全文链接:http://tecdat.cn/?p=20650
原文出处:拓端数据部落公众号
视频|分类模型评估:精确率、召回率、ROC曲线、AUC与R语言生存分析时间依赖性ROC实现
分类模型评估精确率、召回率、ROC曲线、AUC与R语言生存分析时间依赖性ROC实现
- ROC曲线是什么?
- 曲线下的面积是多少?
- 二元分类的决策阈值是多少?
- 分类模型可接受的 AUC值是多少?
- 什么是精确召回曲线?
- 什么时候应该使用精确召回和 ROC 曲线?
什么是ROC曲线?
如果你用搜索 ROC 曲线,你会得到以下答案:
“接受者操作特征曲线或 ROC 曲线是一个图形,它说明了二元分类器系统在其区分阈值变化时的诊断能力。”
这个定义不容易理解,对初学者来说可能听起来很吓人。
本文旨在帮助您以一种简单的语言理解 ROC 曲线,以便您可以在 ROC 曲线背后建立一些基本思想。
在我们进入 ROC 曲线之前,我们需要记住混淆矩阵是什么。
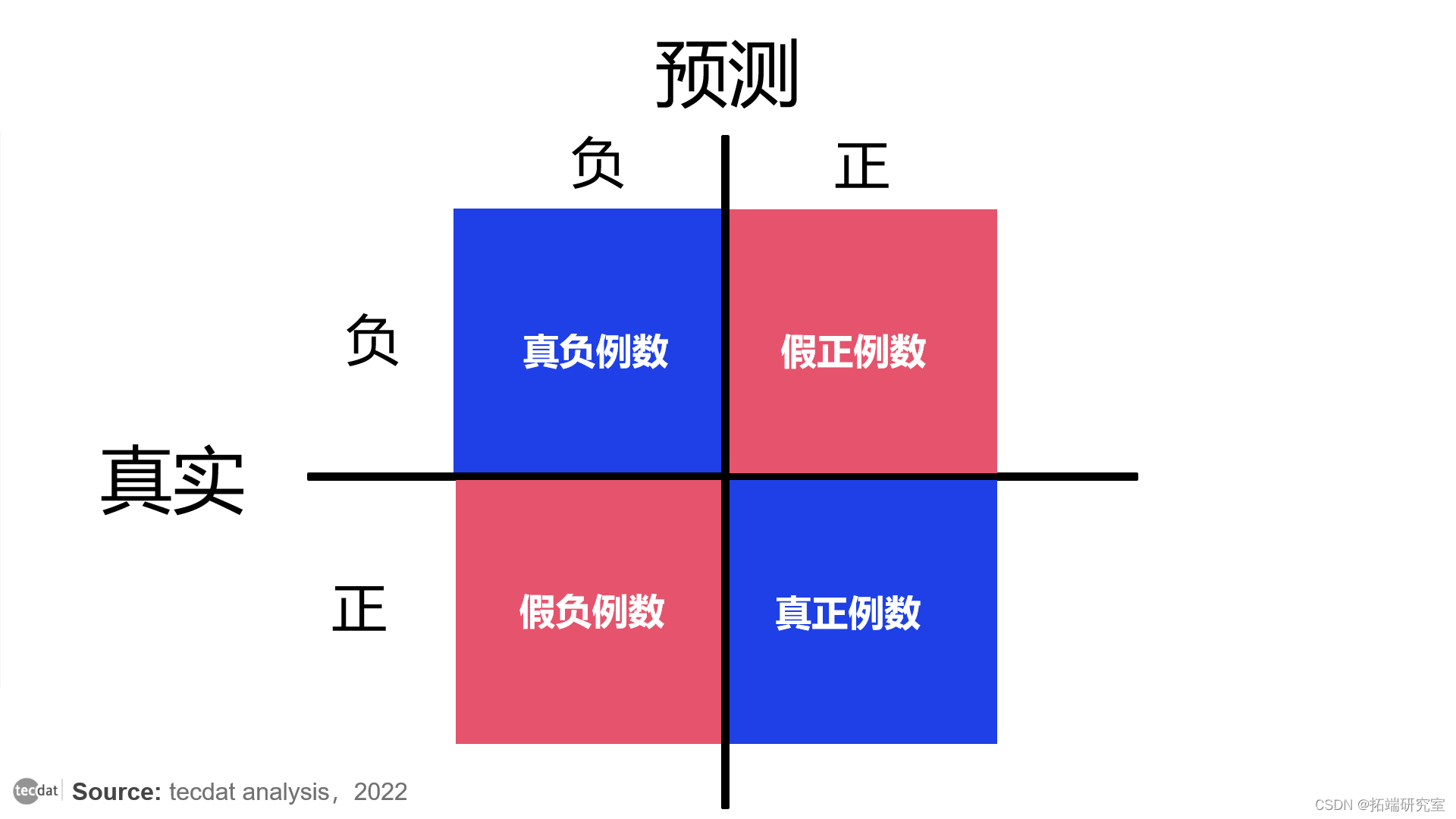
混淆矩阵
混淆矩阵帮助我们可视化模型在区分两个类别时是否“错误”。它是一个 2x2 矩阵。行名是测试集中的实际值,列名是模型预测的。
Positive或Negative是 ML 模型预测标签的名称。每当预测错误时,第一个词是False,当预测正确时,第一个词是True。
