全文下载链接:http://tecdat.cn/?p=24074
茶碱数据文件报告来自抗哮喘药物茶碱动力学研究的数据。给 12 名受试者口服茶碱,然后在接下来的 25 小时内在 11 个时间点测量血清浓度。
head(thdat)

此处,时间是从抽取样品时开始给药的时间(h),浓度是测得的茶碱浓度(mg/L),体重是受试者的体重(kg)。
12 名受试者在时间 0 时接受了 320 mg 茶碱。
让我们绘制数据,即浓度与时间的关系:
plot(data=theo.data2) +eo_ine(oaes(group=id))
数据的个体差异
我们还可以在 12 个单独的图上绘制 12 个单独的浓度分布图,
pl + geom\_line() + facet\_wrap(~id)

这12个人的模式是相似的:浓度首先在吸收阶段增加,然后在消除阶段减少。然而,我们清楚地看到这些曲线之间的一些差异,这不仅仅是由于残差造成的。我们看到病人吸收和消除药物的速度或多或少。
一方面,每个单独的特征将通过_非线性_ 药代动力学 (PK) 模型正确描述 。
另一方面,人口方法和混合效应模型的使用将使我们能够考虑这种 _个体间的变异性_。
将非线性模型拟合到数据
将非线性模型拟合到单个患者
让我们考虑本研究的第一个主题(id=1)
the.dat.dta$id==1 ,c("tme)\]
plot(data=teo1
我们可能想为这个数据拟合一个 PK 模型

其中 (yj,1≤j≤n) 是该受试者的 nn PK 测量值,f 是 PK 模型,ψ是该受试者的 PK 参数向量, (ej,1≤ j≤n)是残差。
对该数据写入具有一阶吸收和线性消除的单室模型
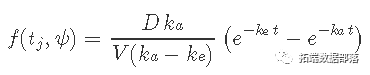
其中 ψ=(ka,V,ke) 是模型的 PK 参数,D 是给予患者的药物量(此处,D=320mg)。
让我们计算定义为 ψ 的最小二乘估计

我们首先需要实现PK模型:
pk.od <- function(pi, t){
D <- 320
ka
V
ke
f <- D\*a/V/(a-k)\*(exp(-e\*t)-exp(-k\*t))
然后我们可以使用该 nls 函数将此(非线性)模型拟合到数据
nls(neatin ~p.me1(psi, time)) coef(km1)
并绘制预测浓度 f(t,ψ^)
e. <- dafme(tm=sq(0,40,=.2)) w.pd1 <- pedct(pk, newaa=wdf) line(da=new., aes(x=tie,y=re1))
将独特的非线性模型拟合到几个患者上
与其将这个 PK 模型拟合到单个患者,我们可能希望将相同的模型拟合到所有患者:
其中(yij,1≤j≤ni)是受试者i的ni PK测量值。这里,ψ是N个受试者共享的PK参数的向量。
在该模型中,ψ 的最小二乘估计定义为
让我们将该nls 函数与来自 12 个受试者的合并数据一起使用 。
nls(ocetn ~ kme1(ps, tme)
nll <- predct(kmll, ewta=n.f) p+geom_line(ewd,astm,=rdal,clu="390" )
这些估计的 PK 参数是典型的 PK 参数,并且该 PK 曲线是该患者样本的典型 PK 曲线。
点击标题查阅往期内容
根据定义,它们没有考虑患者之间的变异性,因此不能提供良好的个体预测。
line(data=e.d, aes(x=im,y=pe.al)) + faetap(~ id)

将多个非线性模型拟合到多个患者
相反,我们可以为每个受试者拟合具有不同参数的相同 PK 模型,正是我们在上面对第一个患者所做的:

其中 ψi 是患者 ii 的 PK 参数向量。
在该模型中,ψi 的最小二乘估计定义为
for (i in (1:N)) {
pkmi <- nls(cocetatn ~ pk.mdl1(psi, time)
pred <- c(prd, prdit(kmi, neta=ewf))
}
每个个体预测浓度 f(t,ψ^i)似乎很好地预测了 12 个受试者的观察浓度:
nc <- lengh(nwdtie) tepred <- data.rame(d=rp(1:12),acc),tie=renew.fime12 fpre=pre) line(dta=te.re, aes(x=me,y=frd)) + factrp(id)
非线性混合效应 (NLME) 模型
第一个基本模型
到目前为止,单个参数 (ψi)被认为是固定效应:我们没有对可能的值做出任何假设。
在群体方法中,假设 N 受试者是从相同的个体群体中随机抽样的。然后,每个单独的参数 ψi 被视为一个随机变量。
我们将开始假设 ψi是独立且正态分布的:
其中 ψpop 是总体参数的 d 向量,Ω是 d×d方差-协方差矩阵。
备注: 这个正态性假设允许我们将每个单独的参数 ψi 分解为固定效应 ψpop 和随机效应 ηi:
其中 ηi∼iidN(0,Ω)。
我们还将开始假设残差 (eij)是独立且正态分布的:eij∼iidN(0,a2)。
总之,我们可以等效地表示一个(非线性)混合效应模型
i) 使用方程:

其中 eij∼iidN(0,a2) 和 ηi∼iidN(0,Ω),
ii) 或使用概率分布:

模型是(y,ψ)的联合概率分布,其中y=(yij,1≤i≤N,1≤j≤ni)是完整的观测集,ψ=(ψi,1≤i≤N) 单个参数的 N向量,

任务、方法和算法
总体参数的估计
模型参数为θ=(ψpop,Ω,a2)。θ的最大似然估计包括使_似然函数_相对于 θ 最大化, 定义为
如果f是ψi的非线性函数,那么yi就不是高斯向量,似然函数L(θ,y)就不能以封闭形式计算。
在非线性混合效应模型中存在几种最大似然估计的算法。特别是,随机近似EM算法(SAEM)是一种迭代算法,在一般条件下收敛到似然函数的最大值。
单个参数的估计
一旦θ被估计出来,条件分布p(ψi|yi;θ^)就可以用于每个个体i来估计个体参数向量ψi。
这个条件分布的模式被定义为
该估计称为 ψi 的最大后验 (MAP) 估计或经验贝叶斯估计 (EBE)。
备注: 由于 f 是 ψi的非线性函数,因此没有 ψ^i的解析表达式。然后应使用牛顿算法来执行此最小化问题。
然后我们可以使用条件模式来计算预测,采取的理念是各个参数的最可能值最适合计算最可能的预测。
似然函数的估计
对给定模型执行似然比检验和计算信息标准需要计算对数似然
对于非线性混合效应模型,不能以封闭形式计算对数似然。在连续数据的情况下,通过高斯线性模型近似模型允许我们近似对数似然。
实际上,我们可以将个体 i的观测值 (yij,1≤j≤ni)的模型线性化,该模型围绕预测的个体参数 ψ^i 的向量。
设∂ψf(t,ψ)是f(t,ψ)关于ψ的导数的行向量。然后,
在此之后,我们可以通过正态分布来近似向量 yi 的边缘分布:
其中

然后对数似然函数近似为

Fisher信息矩阵的估计
使用线性化模型,最大似然估计 (MLE) θ^ 的方差以及置信区间可以从观察到的 Fisher 信息矩阵 (FIM) 中导出,而 FIM 本身是从观察到的似然导出的:

然后可以通过观察到的 FIM 的逆来估计 θ^ 的方差-协方差矩阵。θ^ 的每个分量的标准误差 (se) 是标准偏差,即方差-协方差矩阵的对角元素的平方根。
对茶碱数据拟合 NLME 模型
让我们看看如何将我们的模型拟合到茶碱数据。
我们首先需要定义应该使用数据文件的哪一列以及它们的作用。在我们的示例中,浓度是因变量 yy,时间是解释变量(或预测变量)t,id 是分组变量。
Data(dta = data, grp = id", prditors = "time", repose = "con")
结构模型是以前使用的一阶吸收和线性消除的单室模型。
molct <- function(pi,id,x) {
D <- 320
fe <-D\*a/(V\*(a-e))*(exp(-e\*t)-exp(-a\*t))
需要人口参数向量ψpop的结构模型和一些初始值
Model(modl = moelpt, pi = c(a=1,V=20,ke=0.5))
可以定义几个选择和运行算法的选项,包括单个参数的估计 (map=TRUE)、Fisher 信息矩阵的估计和线性化对数似然 (fim=TRUE) 或重要性采样的对数似然(ll.is=TRUE)。
种子是用于随机数生成器的整数:使用相同的种子多次运行算法可确保结果相同。
list(map=TRUE,seed=632545) mix(model, dat,optns)
可以显示估计算法的结果摘要
results
还可以使用单个参数估计值
这些单独的参数估计可用于计算和绘制单独的预测
pred(fit1) plot.fit(fit1)
可以显示多个诊断拟合图,包括观察值与单个预测的图
pltobsv(fit1,lvl=1)
残差与时间和个人预测的关系图,
pltsateresi(fit1, levl=1)

模型的一些扩展
残差模型
在模型 yij=f(tij,ψi)+eij 中,假设残差 (eij)是均值为 0 的高斯随机变量。(eij)在非线性混合效应模型中的方差。
恒定误差模型:
残差 (eij) 是独立同分布的:

因此, yij 的方差随时间保持不变:

其中 εij∼iidN(0,1)。
误差模型可以定义为Model 的参数
Model(mo=md1p, p0=c(ka=1,V=20,ke=0.5), mdl="constant")
比例误差模型:
比例误差模型假设 eij的标准偏差与预测因变量成正比:eij= bf(tij,ψi)εij 其中 εij∼iidN(0,1)。然后,
Model(modl=dl1pt,error="prori")
组合误差模型:
组合误差模型将常数和比例误差模型相加组合:eij=(a+ bf(tij,ψi))εij其中 εij∼iidN(0,1)。然后,
Model(moel=d1ct, mde="bined")
指数误差模型:
如果已知 y 取非负值,则可以使用对数转换。然后我们可以用两个等效表示来编写模型:
Model( ero.dl="exp")

