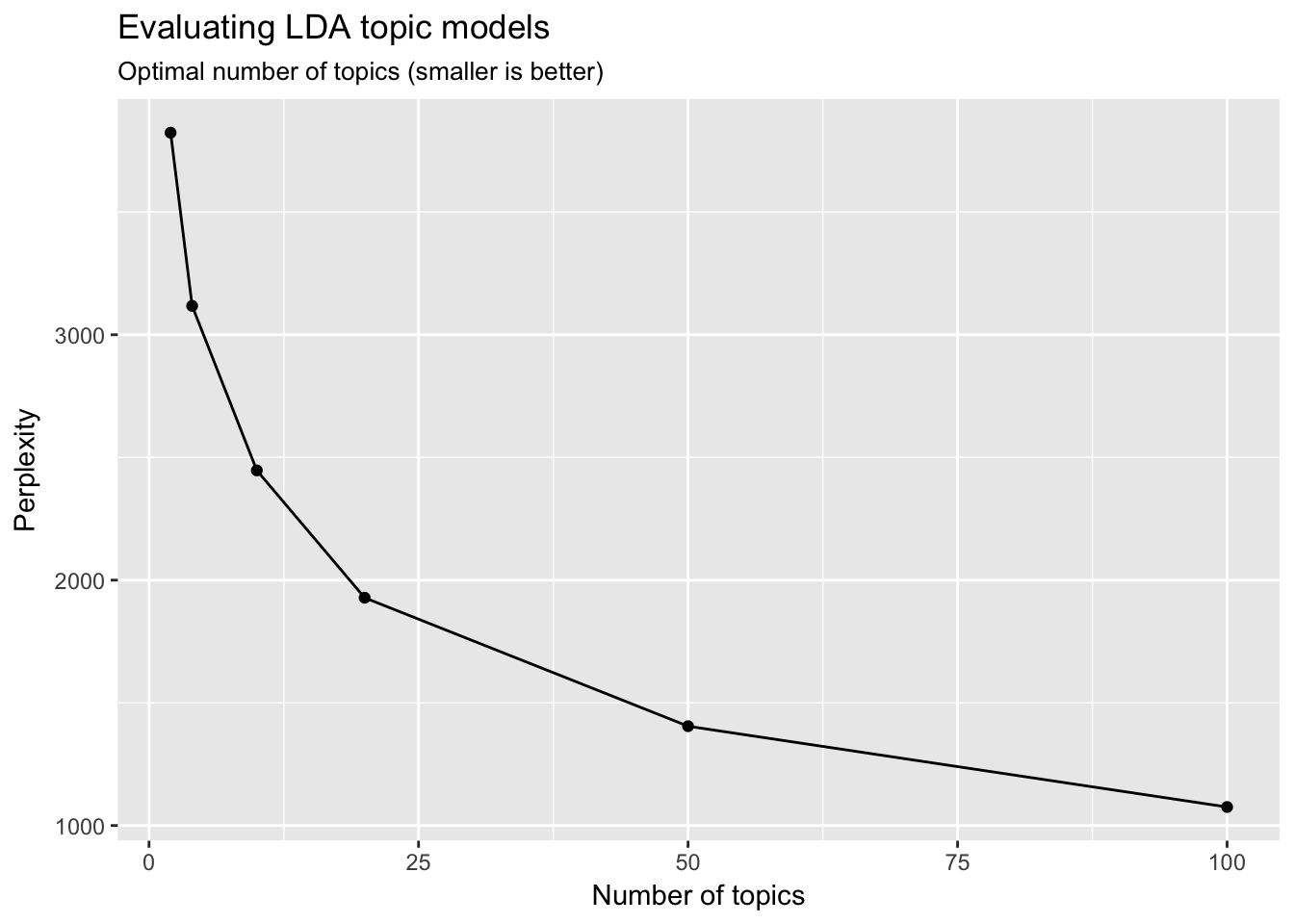
看起来100主题模型具有最低的困惑分数。这会产生什么样的主题?让我们看一下模型产生的前12个主题(ggplot2难以渲染100个不同方面的图形):
ap_lda_td <- tidy(ap_lda_compare[[6]])
top_terms <- ap_lda_td %>%
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)
top_terms
## # A tibble: 502 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 party 0.020029039
## 2 1 communist 0.013810107
## 3 1 government 0.013221069
## 4 1 news 0.013036980
## 5 1 soviet 0.011512086
## 6 2 york 0.010501689
## 7 2 vargas 0.008539895
## 8 2 fujimori 0.008539895
## 9 2 people 0.007800735
## 10 2 police 0.007475843
## # ... with 492 more rows
top_terms %>%
