全文链接:http://tecdat.cn/?p=21425
原文出处:拓端数据部落公众号
R语言极值理论EVT:基于GPD模型的火灾损失分布分析
正态分布属于统计学里的知识,对于我们科研来说在数据处理时常常用到所以需要学习相关的知识。
正态分布在自然界中是一种最常见的分布。例如,测量的误差、射击的偏差、人体的身高、农作物的亩产量、学生考试成绩等都近似服从正态分布,因此,正态分布在科研理论研究中是非常重要的。

但对于您可能有兴趣研究大型事件的影响以进一步了解和未来预期的其他各种情况,正态分布将不起作用!很多数据都适合这种描述,例如需要研究大额财务损失的影响并获得其发生概率的财务数据。

由于此类事件很少见,正态分布会忽略它,因为它不会发生,而极值理论 (EVT)似乎通过突出数据的极值部分并对其进行单独建模以回答相关感兴趣问题。
由于统计中的任何表达式都有“理论”一词,因此给人的印象是黑匣子充满了复杂/未触及的内容,这与 EVT 相关的声誉相同。在本文中,我们将预览 EVT 的各种应用程序的简化介绍,最后您将大致了解 EVT,为什么以及何时需要使用它?!.
概述
这篇文章将如下
- 关于 EVT 的简单介绍。
- 列出实现 EVT 的不同应用程序。
顾名思义,极值理论提供了一类方法来预测极端事件的行为方式。它用于结构工程、地球科学和城市规划;随着新研究的不断涌现,它已被证明是极值分析中的重要资源。
简而言之,EVT 可以概括为对风险价值(也称为方差-协方差法)疏忽的解决方案。
介绍
“In cauda venenum”是您在极值理论一书中看到的第一句话: Laurens de Haan 和 Anna Ferreira 的介绍,这是关于您在应用 EVT 时将要处理的数据的性质的非常富有表现力的句子. 极端数据通常具有更重要的尾部信息,反映真实行为。
“重尾”和高斯分布模型有什么区别?
“重尾”分布是那些尾部不是指数边界的分布。与具有“正态分布”的钟形曲线不同,重尾分布以较慢的速度接近零,并且可能具有非常高的异常值。
就风险而言,重尾分布更有可能发生较大的、不可预见的事件。从图形上看,与经验数据相比,重尾模型(深蓝色)捕捉到了模型投资组合中描述的更多风险。高斯模型或钟形曲线,正态分布为浅蓝色。
峰度是从简单统计中检测极端数据最合适的度量,其中高峰度表示重尾分布,而低峰度表示相当轻的尾分布。仍然峰度不足以获得关于尾部重量、端点估计(如果可能的话)等的准确信息。
基于EVT,对于要作为极端数据考虑和分析的数据,数据必须具有其样本最大值的极限分布。从统计上讲

Fréchet、Ronald Fisher、Leonard Tippett、Richard von Mises 和 Boris Gnedenko 建立的 EVT 理论和基础。它们指定了样本最大值的一组非退化极限分布,称为“极值分布类别”,
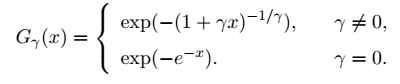
很明显,这类分布取决于一个称为极值指数 (EVI)的主要参数,这是了解极限分布性质的关键参数。EVI将极值分布的一般类分为三个子类:
- 正 EVI表示具有无限端点的分布,这意味着您正在处理重尾分布。
- 零 EVI表示分布端点等于无穷大,即Light Tailed Distribution。
- 负 EVI是指端点为负的 EVI 可逆分布,表示短尾分布。


