全文链接:http://tecdat.cn/?p=2858
本文的目的是对如何在R中进行生存分析进行简短而全面的评估。关于该主题的文献很广泛,仅涉及有限数量的(常见)问题。可用的R包数量反映了对该主题的研究范围。(点击文末“阅读原文”获取完整代码数据)。
视频:R语言生存分析原理与晚期肺癌患者分析案例
拓端
,赞4
R语言生存分析Survival analysis原理与晚期肺癌患者分析案例
R包
可以使用各种R包来解决特定问题。以下是本次用于读取,管理,分析和显示数据的软件包。
运行以下行以安装和加载所需的包。
-
if (!require(pacman)) install.packages("pacman")
-
pacman::p_load(tidyverse, survival )
**
数据
该评价将基于orca数据集,数据集包含1985年1月1日至2005年12月31日期间芬兰最北部省份诊断为口腔鳞状细胞癌(OSCC)的338名患者的一部分。患者的随访始于癌症诊断之日,并于2008年12月31日死亡,迁移或随访截止日期结束。死亡原因分为两类:(1) )OSCC死亡; (2)其他原因造成的死亡。
数据集包含以下变量:id=序号,sex=性别,类别1 =“女性”,2 =“男性”,age=诊断癌症日期的年龄(年),stage=肿瘤的TNM分期(因子):1 =“I”,..., 4 =“IV”,5 =“unkn” time=自诊断至死亡或审查的随访时间(以年为单位),event=结束随访的事件(因子):1 =正常,2 =口腔癌死亡, 3 =其他原因造成的死亡。
将数据从URL加载到R中。
head(orca)
-
id sex age stage time event
-
1 1 Male 65.42274 unkn 5.081 Alive
-
2 2 Female 83.08783 III 0.419 Oral ca. death
-
3 3 Male 52.59008 II 7.915 Other death
-
4 4 Male 77.08630 I 2.480 Other death
-
5 5 Male 80.33622 IV 2.500 Oral ca. death
-
6 6 Female 82.58132 IV 0.167 Other death
summary(orca)
-
id sex age stage time event
-
Min. : 1.00 Female:152 Min. :15.15 I :50 Min. : 0.085 Alive :109
-
1st Qu.: 85.25 Male :186 1st Qu.:53.24 II :77 1st Qu.: 1.333 Oral ca. death:122
-
Median :169.50 Median :64.86 III :72 Median : 3.869 Other death :107
-
Mean :169.50 Mean :63.51 IV :68 Mean : 5.662
-
3rd Qu.:253.75 3rd Qu.:74.29 unkn:71 3rd Qu.: 8.417
-
Max. :338.00 Max. :92.24 Max. :23.258
生存数据分析
生存分析侧重于事件数据的时间。在我们的例子中,是诊断后的死亡时间。
为了定义失效时间随机变量,我们需要:
1。时间起源(诊断OSCC),
2。时间尺度(诊断后的年数,年龄),
3。事件的定义。我们将首先考虑总死亡率 。

图1:转换的框图。
-
Alive Oral ca. death Other death
-
109 122 107
-
-
FALSE TRUE
-
109 229
以图形方式显示观察到的随访时间对于生存数据的分析非常有帮助。
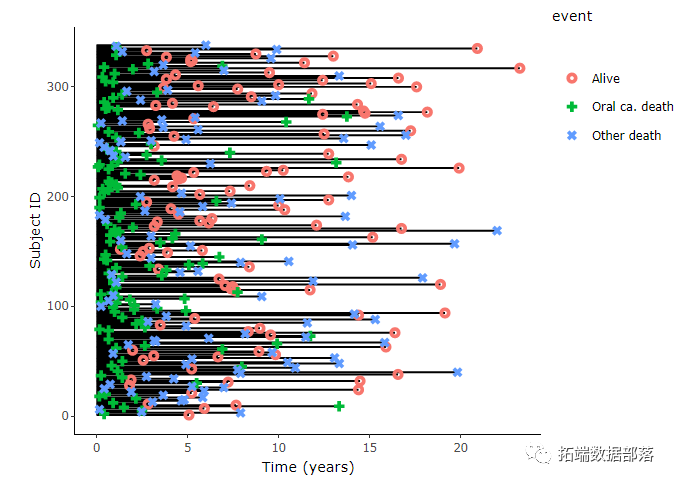
OSCC死亡更有可能在诊断后早期发生,而不是其他原因引起的死亡。类型怎么样?
-
'Surv' num [1:338, 1:2] 5.081+ 0.419 7.915 2.480 2.500 0.167 5.925+ 1.503 13.333 7.666+ ...