单个参数的变换
显然,并非所有分布都是高斯分布。首先,正态分布有支持度R,与许多在精确区间取值的参数不同。例如,有些变量只取正值(如体积和转移率常数),其他变量则被限制在有界区间内。
此外,高斯分布是对称的,这并不是所有分布都具有的属性。扩展使用高斯分布的一种方法是考虑我们感兴趣的参数的某种变换是高斯的。
即假设存在一个单调的函数h,使得h(ψi)是正态分布。为了简单起见,我们在这里将考虑一个标量参数ψi。然后我们假设

或者,等效地,

其中 ηi∼N(0,ω2)。
对数正态分布:
对数正态分布确保非负值,广泛用于描述生理参数的分布。
如果 ψi服从对数正态分布,则以下 3 种表示是等价的:
对数正态分布:
logit 函数定义在 (0,1)上并取其在 RR 中的值:对于 (0,1)中的任何 x,
具有 logit 正态分布的单个参数 ψi 在 (0,1)中取值。ψ 的 logit 服从正态分布,即,
概率正态分布:
probit函数是与标准正态分布N(0,1)相关的反累积分布函数(量化函数)ψ-1。对于(0,1)中的任何x。
具有概率正态分布的单个参数 ψi 在 (0,1) 中取值。ψi的概率呈正态分布:
每个单独参数的分布可以使用参数 transform.par 定义(0=normal,1=log-normal,2=probit,3=logit)。默认为正态分布,即向量为 0。
例如,如果我们想使用 V 的正态分布和 ka 和 ke 的对数正态分布,那么 par 应该是向量 c(1,0,1):
Model(model , psi , trns.par = c(1,0,1))
备注:这里,ω2ka和ω2ke是log(kai)和log(kei)的方差,而ω2V是Vi的方差。
带有协变量的模型
让ci=(ci1,ci2,...,ciL)为个体协变量的向量,即数据中可获得的个体参数的向量。我们可能想用这些协变量来解释非观察到的个体参数(ψi)的部分变异性。
我们将只考虑协变量的线性模型。更准确地说,假设 h(ψi) 是正态分布的,我们将 h(ψi)分解为固定效应和随机效应:
备注:如果协变量ci1, ..., ciL对人口中的典型个体来说为零,ψpop就是ψi的典型值。
让我们考虑一个模型,其中体积Vi是正态分布,是重量wi的线性函数。
假设人口中一个典型个体的体重是wpop,这个个体的预测体积不是β0,而是β0+βwpop。
如果我们使用中心体重wi-wpop,我们现在可以把模型写成
事实上,现在对一个典型个体的预测体积是Vpop。
假设我们决定在茶碱研究中使用70公斤作为典型体重。现在需要包括wi-70。
这里,只有体积 VV 是重量的函数。因此,协变量模型被编码为向量 (0,1,0)。
Model( trasf = c(1,0,1), covri = c(0,1,0))

这里,β^w70=0.33意味着重量增加1kg会导致预测的体积增加0.33l。
检验H0:βw70=0与H1:βw70≠0的P值为0.01,那么我们可以拒绝H0,并得出结论:预测的体积随着重量的增加而显著增加。
想象一下,我们现在用对数正态分布来表示体积Vi。现在是对数体积,它是转化后的重量的一个线性函数。
我们可以假设,例如,对数体积是中心对数重量的线性函数。
或者,等效地,
我们看到,使用这个模型,一个典型个体的预测体积是Vpop。
Data对象现在需要包括log(wi/70)这个协变量。
lw70 <- log(weight/70)
Data(data,
res=c("cerato"),
cova=c("lw70"))
协变量模型再次编码为(行)向量 (0,1,0),但变换现在对于三个参数编码为 1
Model( trans.pr = c(1,1,1), cor = c(0,1,0))

随机效应之间的相关性
到目前为止,随机效应被认为是不相关的,即矢量-协方差矩阵Ω是一个对角矩阵。
随机效应之间的相关性可以通过输入参数covari引入,这是一个大小等于模型中参数数量的方形矩阵,给出了模型的方差-协方差结构。1s对应于估计的方差(在对角线上)或协方差(非对角线元素)。矩阵Ω的结构应该是块状的。
例如,考虑一个模型,其中ka在人群中是固定的,即ωka=0(因此对所有i来说kai=0),而log(V)和log(ke)是相关的,即ηV和ηke)是相关的。
Model( covai = t(c(0,1,0)), covain = matrix(c(0,0,0,0,1,1,0,1,1),nrow=3))


本文摘选《R语言非线性混合效应 NLME模型(固定效应&随机效应)对抗哮喘药物茶碱动力学研究》,点击“阅读原文”获取全文完整资料。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!
点击标题查阅往期内容
R语言用线性混合效应(多水平/层次/嵌套)模型分析声调高低与礼貌态度的关系
R语言nlme、nlmer、lme4用(非)线性混合模型non-linear mixed model分析藻类数据实例
R语言混合线性模型、多层次模型、回归模型分析学生平均成绩GPA和可视化
R语言线性混合效应模型(固定效应&随机效应)和交互可视化3案例
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型