全文下载链接:http://tecdat.cn/?p=24057
本文的目标是使用K-最近邻(K近邻),ARIMA和神经网络模型分析Google股票数据集(查看文末了解数据获取方式)预测Google的未来股价,然后分析各种模型。
K-最近邻(K近邻)是一种用于回归和分类的监督学习算法。K近邻 试图通过计算测试数据与所有训练点之间的距离来预测测试数据的正确类别。然后选择最接近测试数据的K个点。K近邻算法计算测试数据属于'K'个训练数据的类的概率,并且选择概率最高的类。在回归的情况下,该值是“K”个选定训练点的平均值。

让我们看看下面的例子,以便更好地理解
为什么我们需要 K近邻 算法?
假设有两个类别,A 和B,并且我们有一个新的数据点x1,那么这个数据点将位于这些类别中的哪一个。为了解决这类问题,我们需要一个K近邻算法。借助K近邻,我们可以轻松识别特定数据集的类别。考虑下图:

K近邻 是如何工作的?
K近邻 的工作原理可以根据以下算法进行解释:
-
步骤1:选择邻居的数量K
-
步骤2:计算K个邻居的欧几里得距离
-
步骤3:根据计算出的欧几里得距离取K个最近邻。
-
步骤4:在这k个邻居中,统计每个类别的数据点个数。
-
步骤 5:将新数据点分配给邻居数量最大的类别。
-
步骤6:我们的模型准备好了。
假设我们有一个新的数据点,我们需要把它放在所需的类别中。
首先,我们将选择邻居的数量,因此我们将选择 k=5。
接下来,我们将计算数据点之间的欧几里得距离。欧几里得距离是两点之间的距离,我们已经在几何学中研究过。可以计算为:
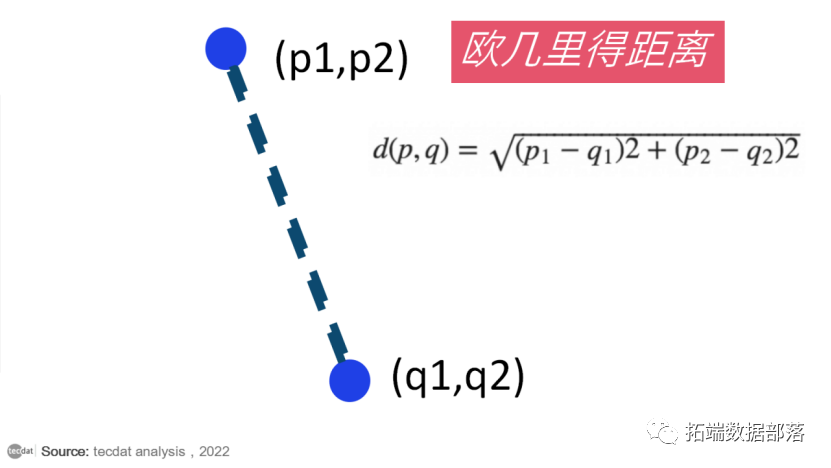
通过计算欧几里得距离,我们得到了最近邻,即 A 类中的2个最近邻和 B 类中的3个最近邻。
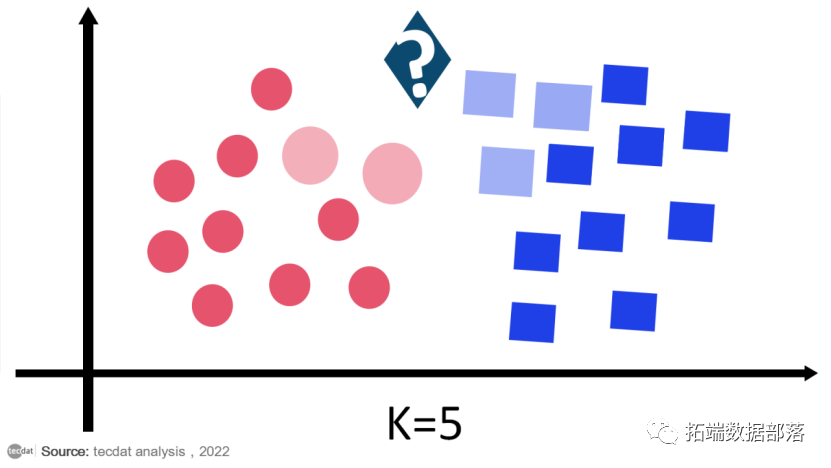
正如我们所见,3 个最近的邻居来自类别B,因此这个新数据点必须属于类别B。