-
- attr(*, "dimnames")=List of 2
-
..$ : NULL
-
..$ : chr [1:2] "time" "status"
-
- attr(*, "type")= chr "right"
然后将创建的生存对象用作生存分析的其他特定函数中的因变量。
相关视频
拓端
,赞11
拓端
,赞4
估计生存函数
非参数估计
我们将首先介绍一类非参数估计 。
Kaplan–Meier
生存曲线基于每个死亡时间的风险数量和事件数量。包的survfit()创建(估计)生存曲线 。
-
Call: survfit(formula = Surv(time, all) ~ 1, data = orca)
-
n events *rmean *se(rmean) median 0.95LCL 0.95UCL
-
338.000 229.000 8.060 0.465 5.418 4.331 6.916
-
* restricted mean with upper limit = 23.3
函数返回估计的生存曲线的摘要。
-
time n.risk n.event n.censor surv std.err upper lower
-
1 0.085 338 2 0 0.9940828 0.004196498 1.0000000 0.9859401
-
2 0.162 336 2 0 0.9881657 0.005952486 0.9997618 0.9767041
-
3 0.167 334 4 0 0.9763314 0.008468952 0.9926726 0.9602592
-
4 0.170 330 2 0 0.9704142 0.009497400 0.9886472 0.9525175
-
5 0.246 328 1 0 0.9674556 0.009976176 0.9865584 0.9487228
-
6 0.249 327 1 0 0.9644970 0.010435745 0.9844277 0.9449699
ggsurvplot()的survminer提供了估计的生存曲线的信息性说明。
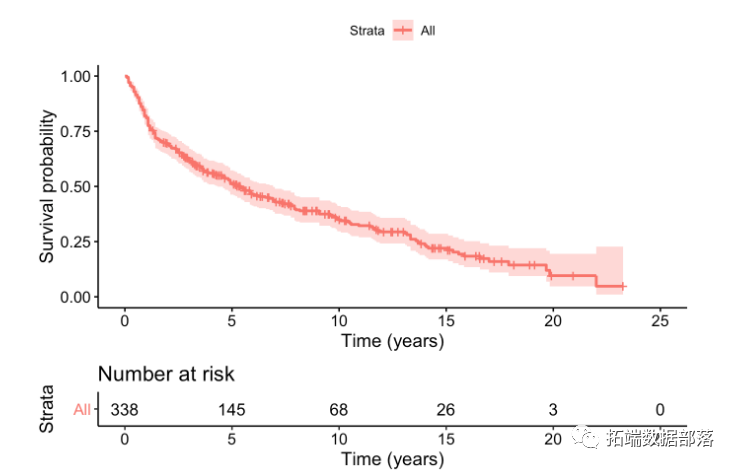
默认的KM图表显示了生存函数。
点击标题查阅往期内容

【视频】分类模型评估:精确率、召回率、ROC曲线、AUC与R语言生存分析时间依赖性ROC实现
左右滑动查看更多
01
02

03
04
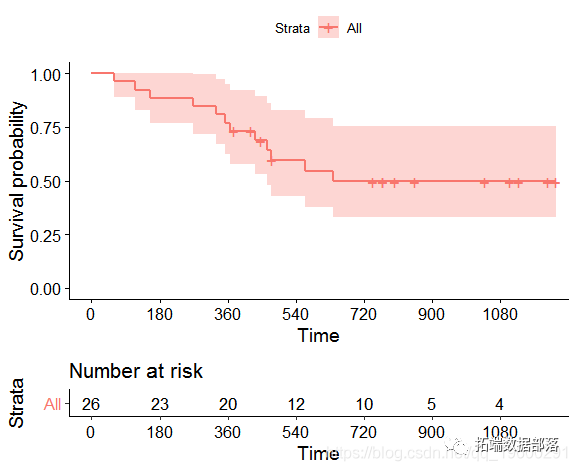
生存曲线估算
生存曲线在精算师和人口统计学中非常普遍。它特别适用于分组数据。
为了在实际示例中显示此方法,我们首先需要创建聚合数据,即将后续分组并在每个层中计算风险。
基于分组的数据,我们估计会用生存曲线。
-
nsubs nlost nrisk nevent surv pdf hazard se.surv se.pdf se.hazard
-
0-1 338 0 338.0 64 1.0000 0.1893 0.2092 0.0000 0.0213 0.0260
-
1-2 274 4 272.0 41 0.8107 0.1222 0.1630 0.0213 0.0179 0.0254
-
2-3 229 9 224.5 21 0.6885 0.0644 0.0981 0.0252 0.0136 0.0214
-
3-4 199 12 193.0 20 0.6241 0.0647 0.1093 0.0265 0.0140 0.0244
-
4-5 167 9 162.5 13 0.5594 0.0448 0.0833 0.0274 0.0121 0.0231
-
5-6 145 14 138.0 13 0.5146 0.0485 0.0989 0.0279 0.0131 0.0274
-
6-7 118 5 115.5 8 0.4662 0.0323 0.0717 0.0283 0.0112 0.0254
-
7-8 105 8 101.0 9 0.4339 0.0387 0.0933 0.0286 0.0126 0.0311
-
8-9 88 7 84.5 1 0.3952 0.0047 0.0119 0.0288 0.0047 0.0119
-
9-10 80 4 78.0 8 0.3905 0.0401 0.1081 0.0288 0.0137 0.0382
-
10-11 68 4 66.0 5 0.3505 0.0266 0.0787 0.0291 0.0116 0.0352
-
Nelson-Aalen估计
图形比较
可以绘制不同的生存函数估计值来评估潜在的差异。
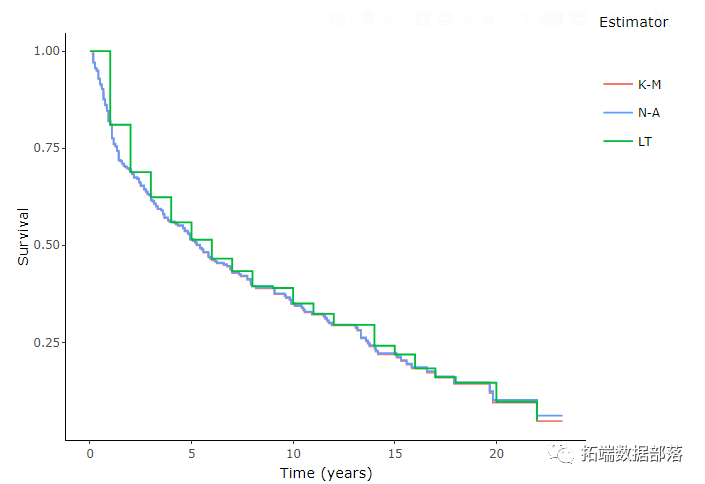
可以从估计的生存曲线导出诸如分位数的集中趋势的度量。
-
q km.quantile km.lower km.upper fh.quantile fh.lower fh.upper
-
25 0.25 1.333 1.084 1.834 1.333 1.084 1.747
-
50 0.50 5.418 4.331 6.916 5.418 4.244 6.913
-
75 0.75 13.673 11.748 16.580 13.673 11.748 15.833
估计半数人的寿命超过5.4年。
第一个四分之一的人在1.3年内死亡,而前四分之三的人的寿命超过1.3岁。
前三分之三的人在13.7年内死亡,而前四分之一的人死亡时间超过13.7岁。
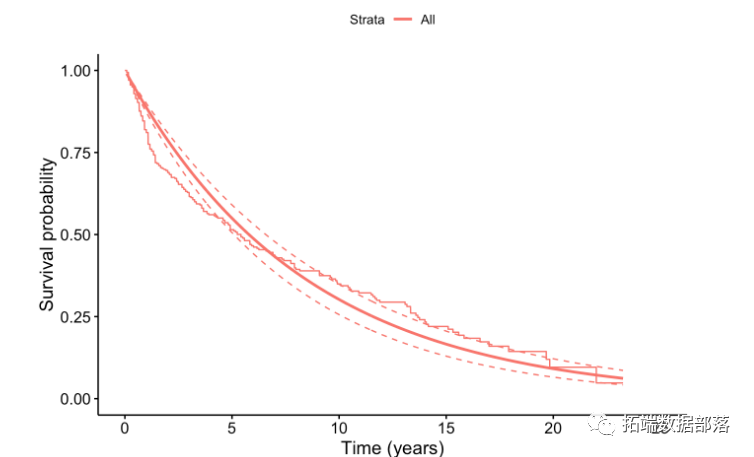
估计量的图形表示(基于使用KM的生存曲线)

参数估算
我们将考虑三种常见的选择:指数,Weibull和log-logistic模型。
-