ROC曲线基于从混淆矩阵得出的两个指标:真正例率 ( TPR ) 和假正例率 ( FPR )。TPR与召回率相同。它是正确预测的正样本除以数据集中可用的所有实际正样本的比率。
TPR 侧重于实际的正类:
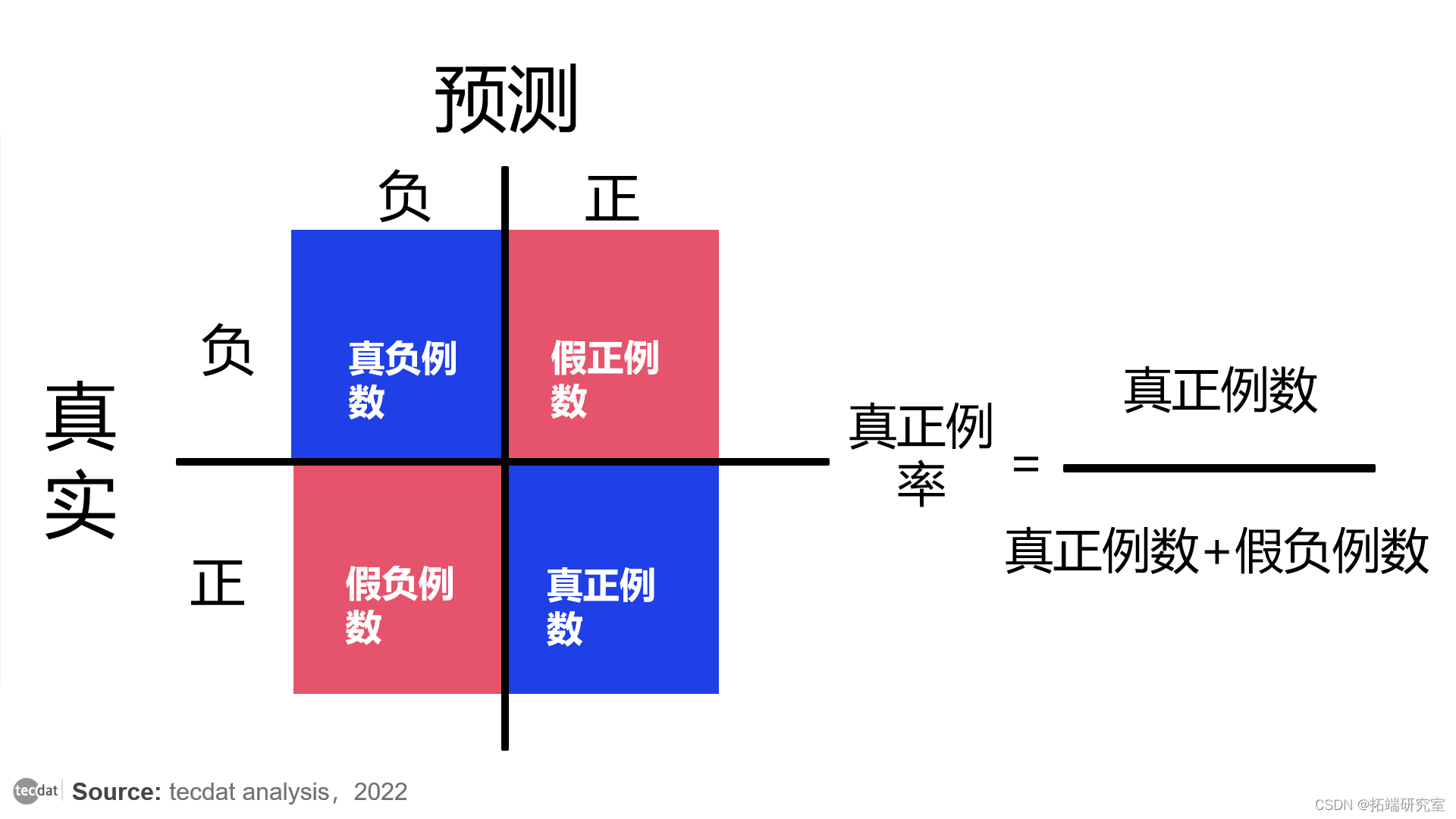
真正例率公式
反过来,FPR 是假正例预测与真负样本总数的比率。
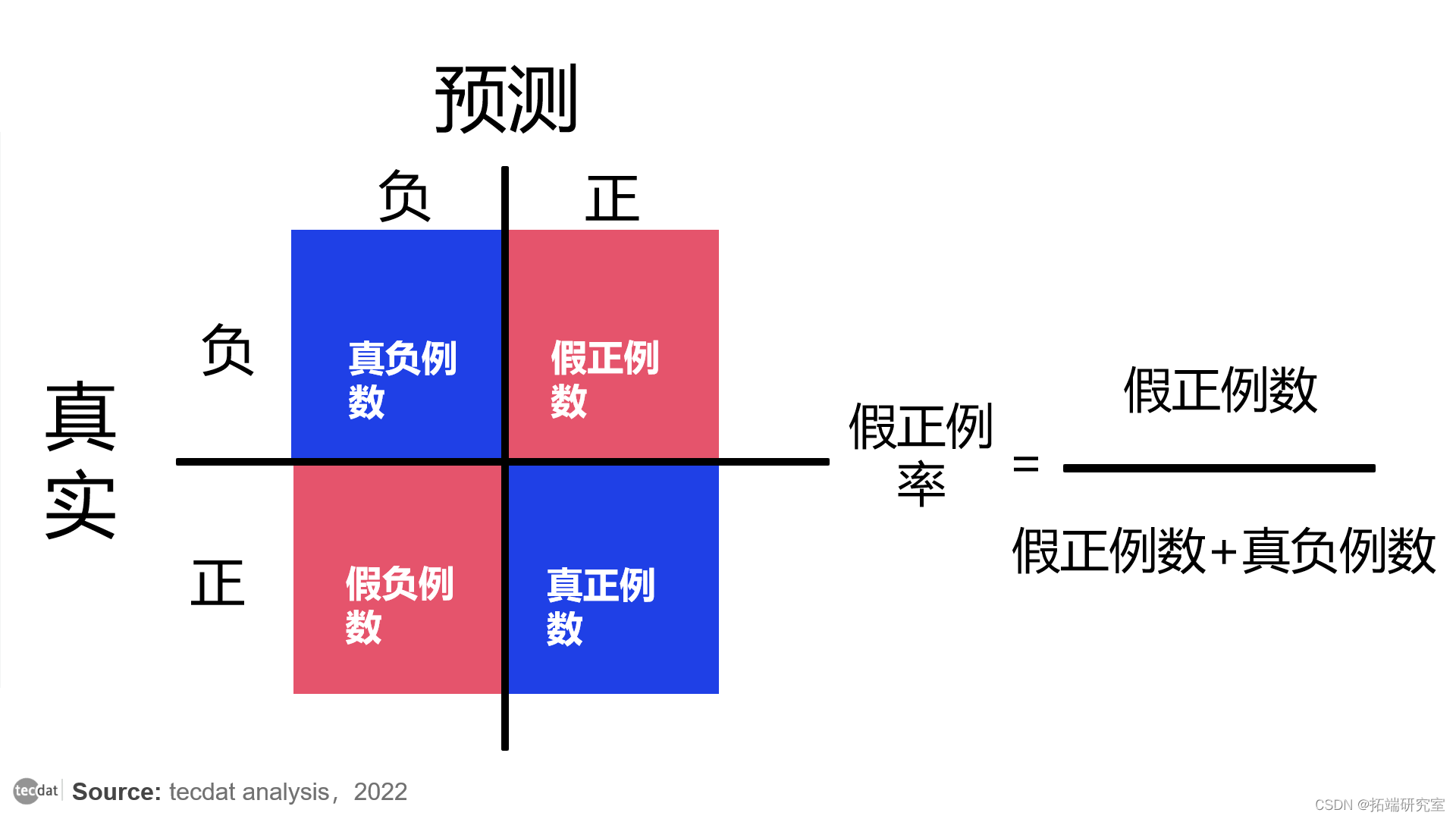
FPR公式
ROC 曲线是基于 TPR 和 FPR 绘制的。
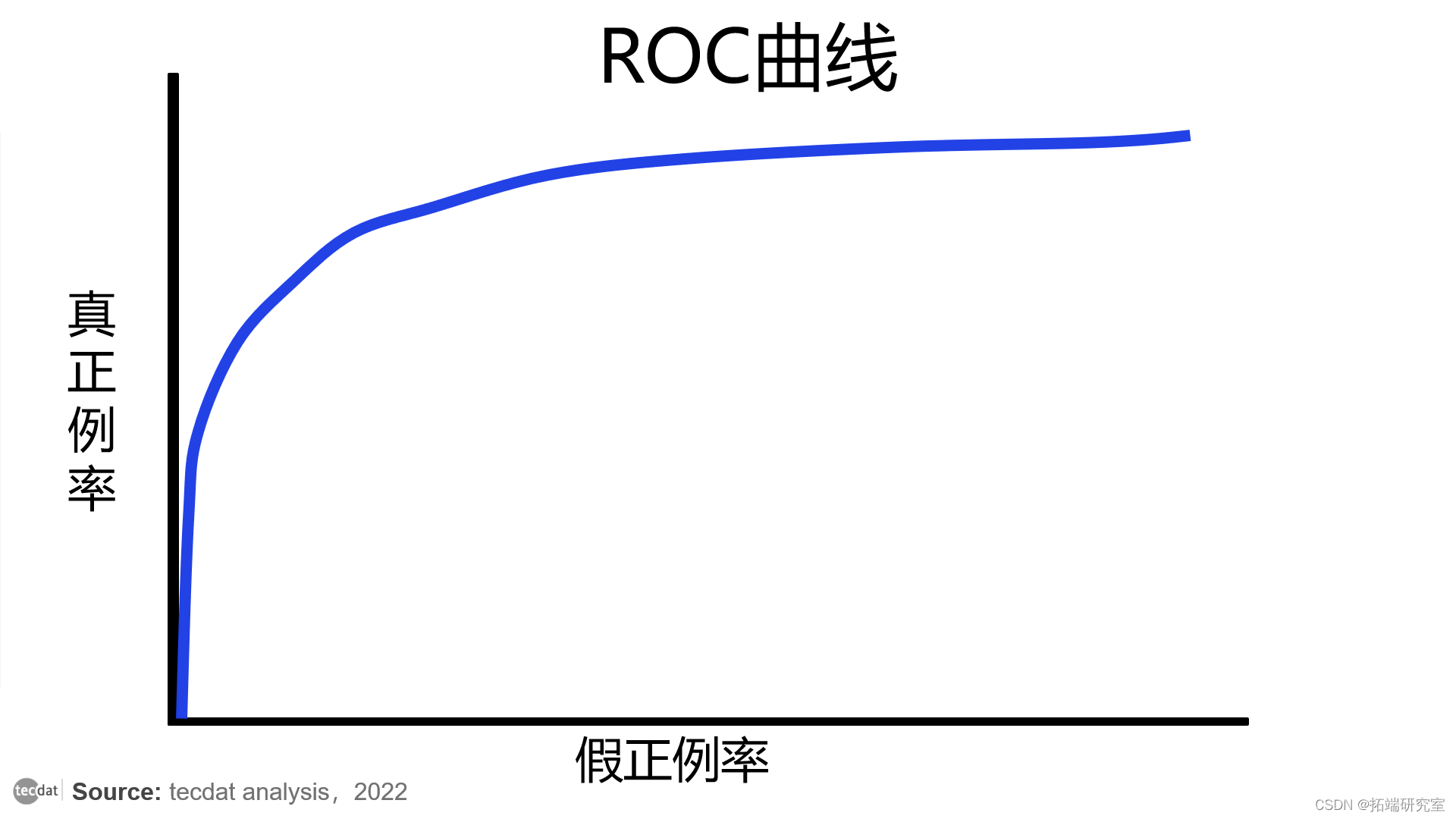
ROC曲线示例
通过使用 TPR 和 FPR,ROC 曲线显示了您的分类模型在所有分类阈值下的性能。
但是分类决策阈值是多少?
首先,你的分类 ML 模型输出是一个概率。例如,您构建一个分类器来根据给定人的体重预测性别(女性或男性)。假设正类是女性(1),负类是男性(0)。然后,您将 150 公斤的重量样本传递给您的 ML 模型,该模型预测的概率为 0.23。
默认情况下,您的分类阈值为 0.5。任何高于 0.5 的概率将被归类为 1 类(正),低于 0.5 的概率将被归为 0 类(负)。给定 0.23 的概率,体重 150 公斤的人将被归类为负类(男性)。