如何选择 K 值?
Kvalue 表示最近邻的计数。我们必须计算测试点和训练过的标签点之间的距离。每次迭代更新距离度量的计算成本很高,这就是为什么 K近邻 是一种惰性学习算法。
那么如何选择最优的K值呢?
-
没有预先定义的统计方法来找到最有利的 K 值。
-
初始化一个随机的 K 值并开始计算。
-
选择较小的 K 值会导致决策边界不稳定。
-
较大的 K 值更适合分类,因为它可以平滑决策边界。
-
得出错误率和 K 之间的图,表示定义范围内的值。然后选择K值作为具有最小错误率。
现在您将了解通过实施模型来选择最佳 K 值。
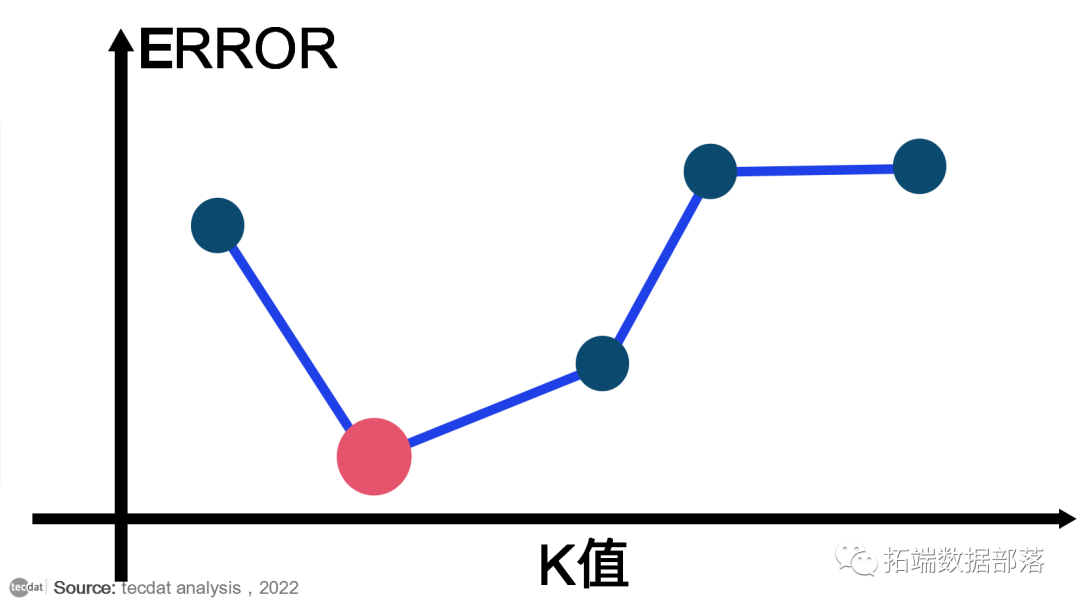
计算距离:
第一步是计算新点和每个训练点之间的距离。计算该距离有多种方法,其中最常见的方法是欧几里得、曼哈顿(用于连续)和汉明距离(用于分类)。
欧几里得距离:欧几里得距离计算为新点 (x) 和现有点 (y) 之间的平方差之和的平方根。
曼哈顿距离:这是实际向量之间的距离,使用它们的绝对差之和。
结合新冠疫情COVID-19对股票价格预测:ARIMA,KNN和神经网络时间序列分析
1.概要
本文的目标是使用各种预测模型分析Google股票数据集(查看文末了解数据获取方式)预测Google的未来股价,然后分析各种模型。
拓端
,赞27
拓端
,赞17
拓端
,赞13
2.简介
预测算法是一种试图根据过去和现在的数据预测未来值的过程。提取并准备此历史数据点,来尝试预测数据集所选变量的未来值。在市场历史期间,一直有一种持续的兴趣试图分析其趋势,行为和随机反应。不断关注在实际发生之前先了解发生了什么,这促使我们继续进行这项研究。我们还将尝试并了解 COVID-19对股票价格的影响。
