原文链接:http://tecdat.cn/?p=4740
缺少数据在分析数据集时可能不是一个微不足道的问题。
如果缺失数据的量相对于数据集的大小非常小,那么为了不偏离分析而忽略缺少特征的少数样本可能是最好的策略,但是留下可用的数据点会剥夺某些数据的特征。
尽管某些快速修正如均值替代在某些情况下可能很好,但这种简单的方法通常会向数据中引入偏差。
在这篇文章中,我们将使用airquality数据集(在R中提供)来推测缺失值。
为了本文的目的,我将从数据集中删除一些数据点。
快速分类缺失数据
有两种类型的缺失数据:
MCAR:随意丢失。
MNAR:不是随意丢失的。随机数据丢失是一个更严重的问题,在这种情况下,进一步检查数据收集过程并尝试理解信息丢失的原因可能是明智的。例如,如果调查中的大多数人没有回答某个问题,他们为什么这样做?这个问题不清楚吗?
假设数据是MCAR,太多丢失的数据也可能成为一个问题。
pMiss < - function(x){sum(is.na(x))/ length(x)* 100}
我们发现臭氧几乎失去了25%的数据点,因此我们可能会考虑将其从分析中删除或收集更多的测量数据。
其他变量低于5%的阈值,所以我们可以保留它们。就样本而言,仅缺少一个特征会导致每个样本缺失25%的数据。如果可能,应丢弃缺少2个或更多特征(> 50%)的样本。
查看缺失的数据模式
该mice软件包提供了一个很好的功能md.pattern(),可以更好地理解丢失数据的模式
输出结果告诉我们,104个样本是完整的,34个样本只错过臭氧测量,4个样本只错过了Solar.R值,等等。
一个可能更有用的视觉表示可以使用下面的VIM包得到
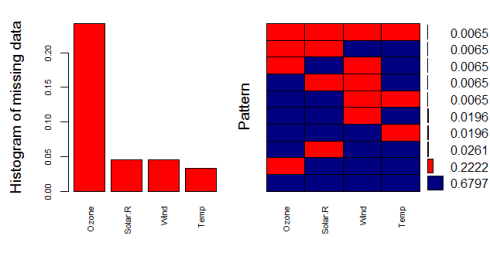
该图有助于我们理解几乎70%的样本没有遗漏任何信息,22%的人缺少臭氧值,剩余的样本显示其他遗漏的模式。通过这种方法,我认为情况看起来更清楚一些。
marginplot
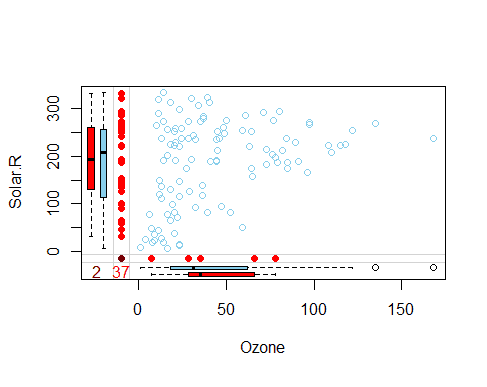
左边的红色方块图显示Solar.R的分布与臭氧缺失,而蓝色方块图显示剩余数据点的分布。
如果我们假设MCAR数据是正确的,那么我们预计红色和蓝色方块图非常相似。
输入缺失的数据
现在我们可以使用该complete()函数返回已完成的数据集。
completedData < - complete(tempData,1)
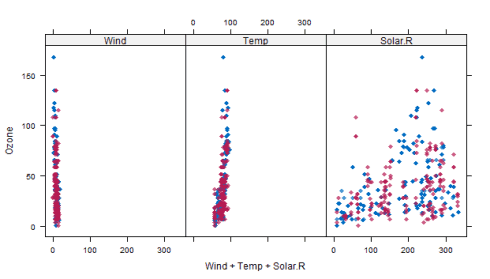
首先,我们可以使用散点图并将臭氧对所有其他变量进行绘图
xyplot(tempData,Ozone_Wind + Temp + Solar.R,pch = 18,cex = 1)
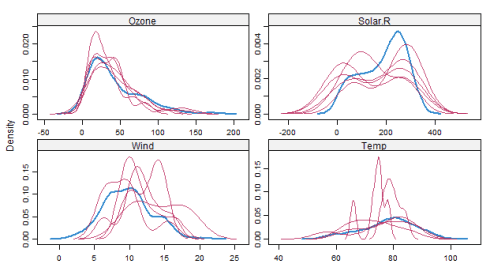
密度图:
densityplot
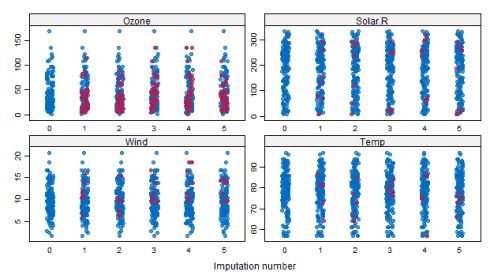
stripplot(tempData,pch = 20,cex = 1.2)