简而言之,您使用此阈值作为截止值,将预测结果分类为正类或负类。这是一个后处理步骤,将预测概率作为二进制类别返回。通过更改阈值,您的 TP、TN、FP 和 FN 将发生变化,因此您可以根据要改进的指标对其进行优化。
因此,ROC 反过来会告诉您您的 ML 模型能够在多大程度上区分不同阈值的两个类别。
您使用称为AUC曲线下面积来测量 ROC。您使用 AUC 来评估算法的质量,以便在两个类别之间进行检测。
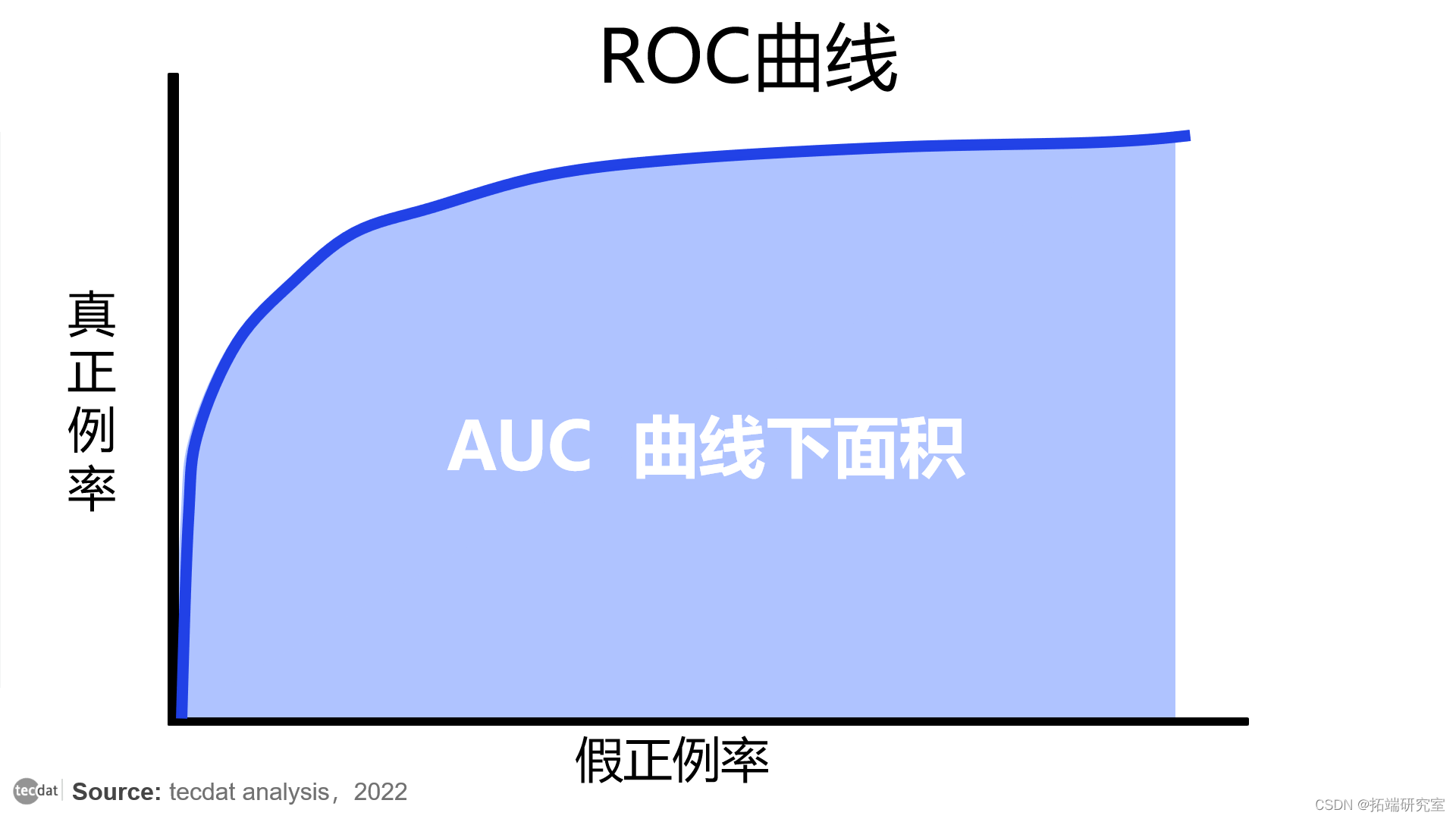
A rea U under the Curve: AUC
让我们通过图形示例来回顾 ROC。
假设我们正在建立一个模型来预测:申请人是偿还贷款还是坏帐。
在下图中,蓝线是正类预测概率的分布,表示申请者拒付(未能偿还),红线是负类预测概率分布,表示申请者将偿还。
在以下情况下,AUC 为 0.70。这意味着该模型能够正确区分正类和负类之间的 70%。
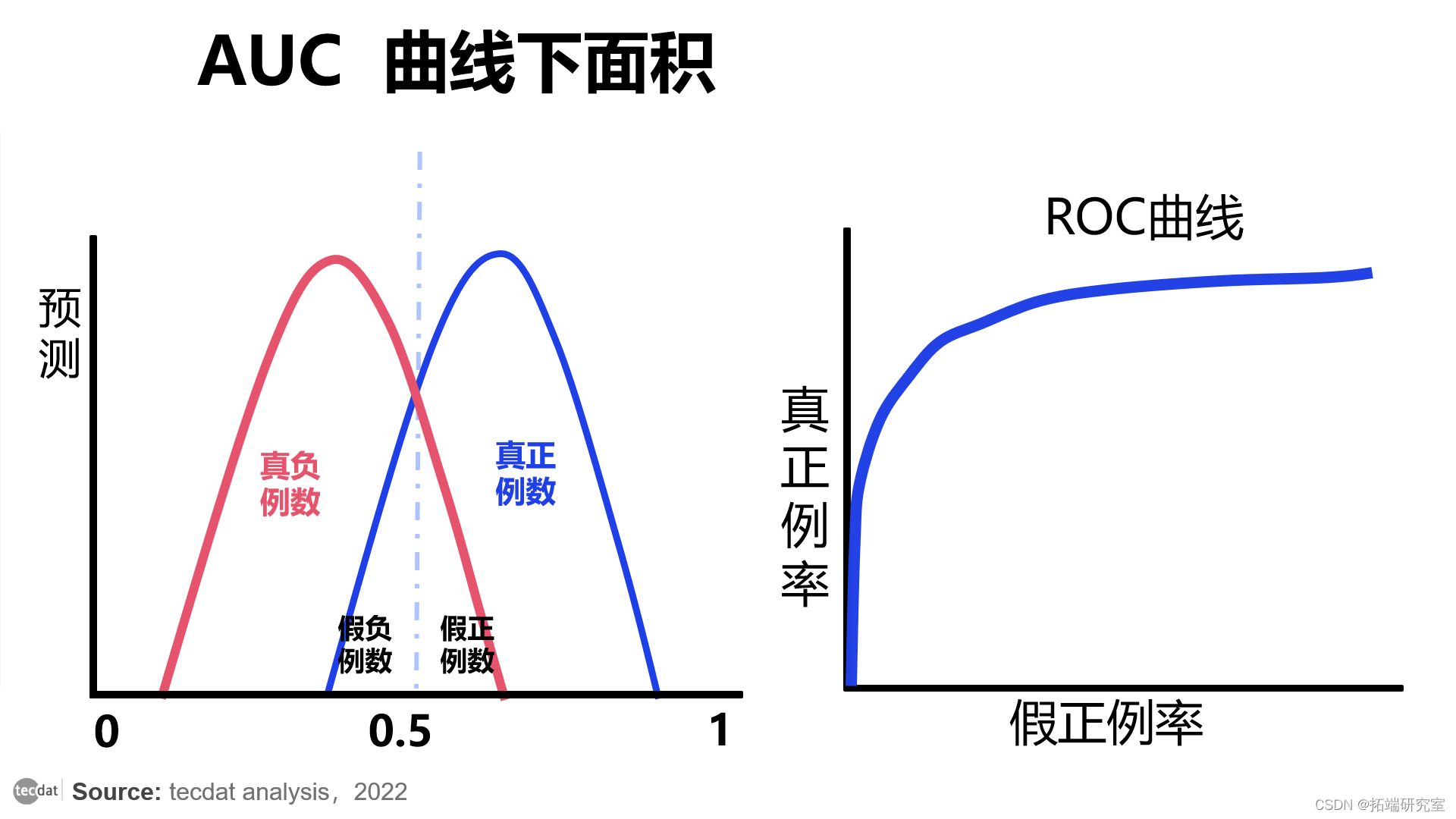
AUC=0.7
显然,我们离理想的情况还很远。曲线将重叠,这意味着我们的 ML 模型会犯错误,我们将其视为误报。

理想分类器示例