3.所需包
library(quantmod) R的定量金融建模和交易框架 library(forecast) 预测时间序列和时间序列模型 library(tseries) 时间序列分析和计算金融。 library(timeseries) 'S4'类和金融时间序列的各种工具。 library(readxl) readxl包使你能够轻松地将数据从Excel中取出并输入R中。 library(kableExtra) 显示表格 library(data.table) 大数据的快速聚合 library(DT) 以更好的方式显示数据 library(tsfknn) 进行KNN回归预测
4.数据准备
4.1导入数据
我们使用Quantmod软件包获取了Google股票价格2015年1月1日到2020年4月24日的数据,用于我们的分析。为了分析COVID-19对Google股票价格的影响,我们从quantmod数据包中获取了两组数据。
-
首先将其命名为data\_before\_covid,其中包含截至2020年2月28日的数据。
-
第二个名为data\_after\_covid,其中包含截至2020年4月24日的数据。
所有分析和模型都将在两个数据集上进行,以分析COVID-19的影响(如果有)。
getSymbols("GOG" fro= "2015-01-01", to = "2019-02-28")
before_covid <-dafae(GOOG)
getSymbols("GOG" , frm = "2015-01-01")
after_covid <- as.tae(GOOG)
4.2数据的图形表示
par(mfrow = c(1,2)) plot.ts(fore_c)
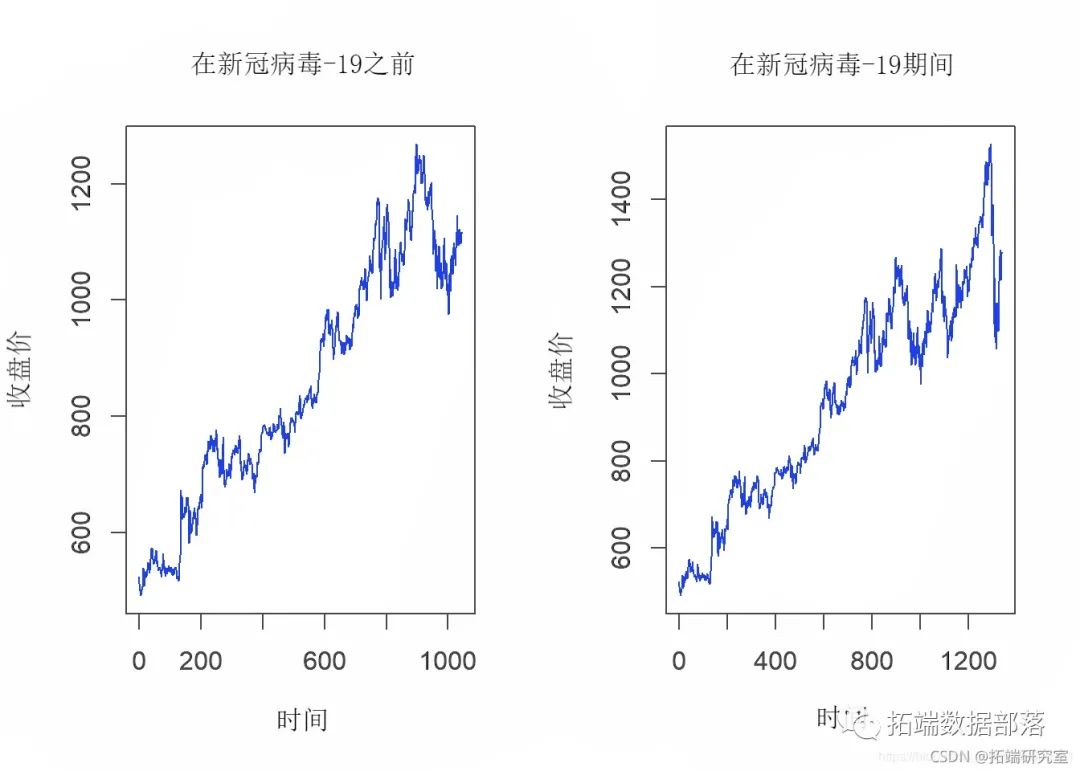
4.3数据集预览
最终数据集可以在下面的交互式表格中找到。
table(before_covid)
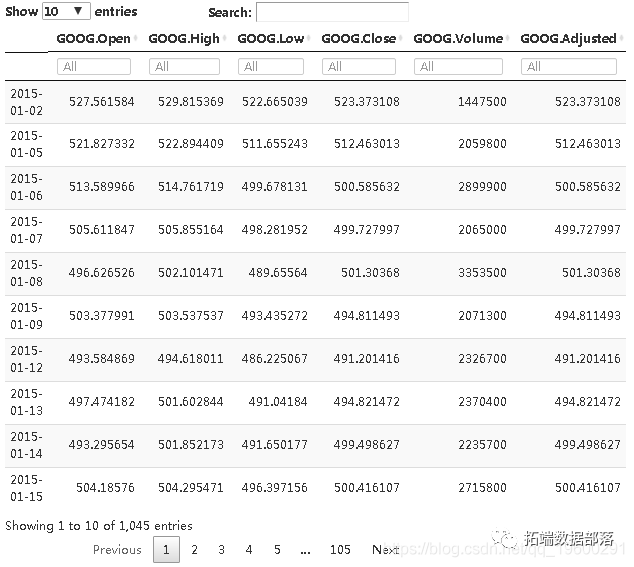
4.4变量汇总
| 变量 | 描述 |
|---|---|
| Open | 当日股票开盘价 |
| High | 当日股票最高价 |
| Low | 当日股价最低 |
| Close | 当日股票收盘价 |
| Volumn | 总交易量 |
| Adjusted | 调整后的股票价格,包括风险或策略 |
5. ARIMA模型
我们首先分析两个数据集的ACF和PACF图。
par(mfrow = c(2,2)) acft(bfoe_covid) pacf(bfre_covid)
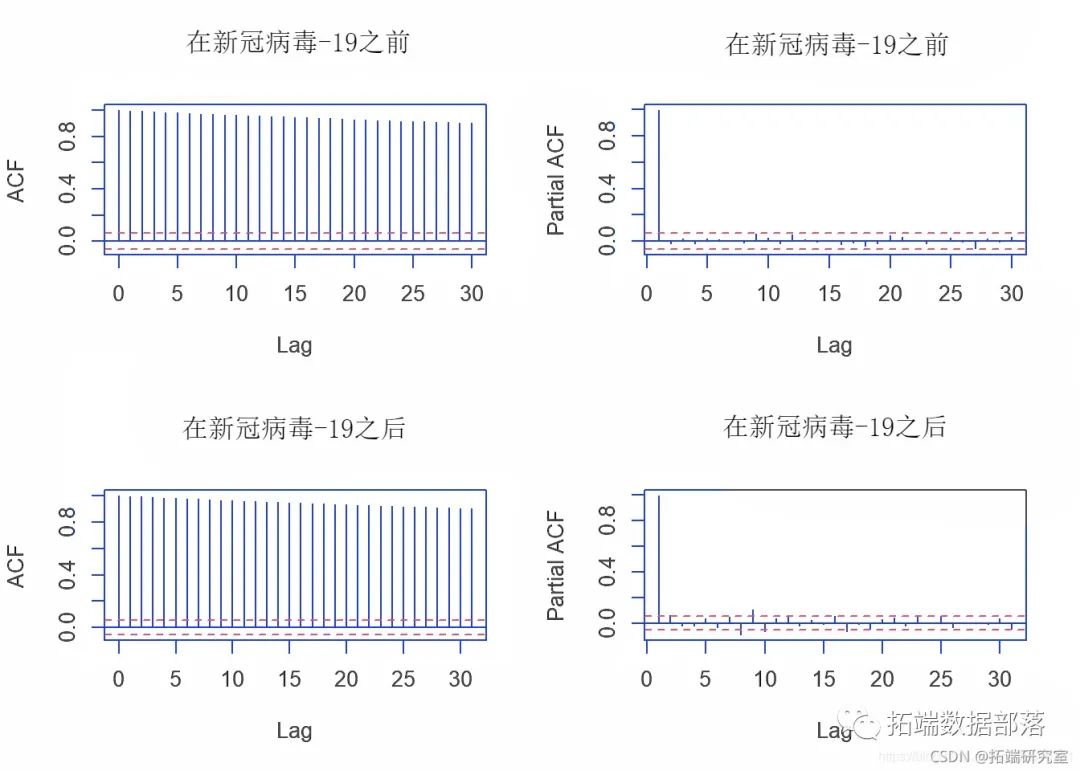
然后,我们进行 ADF(Dickey-Fuller) 检验和 KPSS(Kwiatkowski-Phillips-Schmidt-Shin) 检验,检验两个数据集收盘价的时间序列数据的平稳性。
print(adf.test)