flexsurvreg(formula = su_obj ~ 1, data = orca, dist = "exponential")
-
Estimates:
-
est L95% U95% se
-
rate 0.11967 0.10513 0.13621 0.00791
-
N = 338, Events: 229, Censored: 109
-
Total time at risk: 1913.673
-
Log-likelihood = -715.1802, df = 1
-
AIC = 1432.36
同样,可以用非参数估计图形地比较不同的方法
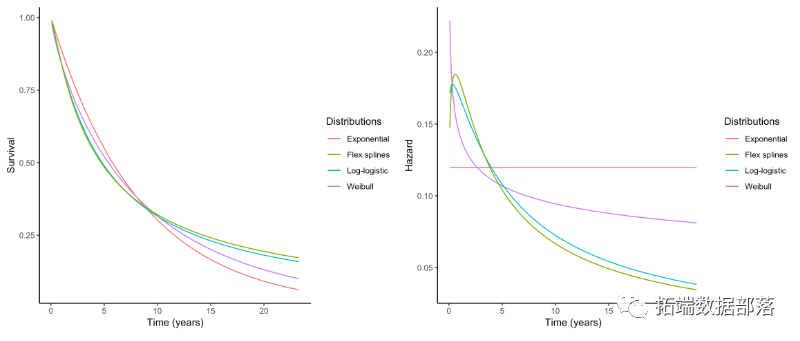
生存曲线的比较
例如,肿瘤阶段是癌症存活研究中的重要预后因素。我们可以估计和绘制不同颜色的不同组(阶段)的生存曲线。
-
stage D Y x pt rate lower upper conf.level
-
1 I 25 336.776 25 336.776 0.07423332 0.04513439 0.1033322 0.95
-
2 II 51 556.700 51 556.700 0.09161128 0.06646858 0.1167540 0.95
-
3 III 51 464.836 51 464.836 0.10971611 0.07960454 0.1398277 0.95
-
4 IV 57 262.552 57 262.552 0.21709985 0.16073995 0.2734597 0.95
-
5 unkn 45 292.809 45 292.809 0.15368380 0.10878136 0.1985862 0.95
通常,与具有高阶段肿瘤的患者相比,具有较低阶段肿瘤的诊断患者具有较低的(死亡率)。可以使用survfit()函数执行生存函数的整体比较。
-
Call: survfit(formula = su_obj ~ stage, data = orca)
-
n events median 0.95LCL 0.95UCL
-
stage=I 50 25 10.56 6.17 NA
-
stage=II 77 51 7.92 4.92 13.34
-
stage=III 72 51 7.41 3.92 9.90
-
stage=IV 68 57 2.00 1.08 4.82
-
stage=unkn 71 45 3.67 2.83 8.17
由于低肿瘤阶段的发病率较低,因此肿瘤分期增加的中位生存时间也会减少。可以观察到相同的行为,分别针对不同的肿瘤阶段绘制KM生存曲线。
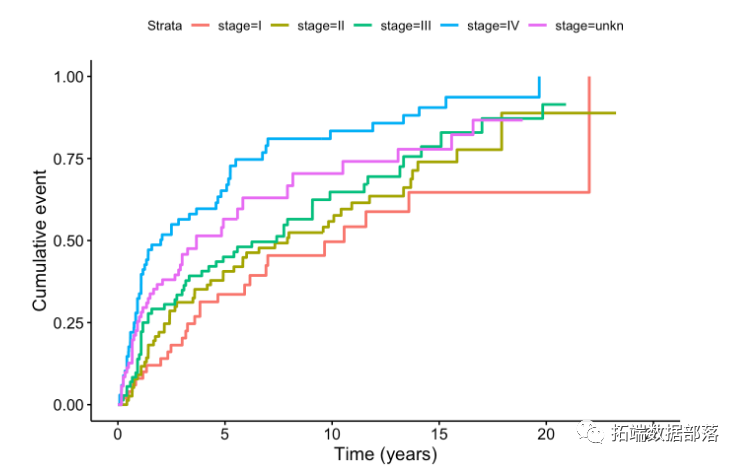
也可以为每个阶段级别构建整个生存表。这里是每个肿瘤阶段生存表的前3行。
# Groups: strata [5]
-
time n.risk n.event n.censor surv std.err upper lower strata
-
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <fct>
-
1 0.17 50 1 0 0.98 0.0202 1 0.942 I
-
2 0.498 49 1 0 0.96 0.0289 1 0.907 I
-
3 0.665 48 1 0 0.94 0.0357 1 0.876 I
-
4 0.419 77 1 0 0.987 0.0131 1 0.962 II
-
5 0.498 76 1 0 0.974 0.0186 1 0.939 II
-
6 0.665 75 1 0 0.961 0.0229 1 0.919 II
-
7 0.167 72 1 0 0.986 0.0140 1 0.959 III
-
8 0.249 71 1 0 0.972 0.0199 1 0.935 III
-
9 0.413 70 1 0 0.958 0.0246 1 0.913 III
-
10 0.085 68 2 0 0.971 0.0211 1 0.931 IV
-
11 0.162 66 1 0 0.956 0.0261 1 0.908 IV
-
12 0.167 65 1 0 0.941 0.0303 0.999 0.887 IV
-
13 0.162 71 1 0 0.986 0.0142 1 0.959 unkn
-
14 0.167 70 2 0 0.958 0.0249 1 0.912 unkn
-
15 0.17 68 1 0 0.944 0.0290 0.999 0.892 unkn

arrange_ggsurvplots(glist, print = TRUE, ncol = 2, nrow = 1)

Mantel-Haenszel logrank测试
默认参数rho = 0实现log-rank或Mantel-Haenszel测试。
Call:
-
survdiff(formula = su_obj ~ stage, data = orca)
-
N Observed Expected (O-E)^2/E (O-E)^2/V
-
stage=I 50 25 39.9 5.573 6.813
-
stage=II 77 51 63.9 2.606 3.662
-
stage=III 72 51 54.1 0.174 0.231
-
stage=IV 68 57 33.2 16.966 20.103
-
stage=unkn 71 45 37.9 1.346 1.642
-
Chisq= 27.2 on 4 degrees of freedom, p= 2e-05
-
Peto&Peto Gehan-Wilcoxon测试
-
survdiff(formula = su_obj ~ stage, data = orca, rho = 1)
-