上述案例说明了当我们的 ML 模型正确预测两个类时的理想情况。分布之间没有重叠。该模型可以完美区分正类和负类,是一个理想的分类器。
可能存在 AUC 为 0.5 的情况。这意味着我们的 ML 模型无法区分正类和负类。它实际上是一个随机分类器。
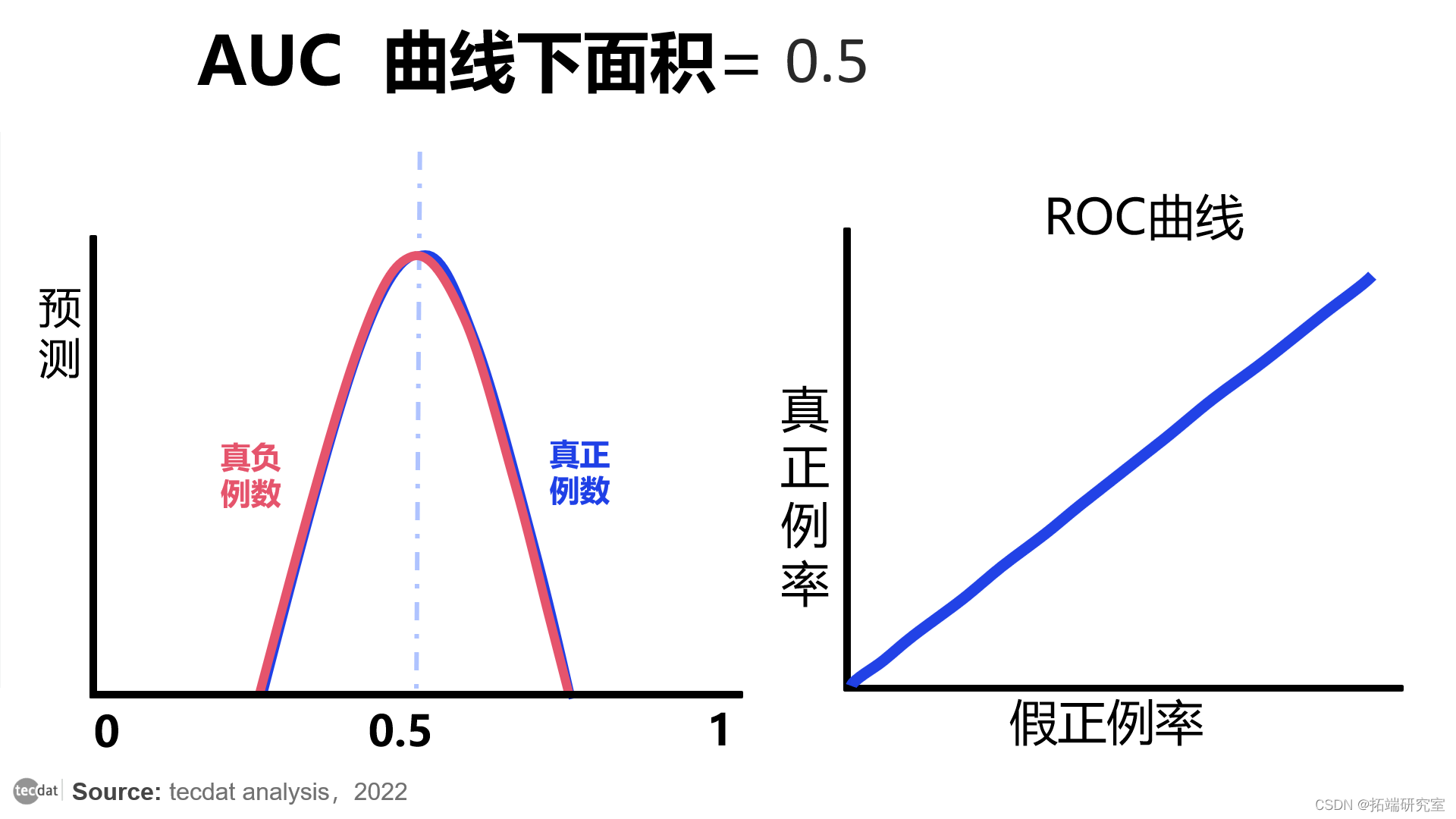
AUC = 0.5
有时 AUC 为 0。这意味着模型反向预测类别。该模型认为负类是正类,反之亦然。
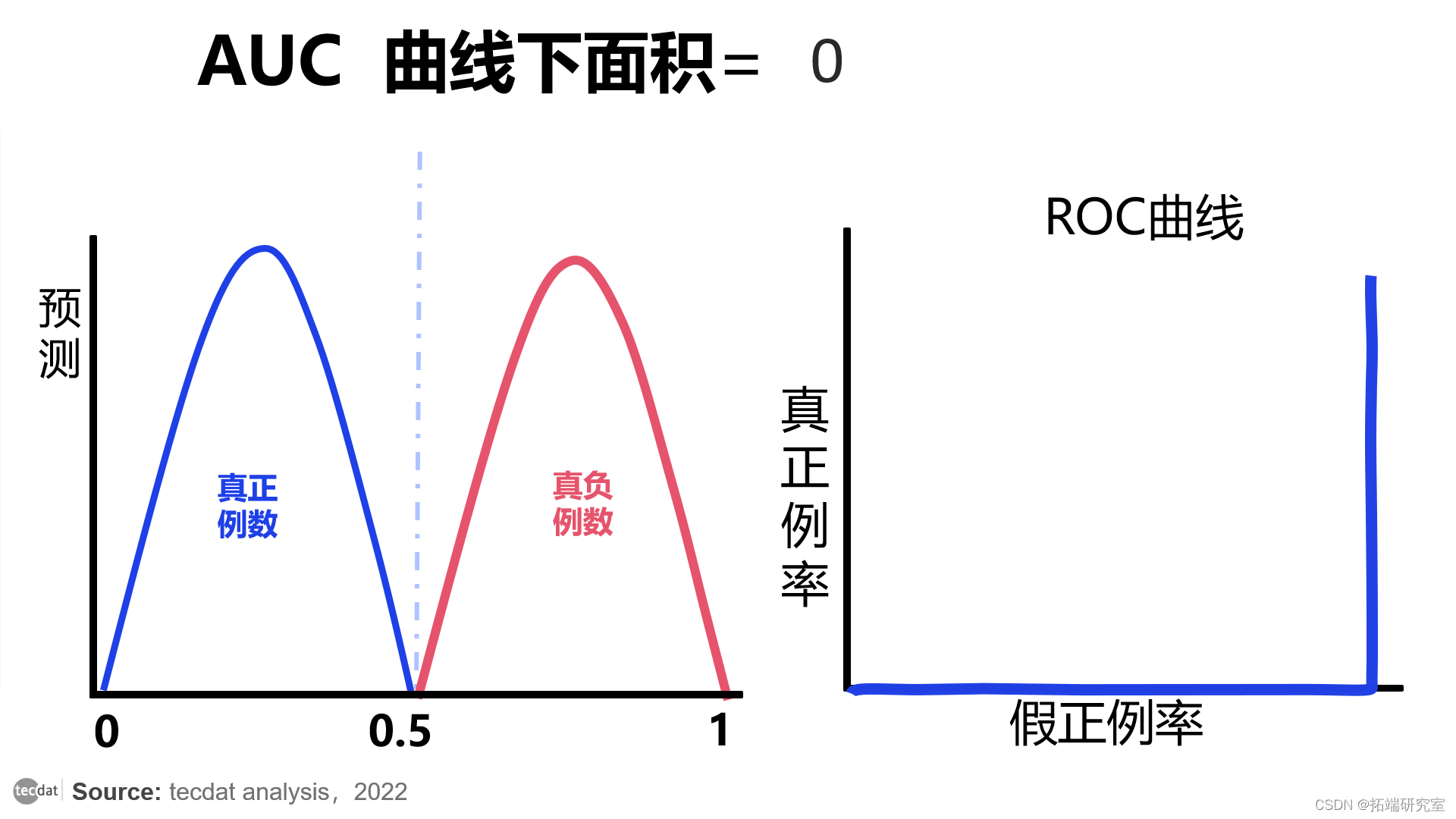
AUC = 0
总而言之,合理的 AUC 超过 0.5(随机分类器),而好的分类模型的 AUC > 0.9。然而,这个值高度依赖于它的应用。
R语言中生存分析模型与时间依赖性ROC曲线可视化
视频:R语言生存分析原理与晚期肺癌患者分析案例
R语言生存分析Survival analysis原理与晚期肺癌患者分析案例
人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归。但是,流行病学研究中感兴趣的结果通常是事件发生时间。使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型。
时间依赖性ROC定义