print(adfes(sata\_after\_covid))

通过以上ADF检验,我们可以得出以下结论:
-
对于COVID-19之前的数据集,ADF测试给出的p值为 0.2093,该值大于0.05,因此说明时间序列数据 不是平稳的。
-
对于COVID-19之后的数据集,ADF测试给出的p值为0.01974,该值 小于0.05,这说明时间序列数据是 平稳的。
print(kpss.s(t\_before\_covid))

print(kpss.est(Dafter_covid))

通过以上KPSS测试,我们可以得出以下结论:
-
对于COVID-19之前的数据集,KPSS测试得出的p值为 0.01,该值小于0.05,因此说明时间序列数据 不是平稳的。
-
对于COVID-19之后的数据集,KPSS测试给出的p值为 0.01,该值小于0.05,这说明时间序列数据 不是平稳的。
因此,我们可以从以上两个测试得出结论,时间序列数据 不是平稳的。
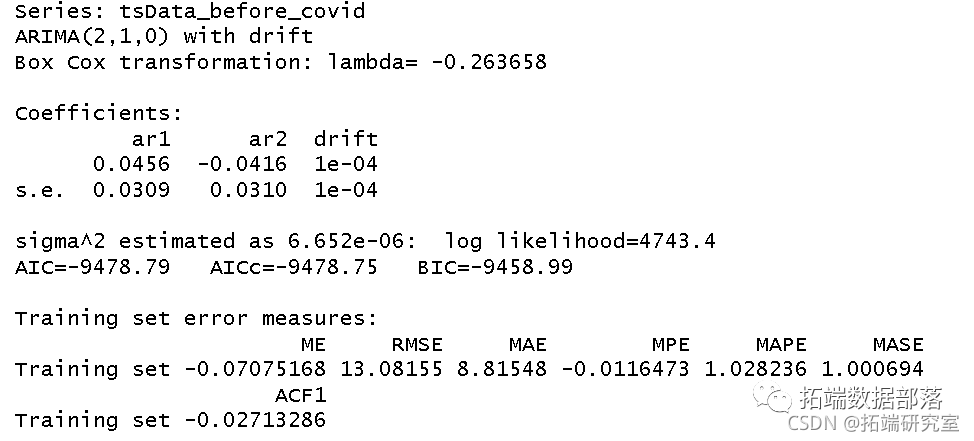
然后,我们使用 auto 函数来确定每个数据集的时间序列模型。
auto.ar(befor_covid, lamd = "auto")
auto.arma(after_covid)
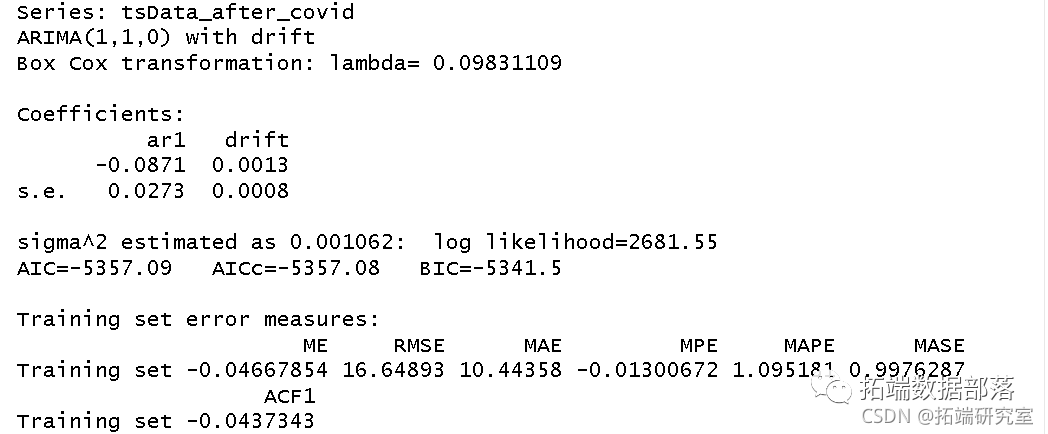
从auto函数中,我们得出两个数据集的以下模型:
-
在COVID-19之前:ARIMA(2,1,0)
-
在COVID-19之后:ARIMA(1,1,1)
获得模型后,我们将对每个拟合模型执行残差诊断。
par(mfrow = c(2,3)) plot(before_covidresiduals) plot(mfter_covidresiduals)
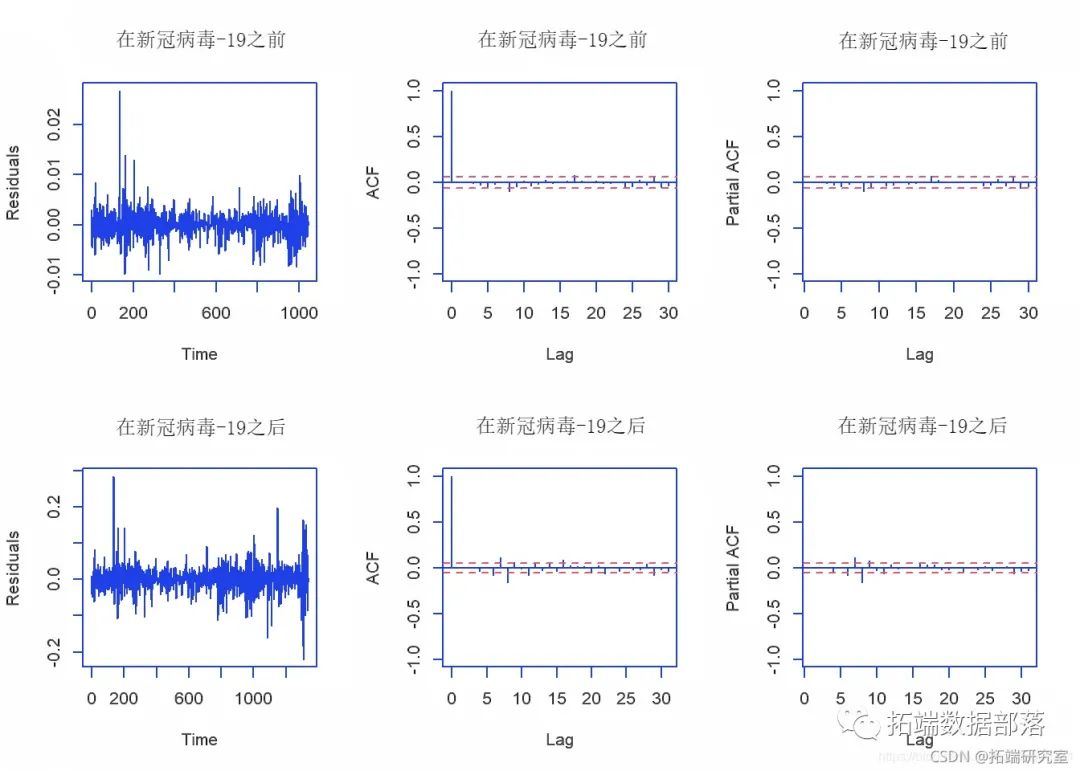
从残差图中,我们可以确认残差的平均值为0,并且方差也为常数。对于滞后> 0,ACF为0,而PACF也为0。
因此,我们可以说残差表现得像白噪声,并得出结论:ARIMA(2,1,0)和ARIMA(1,1,1)模型很好地拟合了数据。或者,我们也可以使用Box-Ljung检验在0.05的显着性水平上进行检验残差是符合白噪声。
Box.test(moderesiduals)

Box.tst(moeit\_fter\_covidreia, type = "Ljung-Box")