N Observed Expected (O-E)^2/E (O-E)^2/V
-
stage=I 50 14.5 25.2 4.500 7.653
-
stage=II 77 29.3 39.3 2.549 4.954
-
stage=III 72 30.7 33.8 0.284 0.521
-
stage=IV 68 40.3 22.7 13.738 21.887
-
stage=unkn 71 32.0 25.9 1.438 2.359
-
Chisq= 30.9 on 4 degrees of freedom, p= 3e-06
-
不同的测试使用不同的权重来比较生存函数。在实际例子中,他们给出了可比较的结果,表明不同肿瘤阶段的生存函数是不同的。
建模生存数据
当比较因子水平的生存函数时,非参数检验特别可行。它们非常强大,高效,通常简单/直观。
然而,随着感兴趣因素的数量增加,非参数测试变得难以进行和解释。相反,回归模型对于探索生存与预测因子之间的关系更为灵活。
我们将介绍两种不同的广泛模型:半参数(即比例风险)和参数模型。
CoxPH模型
在我们的例子中,我们将考虑将死亡时间建模为性别,年龄和肿瘤阶段的函数。
可以使用coxph()功能来建立Cox比例风险模型survival。
summary(m1)
-
Call:
-
coxph(formula = su_obj ~ sex + I((age - 65)/10) + stage, data = orca)
-
n= 338, number of events= 229
-
coef exp(coef) se(coef) z Pr(>|z|)
-
sexMale 0.35139 1.42104 0.14139 2.485 0.012947
-
I((age - 65)/10) 0.41603 1.51593 0.05641 7.375 1.65e-13
-
stageII 0.03492 1.03554 0.24667 0.142 0.887421
-
stageIII 0.34545 1.41262 0.24568 1.406 0.159708
-
stageIV 0.88542 2.42399 0.24273 3.648 0.000265
-
stageunkn 0.58441 1.79393 0.25125 2.326 0.020016
-
exp(coef) exp(-coef) lower .95 upper .95
-
sexMale 1.421 0.7037 1.0771 1.875
-
I((age - 65)/10) 1.516 0.6597 1.3573 1.693
-
stageII 1.036 0.9657 0.6386 1.679
-
stageIII 1.413 0.7079 0.8728 2.286
-
stageIV 2.424 0.4125 1.5063 3.901
-
stageunkn 1.794 0.5574 1.0963 2.935
-
Concordance= 0.674 (se = 0.02 )
-
Rsquare= 0.226 (max possible= 0.999 )
-
Likelihood ratio test= 86.76 on 6 df, p=<2e-16
-
Wald test = 80.5 on 6 df, p=3e-15
-
Score (logrank) test = 82.86 on 6 df, p=9e-16
-
我们可以检查数据是否与每个变量的比例风险假设分别和全局一致。
rho chisq p
-
sexMale -0.00137 0.000439 0.983
-
I((age - 65)/10) 0.07539 1.393597 0.238
-
stageII -0.04208 0.411652 0.521
-
stageIII -0.06915 1.083755 0.298
-
stageIV -0.10044 2.301780 0.129
-
stageunkn -0.09663 2.082042 0.149
-
GLOBAL NA 4.895492 0.557
显然没有找到违反比例假设的证据。
Cox模型的结果表明性别,年龄和阶段的显着影响。特别是,每增加10年,死亡率就会增加50%。与男性和女性相比,全因死亡率的HR为1.42。此外,估计数中第一阶段和第二阶段之间未发现任何差异。因此,谨慎的做法是将这些主题从数据中排除,并将前两个阶段组合为一个。
round(ci.exp(m2), 4)
-
exp(Est.) 2.5% 97.5%
-
sexMale 1.3284 0.9763 1.8074
-
I((age - 65)/10) 1.4624 1.2947 1.6519
-
st3III 1.3620 0.9521 1.9482
-
st3IV 2.3828 1.6789 3.3818
显示和图形化比较多变量Cox模型的结果的便捷方式是通过森林图。
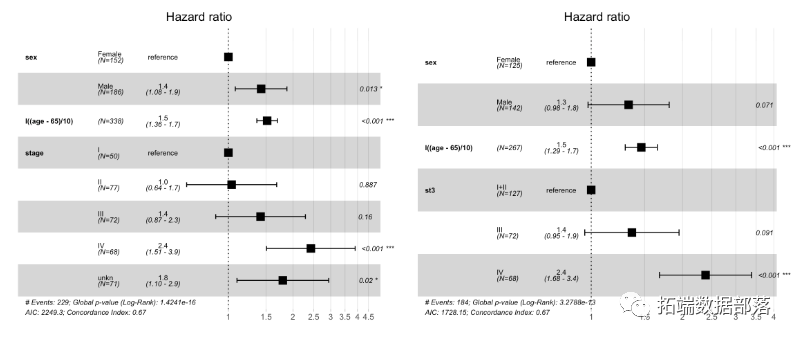
让我们逐步绘制预测的生存曲线,根据拟合的模型确定性别和年龄的值
newd
-
sex age st3 id
-
1 Male 40 I+II 1
-
2 Female 40 I+II 2
-
3 Male 80 I+II 3
-
4 Female 80 I+II 4
-
5 Male 40 III 5
-
6 Female 40 III 6
-
7 Male 80 III 7
-
8 Female 80 III 8
-
9 Male 40 IV 9
-
10 Female 40 IV 10
-
11 Male 80 IV 11
-
12 Female 80 IV 12
AFT模型
参数模型假设生存时间的分布。
-
Call:
-