令 Mi为用于死亡率预测的基线(时间0)标量标记。 当随时间推移观察到结果时,其预测性能取决于评估时间 t。直观地说,在零时间测量的标记值应该变得不那么相关。因此,ROC测得的预测性能(区分)是时间t的函数 。
累积病例
累积病例/动态ROC定义了在时间t 处的阈值c处的 灵敏度和特异性, 如下所示。
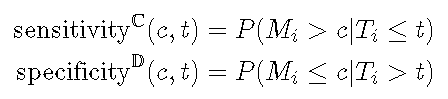
累积灵敏度将在时间t之前死亡的视为分母(疾病),而将标记值高于 c 的作为真实阳性(疾病阳性)。动态特异性将在时间t仍然活着作为分母(健康),并将标记值小于或等于 c 的那些作为真实阴性(健康中的阴性)。将阈值 c 从最小值更改为最大值会在时间t处显示整个ROC曲线 。
新发病例
新发病例ROC1在时间t 处以阈值 c定义灵敏度和特异性, 如下所示。
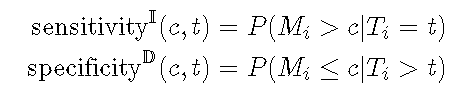
累积灵敏度将在时间t处死亡的人 视为分母(疾病),而将标记值高于 Ç 的人视为真实阳性(疾病阳性)。
数据准备
我们以数据 包中的dataset3survival为例。事件发生的时间就是死亡的时间。Kaplan-Meier图如下。
-
-
-
## 变成data_frame
-
data <- as_data_frame(data)
-
## 绘图
-
plot(survfit(Surv(futime, fustat) ~ 1,