在此,两个模型的p值均大于0.05。因此,在显着性水平为0.05的情况下,我们无法拒绝原假设,而得出的结论是残差遵循白噪声。这意味着该模型很好地拟合了数据。
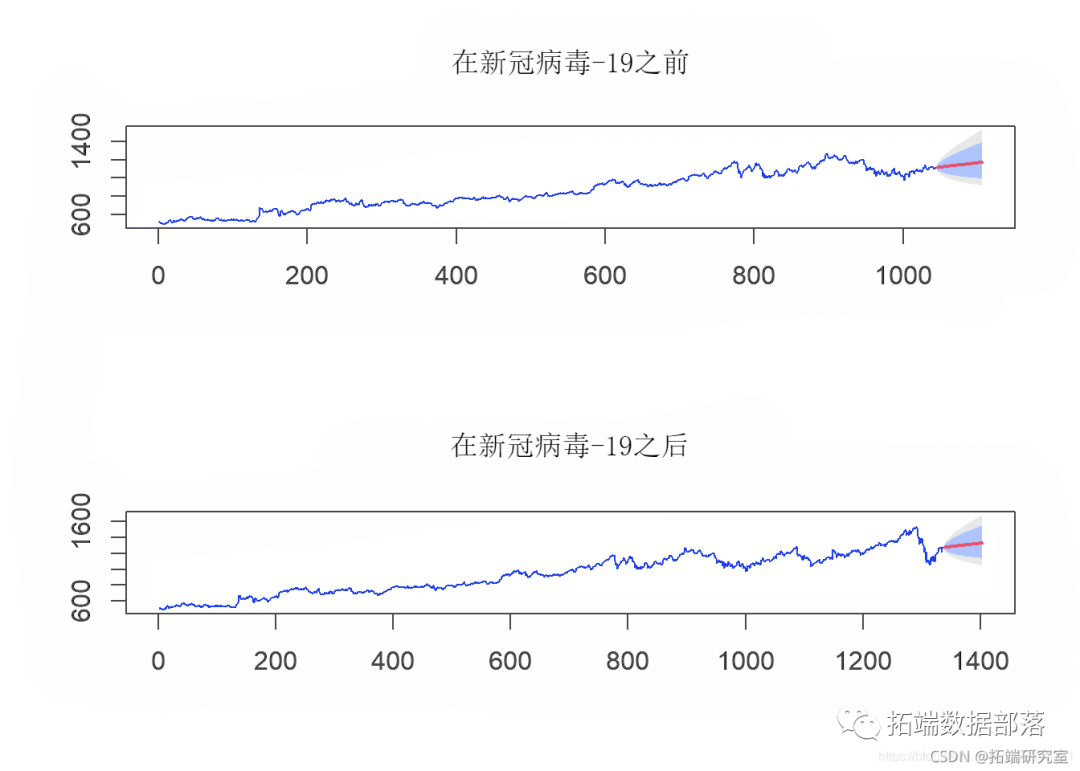
一旦为每个数据集确定了模型,就可以预测未来几天的股票价格。
点击标题查阅往期内容

自然语言处理NLP:主题LDA、情感分析疫情下的新闻文本数据
左右滑动查看更多
01
02

03

04

6. KNN回归时间序列预测模型
KNN模型可用于分类和回归问题。最受欢迎的应用是将其用于分类问题。现在,使用r软件包,可以在任何回归任务应用KNN。这项研究的目的是说明不同的预测工具,对其进行比较并分析预测的行为。在我们的KNN研究之后,我们提出可以将其用于分类和回归问题。为了预测新数据点的值,模型使用“特征相似度”,根据新点与训练集上点的相似程度为值分配新点。
第一项任务是确定我们的KNN模型中的k值。选择k值的一般经验法则是取样本中数据点数的平方根。因此,对于COVID-19之前的数据集,我们取k = 32;对于COVID-19之后的数据集,我们取k = 36。
par(mfrow = c(2,1)) knn\_before\_covid <- kn(bfrvdGO.Clse, k = 32) knn\_after\_covid <- kn(ber_oiGOG.lose ,k = 36) plot(knn\_before\_covid ) plot(knn\_after\_covid )
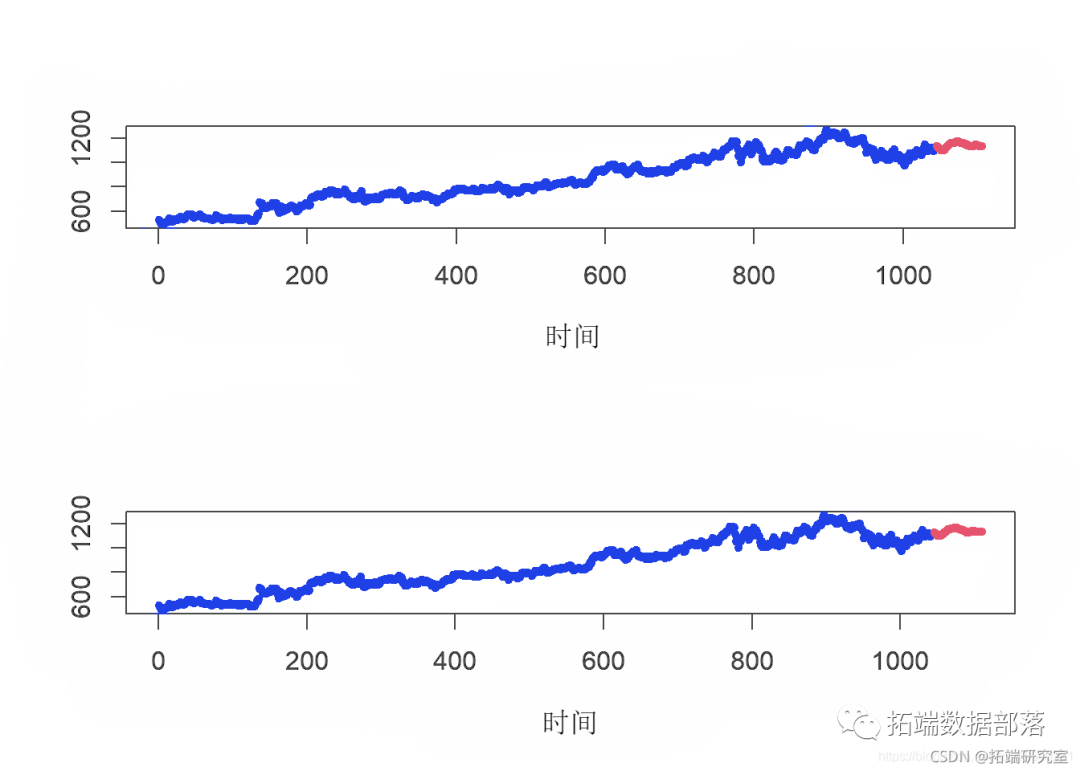
然后,我们针对预测时间序列评估KNN模型。
before\_cvid <- ll\_ig(pdn\_befr\_vid) afer\_vd<- rog\_ogn(redkn\_afer\_vd)