flexsurvreg(formula = Surv(time, all) ~ sex + I((age - 65)/10) +
-
st3, data = orca2, dist = "weibull")
-
Estimates:
-
data mean est L95% U95% se exp(est) L95%
-
shape NA 0.93268 0.82957 1.04861 0.05575 NA NA
-
scale NA 13.53151 9.97582 18.35456 2.10472 NA NA
-
sexMale 0.53184 -0.33905 -0.66858 -0.00951 0.16813 0.71245 0.51243
-
I((age - 65)/10) -0.15979 -0.41836 -0.54898 -0.28773 0.06665 0.65813 0.57754
-
st3III 0.26966 -0.32567 -0.70973 0.05839 0.19595 0.72204 0.49178
-
st3IV 0.25468 -0.95656 -1.33281 -0.58030 0.19197 0.38421 0.26374
-
U95%
-
shape NA
-
scale NA
-
sexMale 0.99053
-
I((age - 65)/10) 0.74996
-
st3III 1.06012
-
st3IV 0.55973
-
N = 267, Events: 184, Censored: 83
-
Total time at risk: 1620.864
-
Log-likelihood = -545.858, df = 6
-
AIC = 1103.716
可以证明,假设指数或威布尔分布的AFT模型可以重新参数化为比例风险模型。
显示eha。
-
Call:
-
weibreg(formula = Surv(time, all) ~ sex + I((age - 65)/10) +
-
st3, data = orca2)
-
Covariate Mean Coef Exp(Coef) se(Coef) Wald p
-
sex
-
Female 0.490 0 1 (reference)
-
Male 0.510 0.316 1.372 0.156 0.043
-
I((age - 65)/10) -0.522 0.390 1.477 0.062 0.000
-
st3
-
I+II 0.551 0 1 (reference)
-
III 0.287 0.304 1.355 0.182 0.095
-
IV 0.162 0.892 2.440 0.178 0.000
-
log(scale) 2.605 13.532 0.156 0.000
-
log(shape) -0.070 0.933 0.060 0.244
-
Events 184
-
Total time at risk 1620.9
-
Max. log. likelihood -545.86
-
LR test statistic 68.7
-
Degrees of freedom 4
-
Overall p-value 4.30767e-14
-
系数的(指数)具有与Cox比例模型的系数的等效解释。
通过将参数提供fn给summary或plot方法,可以汇总或绘制拟合模型的参数的任何函数。例如,Weibull模型下的中位存活率可以概括为
-
newd <- data.frame(sex = c("Male", "Female"), age = 65, st3 = "I+II")
-
summary(m2w, newdata = newd, fn = median.weibull, t = 1, B = 10000)
-
-
sex=Male, I((age - 65)/10)=0, st3=I+II
-
time est lcl ucl
-
1 1 6.507834 4.898889 8.631952
-
sex=Female, I((age - 65)/10)=0, st3=I+II
-
time est lcl ucl
-
1 1 9.134466 6.801322 12.33771
将结果与Cox模型的结果进行比较。
survfit(m2, newdata = newd)
-
Call: survfit(formula = m2, newdata = newd)
-
n events median 0.95LCL 0.95UCL
-
1 267 184 7.00 5.25 10.6
-
2 267 184 9.92 7.33 13.8
泊松回归
可以证明,Cox模型在数学上等效于对数据的特定变换的泊松回归模型。
我们首先定义观察事件(all == 1)的唯一时间,并使用包中的survSplit()函数survival来分割数据。
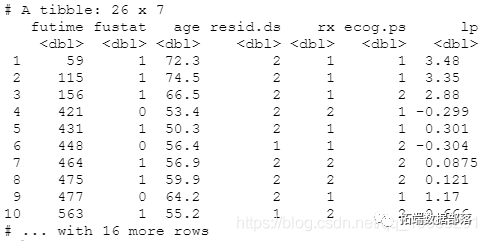
head(orca_splitted, 15)
拟合条件泊松回归,其中时间的影响(作为因子变量)可以被边缘化(不估计来提高计算效率)。
-
mod_poi <- gnm(all ~ sex + I((age-65)/10) + st3, data = orca_splitted,
-
family = poisson, eliminate = factor(time))
-
summary(mod_poi)
将从条件Poisson获得的估计值与cox比例风险模型进行比较。
round(data.frame(cox = ci.exp(m2), poisson = ci.exp(mod_poi)), 4)
-
cox.exp.Est.. cox.2.5. cox.97.5. poisson.exp.Est.. poisson.2.5. poisson.97.5.