-
data = data)
可视化结果:

在数据集中超过720天没有发生任何事件。
-
-
## 拟合cox模型
-
coxph(formula = Surv(futime, fustat) ~ pspline(age, df = 4) +
-
##获得线性预测值
-
predict(coxph1, type = "lp")
累积病例
实现了累积病例
-
-
## 定义一个辅助函数,以在不同的时间进行评估
-
ROC_hlp <- function(t) {
-
survivalROC(Stime
-
status
-
marker
-
predict.time = t,
-
method = "NNE",
-
span = 0.25 * nrow(ovarian)^(-0.20))
-
}
-
## 每180天评估一次
-
ROC_data <- data_frame(t = 180 * c(1,2,3,4,5,6)) %>%
-
mutate(survivalROC = map(t, survivalROC_helper),
-
## 提取AUC
-
auc = map_dbl(survivalROC, magrittr::extract2, "AUC"),
-
## 在data_frame中放相关的值
-
df_survivalROC = map(survivalROC, function(obj) {
-
-
## 绘图
-
ggplot(mapping = aes(x = FP, y = TP)) +
-
geom_point() +
-
geom_line() +
-
facet_wrap( ~ t) +

可视化结果:
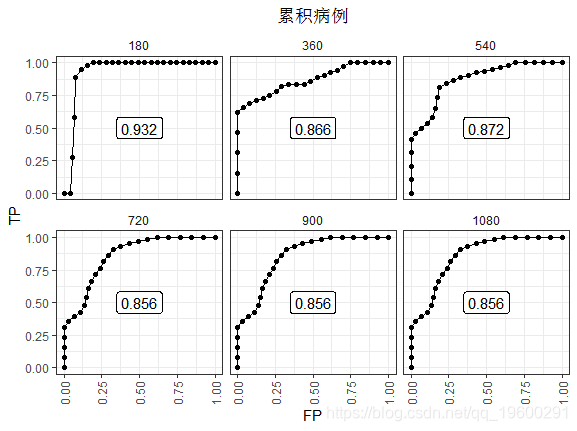
180天的ROC看起来是最好的。因为到此刻为止几乎没有事件。在最后观察到的事件(t≥720)之后,AUC稳定在0.856。这种表现并没有衰退,因为高风险分数的人死了。
新发病例
实现新发病例
-
-
## 定义一个辅助函数,以在不同的时间进行评估
-
-
## 每180天评估一次
-
-
## 提取AUC
-
auc = map_dbl(risksetROC, magrittr::extract2, "AUC"),
-
## 在data_frame中放相关的值
-
df_risksetROC = map(risksetROC, function(obj) {
-
## 标记栏
-
marker <- c(-Inf, obj[["marker"]], Inf)
-
-
## 绘图
-
-