filter(topic <= 12) %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_bar(alpha = 0.8, stat = "identity", show.legend = FALSE) +
facet_wrap(~ topic, scales = "free", ncol = 3) +
coord_flip()
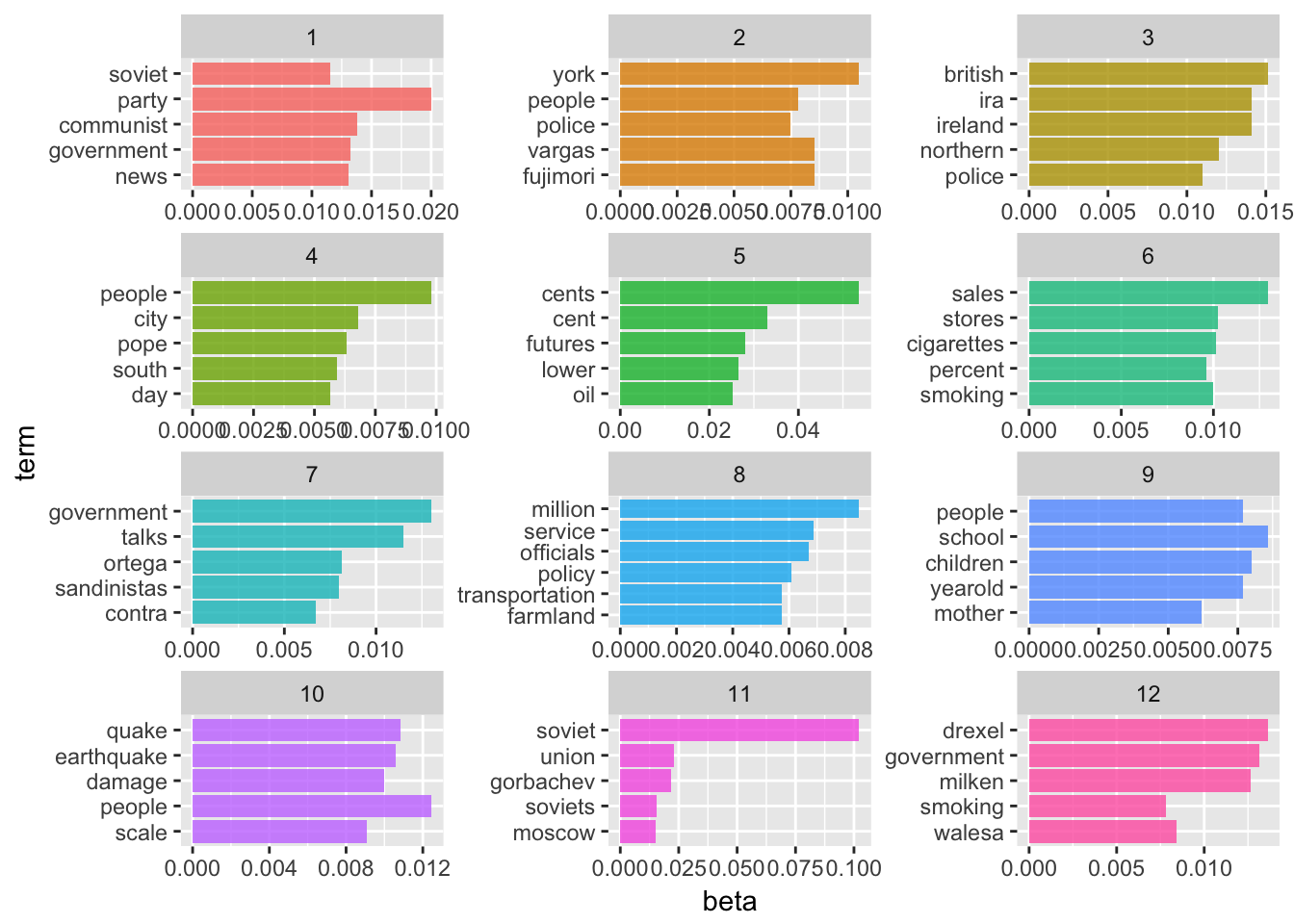
我们现在正在获得更具体的主题。问题是我们如何呈现这些结果并以信息方式使用它们?更不用说在k
=
100时,
困惑仍在下降
ķ=100- 将k
=
200
ķ=200产生更低的困惑分数?2
同样,这也是您作为研究人员的直觉和领域知识非常重要的地方。您可以使用困惑作为决策过程中的一个数据点,但很多时候它只是简单地查看主题本身以及与每个主题相关联的最高概率词来确定结构是否有意义。如果您有一个已知的主题结构,您可以将其与之比较(例如上面的书籍示例),这也很有用。