-
sexMale 1.3284 0.9763 1.8074 1.3284 0.9763 1.8074
-
I((age - 65)/10) 1.4624 1.2947 1.6519 1.4624 1.2947 1.6519
-
st3III 1.3620 0.9521 1.9482 1.3620 0.9521 1.9482
-
st3IV 2.3828 1.6789 3.3818 2.3828 1.6789 3.3818
如果我们想要估计基线风险,我们还需要估计泊松模型中时间的影响。
-
orca_splitted$dur <- with(orca_splitted, time - tstart)
-
mod_poi2 <- glm(all ~ -1 + factor(time) + sex + I((age-65)/10) + st3,
-
data = orca_splitted, family = poisson, offset = log(dur))
基线风险包括阶梯函数,其中速率在每个时间间隔内是恒定的。
-
newd <- data.frame(time = cuts, dur = 1,
-
sex = "Female", age = 65, st3 = "I+II")
-
blhaz <- data.frame(ci.pred(mod_poi2, newdata = newd))
-
ggplot(blhaz, aes(x = c(0, cuts[-138]), y = Estimate, xend = cuts, yend = Estimate)) + geom_segment() +
-
scale_y_continuous(trans = "log", limits = c(.05, 5), breaks = pretty_breaks()) +
-
theme_classic() + labs(x = "Time (years)", y = "Baseline hazard")
-
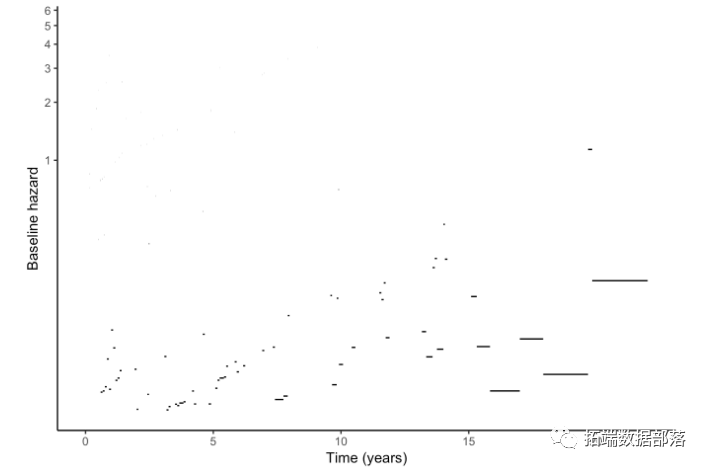
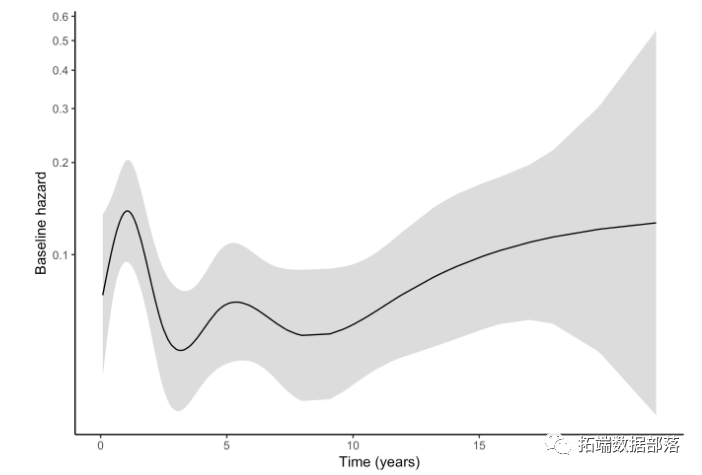
更好的方法是通过使用例如具有节点\(k \)的样条来灵活地模拟基线风险。
-
exp(Est.) 2.5% 97.5%
-
(Intercept) 0.074 0.040 0.135
-
ns(time, knots = k)1 0.402 0.177 0.912
-
ns(time, knots = k)2 1.280 0.477 3.432
-
ns(time, knots = k)3 0.576 0.220 1.509
-
ns(time, knots = k)4 1.038 0.321 3.358
-
ns(time, knots = k)5 4.076 0.854 19.452
-
ns(time, knots = k)6 1.040 0.171 6.314
-
sexMale 1.325 0.975 1.801
-
I((age - 65)/10) 1.469 1.300 1.659
-
st3III 1.360 0.952 1.942
-
st3IV 2.361 1.665 3.347
-
比较不同的策略
我们可以根据特定协变量模式的预测生存曲线比较之前的策略,如65岁的女性患有肿瘤I期或II期。
-
newd <- data.frame(sex = "Female", age = 65, st3 = "I+II")
-
生存函数的图形表示便于比较。
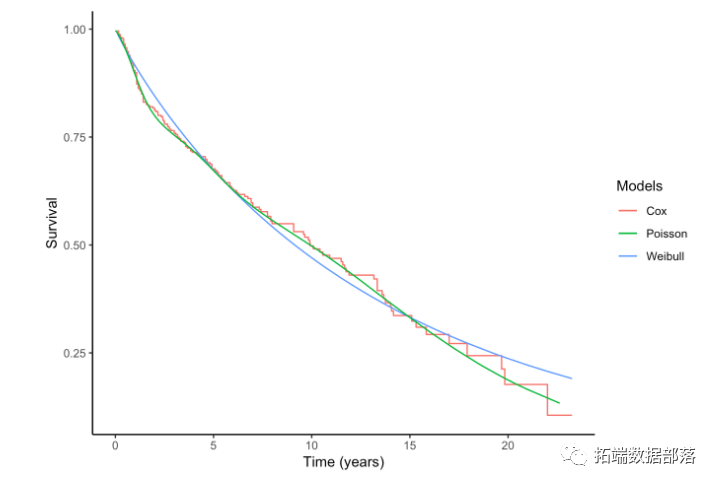
其他分析
非线性
我们假设年龄对(log)死亡率的影响是线性的。放宽这一假设的可能策略是拟合Cox模型,其中年龄用二次效应建模。
-
Call:
-
coxph(formula = Surv(time, all) ~ sex + I(age - 65) + I((age -
-
65)^2) + st3, data = orca2)
-
n= 267, number of events= 184
-
coef exp(coef) se(coef) z Pr(>|z|)
-
sexMale 2.903e-01 1.337e+00 1.591e-01 1.825 0.0681
-
I(age - 65) 3.868e-02 1.039e+00 6.554e-03 5.902 3.59e-09
-
I((age - 65)^2) 9.443e-05 1.000e+00 3.576e-04 0.264 0.7917
-
st3III 3.168e-01 1.373e+00 1.838e-01 1.724 0.0847
-
st3IV 8.691e-01 2.385e+00 1.787e-01 4.863 1.16e-06
-
exp(coef) exp(-coef) lower .95 upper .95
-
sexMale 1.337 0.7481 0.9787 1.826
-
I(age - 65) 1.039 0.9621 1.0262 1.053
-
I((age - 65)^2) 1.000 0.9999 0.9994 1.001
-
st3III 1.373 0.7284 0.9576 1.968
-
st3IV 2.385 0.4193 1.6801 3.385
-
Concordance= 0.674 (se = 0.022 )
-
Rsquare= 0.216 (max possible= 0.999 )
-
Likelihood ratio test= 64.89 on 5 df, p=1e-12
-
Wald test = 63.11 on 5 df, p=3e-12
-
Score (logrank) test = 67.64 on 5 df, p=3e-13
-
非线性(即二次项)的值很高,因此没有证据可以拒绝零假设(即线性假设是合适的)。
如果关系是非线性的,则年龄系数不再可以直接解释。我们可以将HR作为年龄的函数以图形方式呈现。我们需要指定一个指示值; 我们选择65岁的中位年龄值。