ggplot(mapping = aes(x = FP, y = TP)) +
-
geom_point() +
-
geom_line() +
-
geom_label(data = risksetROC_data %>% dplyr::select(t,auc) %>% unique,
-
facet_wrap( ~ t) +
可视化结果:
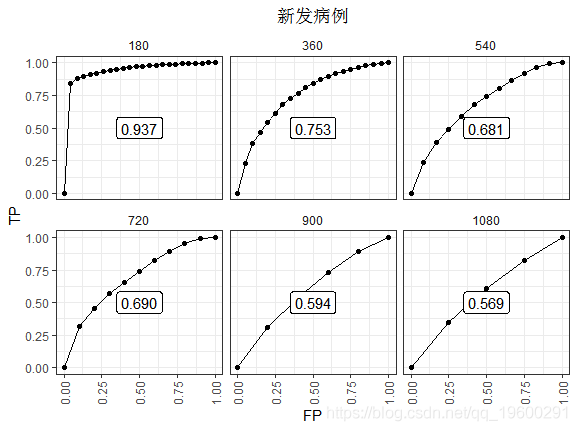
这种差异在后期更为明显。最值得注意的是,只有在每个时间点处于风险集中的个体才能提供数据。所以数据点少了。表现的衰退更为明显,也许是因为在那些存活时间足够长的人中,时间零点的风险分没有那么重要。一旦没有事件,ROC基本上就会趋于平缓。
结论
总之,我们研究了时间依赖的ROC及其R实现。累积病例ROC可能与风险 (累积发生率)预测模型的概念更兼容 。新发病例ROC可用于检查时间零标记在预测后续事件时的相关性。
参考
-
Heagerty,Patrick J. and Zheng,Yingye, Survival Model Predictive Accuracy and ROC Curves,Biometrics,61(1),92-105(2005). doi:10.1111 / j.0006-341X.2005.030814.x.