7.前馈神经网络建模
我们将尝试实现的下一个模型是带有神经网络的预测模型。在此模型中,我们使用单个隐藏层形式,其中只有一层输入节点将加权输入发送到接收节点的下一层。预测函数将单个隐藏层神经网络模型拟合到时间序列。函数模型方法是将时间序列的滞后值用作输入数据,以达到非线性自回归模型。
第一步是确定神经网络的隐藏层数。尽管没有用于计算隐藏层数的特定方法,但时间序列预测遵循的最常见方法是通过计算使用以下公式:
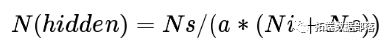
其中Ns:训练样本数Ni:输入神经元数No:输出神经元数a:1.5 ^ -10
#隐藏层的创建 hn\_before\_covid <- length(before.Close)/(alpha*(lengthGOOG.Close + 61) hn\_after\_covid <- length(after\_covidClose)/(alpha*(lengthafter\_ovdClose+65)) #拟合nn nn(before\_covid$GOOG.Close, size = hn\_beoe_cid, # 使用nnetar进行预测。 forecast(befe_cvid, h 61, I =UE) forecast(aftr_coid, h = 5, I = RE)
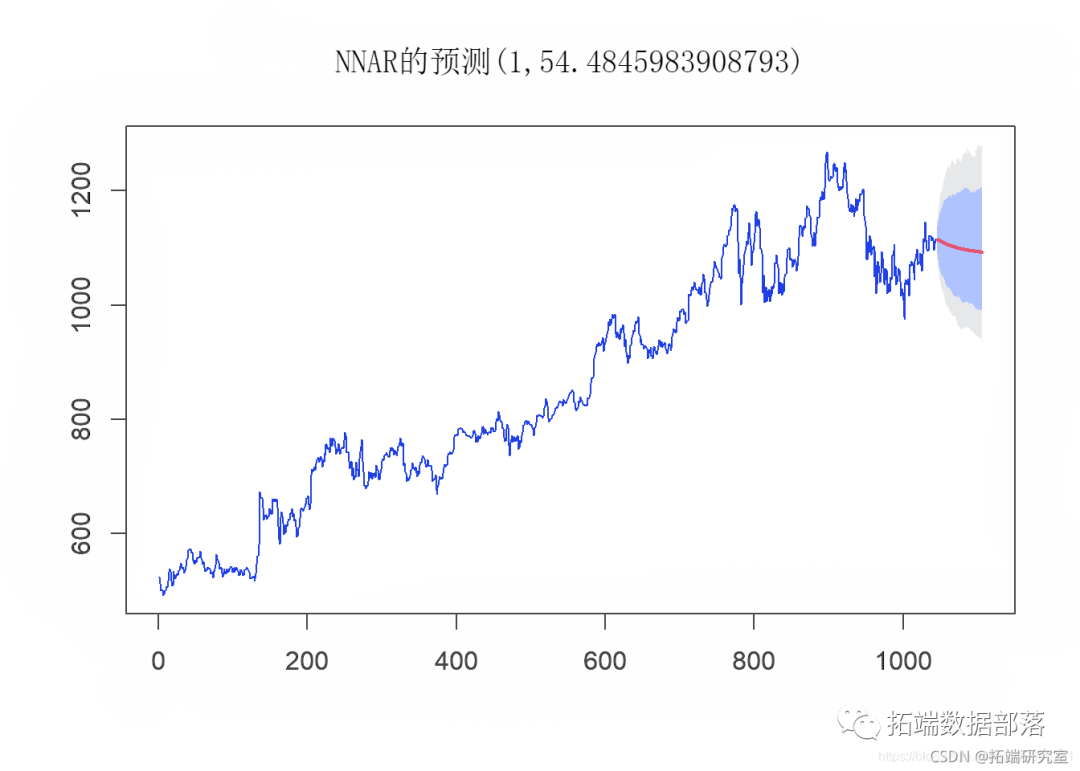
plot(nn\_fcst\_afte_cvid)
然后,我们使用以下参数分析神经网络模型的性能:
accuracy