-
age <- seq(20, 80, 1) - 65
-
geom_vline(xintercept = 65, lty = 2) + geom_hline(yintercept = 1, lty = 2)
时间依赖系数
该cox.zph()函数可用于绘制个体预测因子随时间的影响,因此可用于诊断和理解非比例风险。

我们可以通过拟合的阶梯函数来放宽比例风险假设,这意味着在不同的时间间隔内有不同的
包中的survSplit()函数survival将数据集划分。
-
id sex age stage event st3 tstart time all tgroup
-
1 2 Female 83.08783 III Oral ca. death III 0 0.419 1 1
-
2 3 Male 52.59008 II Other death I+II 0 5.000 0 1
-
3 3 Male 52.59008 II Other death I+II 5 7.915 1 2
-
4 4 Male 77.08630 I Other death I+II 0 2.480 1 1
-
5 5 Male 80.33622 IV Oral ca. death IV 0 2.500 1 1
-
6 6 Female 82.58132 IV Other death IV 0 0.167 1 1
-
I((age - 65)/10) + st3, data = orca3)
-
coef exp(coef) se(coef) z p
-
I((age - 65)/10) 0.38184 1.46498 0.06255 6.104 1.03e-09
-
st3III 0.28857 1.33451 0.18393 1.569 0.1167
-
st3IV 0.87579 2.40076 0.17963 4.876 1.09e-06
-
relevel(sex, 2)Male:strata(tgroup)tgroup=1 0.42076 1.52312 0.19052 2.209 0.0272
-
relevel(sex, 2)Female:strata(tgroup)tgroup=1 NA NA 0.00000 NA NA
-
relevel(sex, 2)Male:strata(tgroup)tgroup=2 -0.10270 0.90240 0.28120 -0.365 0.7149
-
relevel(sex, 2)Female:strata(tgroup)tgroup=2 NA NA 0.00000 NA NA
-
relevel(sex, 2)Male:strata(tgroup)tgroup=3 1.13186 3.10142 1.09435 1.034 0.3010
-
relevel(sex, 2)Female:strata(tgroup)tgroup=3 NA NA 0.00000 NA NA
-
Likelihood ratio test=68.06 on 6 df, p=1.023e-12
-
n= 416, number of events= 184
虽然不显着,但男女比较的风险比在第二时期(5至15年)低于1,而在其他两个时期高于1。
模拟生存百分位数
一个不同但有趣的方法包括模拟生存时间的百分位数。
-
Call:
-
ctqr(formula = Surv(time, all) ~ st3, data = orca2, p = p)
-
Coefficients:
-
p = 0.25
-
(Intercept) 2.665
-
st3III -1.369
-
st3IV -1.877
-
Degrees of freedom: 267 total; 225 residuals
β0= 2.665 是参考组中死亡概率等于0.25的时间。另一个被解释为相对度量。
该信息可以直观地比较在肿瘤阶段的水平上分别估计的生存曲线。
-
p = c(p, p - .005, p + .005)
-
)[-1, ]
-
= 1 - p, xend = time_ref,
-
yend = 1 - p))

对Cox模型中评估生存时间百分位数的可能差异,作为诊断性别和肿瘤阶段年龄的函数。
-
ctqr(formula = Surv(time, all) ~ sex + I((age - 65)/10) + st3,
-
data = orca2, p = seq(0.1, 0.7, 0.1))
-
Coefficients:
-
p = 0.1 p = 0.2 p = 0.3 p = 0.4 p = 0.5 p = 0.6 p = 0.7
-
(Intercept) 1.44467 2.44379 4.65302 7.73909 10.81386 12.18348 15.19359
-
sexMale -0.09218 -0.27385 -0.85720 -2.49580 -3.27962 -2.81428 -4.01656
-
I((age - 65)/10) -0.19026 -0.39819 -1.20278 -1.93144 -2.39229 -3.03915 -3.52711
-
st3III -0.60994 -1.08534 -1.89357 -2.23741 -3.10478 -2.00037 -1.59213
-
st3IV -1.07679 -1.59566 -2.92700 -3.16652 -4.74759 -4.80838 -5.25810
-
Degrees of freedom: 267 total; 220 residuals
结果包括不同百分位数下每种协变量的生存时间差异。
-
coef_q <- data.frame(coef(fit_q)) %>%
-
.96 * se
-
)
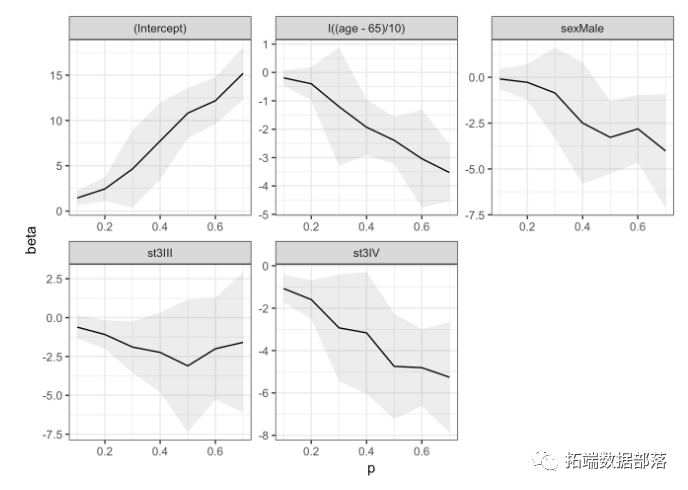
或者,可以针对一组特定的协方差模式预测生存时间的百分位数。
CIF累积发生率函数