accuracy

8.所有模型的比较
现在,我们使用参数诸如RMSE(均方根误差),MAE(均值绝对误差)和MAPE(均值绝对百分比误差)对所有三个模型进行分析 。
sumary\_le\_efore_oid <- data.frame(RMSE = nuerc(), MAE = uer(), MAPE = numric(), snsAsacrs = FALSE) summ\_tabe\_fter_ovd <- data.fame(RMSE = umeri(), MAE = nmei(), MAPE = numeic()) kable(smary\_abe\_eor_oid )
| 模型 | RMSE | MAE | MAPE |
|---|---|---|---|
| ARIMA | 13.0 | 8.8 | 1.0 |
| KNN | 44.0 | 33.7 | 3.1 |
| 神经网络 | 13.0 | 8.7 | 1.0 |
kable(sumary\_tbl\_aft_ci fulith = F, fixdtead = T )
| 模型 | RMSE | MAE | MAPE |
|---|---|---|---|
| ARIMA | 16.6 | 10.4 | 1.0 |
| KNN | 45.9 | 35.7 | 3.3 |
| 神经网络 | 14.7 | 9.8 | 1.0 |
因此,从以上模型性能参数的总结中,我们可以看到神经网络模型在两个数据集上的性能均优于ARIMA和KNN模型。因此,我们将使用神经网络模型来预测未来两个月的股价。
9.最终模型:COVID-19之前
现在,我们使用直到2月的数据来预测3月和4月的值,然后将预测价格与实际价格进行比较,以检查是否由于COVID-19可以归因于任何重大影响。
foestdungcvid<- datafame("De
"Actua Values" =
datatable(foestdungcvid, ilte= 'to')

从表中我们可以看到,3月和4月期间,Google股票的实际价值通常比预测值要高一些。因此,可以说,尽管发生了这种全球性大流行,但Google股票的表现仍然相当不错。
10.最终模型:COVID-19之后
现在,我们使用直到4月的数据预测5月和6月的值,以了解Google的未来股价。
foreataov <- data.frae(dn_reataeimean ) table(foreataov )
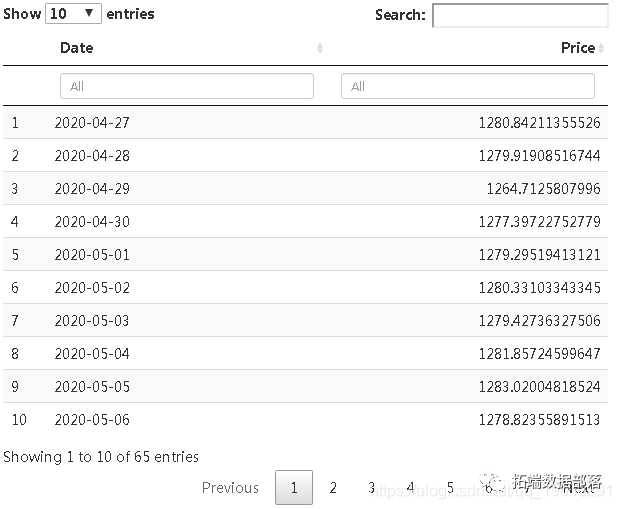
从表中可以得出结论,在5月和6月的接下来的几个月中,Google股票的价格将继续上涨并表现良好。
数据获取
在下面公众号后台回复“股票数据”,可获取完整数据。

本文摘选《R语言结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析》,点击“阅读原文”获取全文完整资料。
点击标题查阅往期内容
Fama French (FF) 三因子模型和CAPM模型分析股票市场投资组合风险/收益可视化
用COPULA模型进行蒙特卡洛(MONTE CARLO)模拟和拟合股票收益数据分析
金融时间序列模型ARIMA 和GARCH 在股票市场预测应用
时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
自然语言处理NLP:主题LDA、情感分析疫情下的新闻文本数据
R语言ARIMA-GARCH波动率模型预测股票市场苹果公司日收益率时间序列
R语言中的时间序列分析模型:ARIMA-ARCH / GARCH模型分析股票价格
R语言用综合信息准则比较随机波动率(SV)模型对股票价格时间序列建模
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化
R语言时变波动率和ARCH,GARCH,GARCH-in-mean模型分析股市收益率时间序列
R语言中的copula GARCH模型拟合时间序列并模拟分析
R语言ARMA-GARCH-COPULA模型和金融时间序列案例
Python使用GARCH,EGARCH,GJR-GARCH模型和蒙特卡洛模拟进行股价预测
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
matlab实现MCMC的马尔可夫转换ARMA - GARCH模型估计
Python使用GARCH,EGARCH,GJR-GARCH模型和蒙特卡洛模拟进行股价预测
使用R语言对S&P500股票指数进行ARIMA + GARCH交易策略
R语言用多元ARMA,GARCH ,EWMA, ETS,随机波动率SV模型对金融时间序列数据建模
R语言股票市场指数:ARMA-GARCH模型和对数收益率数据探索性分析