在竞争风险情景中,Kaplan-Meier对特定原因生存的估计通常是不合适的。
我们将考虑事件的累积发生率函数(CIF)
CIF
mstate计算竞争事件的非参数CIF(也称为Aalen-Johansen估计)和相关的标准误差。
head(cif)
-
time Surv CI.Oral ca. death CI.Other death seSurv seCI.Oral ca. death
-
1 0.085 0.9925094 0.007490637 0.000000000 0.005276805 0.005276805
-
2 0.162 0.9887640 0.011235955 0.000000000 0.006450534 0.006450534
-
3 0.167 0.9812734 0.011235955 0.007490637 0.008296000 0.006450534
-
4 0.170 0.9775281 0.011235955 0.011235955 0.009070453 0.006450534
-
5 0.249 0.9737828 0.011235955 0.014981273 0.009778423 0.006450534
-
6 0.252 0.9662921 0.014981273 0.018726592 0.011044962 0.007434315
-
seCI.Other death
-
1 0.000000000
-
2 0.000000000
-
3 0.005276805
-
4 0.006450534
-
5 0.007434315
-
6 0.008296000
我们可以绘制CIF以及生存函数。
通过因子变量的水平来估计累积发生率函数 。
grid.arrange(
-
ncol = 2
-
)
我们可以看到,IV期口腔癌死亡的CIF高于III,甚至更高于I + II。相反,对于其他原因死亡率,曲线似乎不随肿瘤阶段而变化。
当我们想要在竞争风险设置中对生存数据进行建模时,有两种常见的策略可以解决不同的问题:
-
针对事件特定风险的Cox模型,例如,兴趣在于预测因素对死亡率的生物效应非常疾病。
-
当我们想要评估因子对事件总体累积发生率的影响时。
CIF Cox模型
round(ci.exp(m2haz2), 4)
-
exp(Est.) 2.5% 97.5%
-
sexMale 1.8103 1.1528 2.8431
-
I((age - 65)/10) 1.4876 1.2491 1.7715
-
st3III 1.2300 0.7488 2.0206
-
st3IV 1.6407 0.9522 2.8270
原因特异性Cox模型的结果与原因特异性CIF的图形表示一致,即肿瘤IV期仅是口腔癌死亡率的重要风险因素。年龄增加与两种原因的死亡率增加相关(口腔癌死亡率HR = 1.42,其他原因死亡率HR = 1.48)。仅根据其他原因死亡率观察到性别差异(HR = 1.8)。
CRR模型
crr()在cmprsk竞争风险的情况下,包中的函数可用于子分布函数的回归建模。
-
Call:
-
crr(ftime = time, fstatus = event, cov1 = model.matrix(m2), failcode = "Oral ca. death")
-
coef exp(coef) se(coef) z p-value
-
sexMale -0.0953 0.909 0.213 -0.447 6.5e-01
-
I((age - 65)/10) 0.2814 1.325 0.093 3.024 2.5e-03
-
st3III 0.3924 1.481 0.258 1.519 1.3e-01
-
st3IV 1.0208 2.775 0.233 4.374 1.2e-05
-
exp(coef) exp(-coef) 2.5% 97.5%
-
sexMale 0.909 1.100 0.599 1.38
-
I((age - 65)/10) 1.325 0.755 1.104 1.59
-
st3III 1.481 0.675 0.892 2.46
-
st3IV 2.775 0.360 1.757 4.39
-
Num. cases = 267
-
Pseudo Log-likelihood = -501
-
Pseudo likelihood ratio test = 31.4 on 4 df,
-
m2fg2 <- with(orca2, crr(time, event, cov1 = model.matrix(m2), failcode = "Other death"))
-
summary(m2fg2, Exp = T)
-
Competing Risks Regression
-
Call:
-
crr(ftime = time, fstatus = event, cov1 = model.matrix(m2), failcode = "Other death")
-
coef exp(coef) se(coef) z p-value
-
sexMale 0.544 1.723 0.2342 2.324 0.020
-
I((age - 65)/10) 0.197 1.218 0.0807 2.444 0.015
-
st3III 0.130 1.139 0.2502 0.521 0.600
-
st3IV -0.212 0.809 0.2839 -0.748 0.450
-
exp(coef) exp(-coef) 2.5% 97.5%
-
sexMale 1.723 0.580 1.089 2.73
-
I((age - 65)/10) 1.218 0.821 1.040 1.43
-
st3III 1.139 0.878 0.698 1.86
-
st3IV 0.809 1.237 0.464 1.41
-
Num. cases = 267
-
Pseudo Log-likelihood = -471
-
Pseudo likelihood ratio test = 9.43 on 4 df,
还有问题,联系我们!