极值理论
通常极端分析从相对较大的数据开始,然后缩小规模以仅分析极端观察。选择这些观测值的主要方法有两种,即:超阈值峰值方法 (POT) 和分块极大值方法。
请注意,它与极值定理不同,极值定理说对于连续闭合函数必须存在最小值和最大值。
基本上,极值理论中使用了两种方法:
- AMS(annual maxima series):也称为块最大值模型,在这种模型中,数据集被分成等长的集合,每个集合的最大值被认为来自一个分布。最大值的分布不同于基础分布。这些分布是广义极值分布的一部分。这些分布Gumbel 分布(指数尾)、Fréchet 分布(重尾)或Weibull 分布(轻尾)。
- POT(Peak Over Threshold):第二种方法依赖于从连续记录中提取值超过某个阈值(低于某个阈值)的任何时期达到的峰值。这种方法通常被称为“Peak Over Threshold”方法 (POT)。使用这种方法的分布拟合是帕累托,对随机变量进行适当的重整化后的泛化形式称为广义帕累托分布。
块最大值法 将数据分成若干块,得到每个块的最大值。它需要非常大的数据集才能具有足够数量的块。而POT 方法是更现代的极端事件建模方法,它通过指定某个高阈值并在分析中考虑高于该点的所有观察结果来工作. 在 POT 方法中,找到阈值总是至关重要的,并且有很多方法可以找到它,例如希尔图。
分块极大值方法
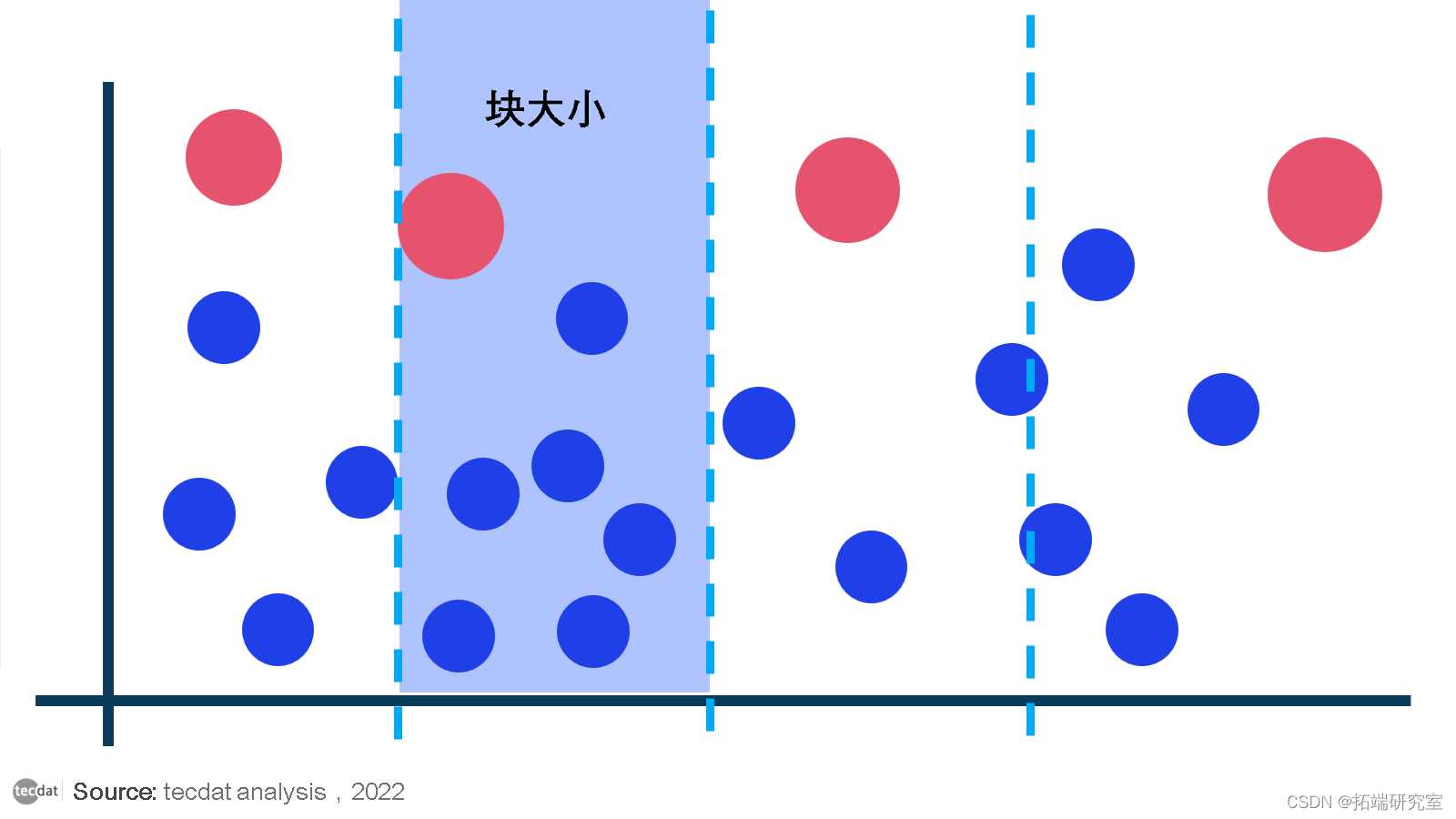
数据被分成区间,区间的大小由统计学家决定。取每个间隔(或“块”,因此得名)的最极端值。最极端的值将是块中的最小值或最大值,具体取决于统计学家的目标。使用 Block Maxima 方法时,没有确定块大小的标准化方法。
峰值超过阈值
阈值由统计学家决定,高于(或低于)该阈值的所有值都被视为极端值。这些是选择要建模的值。
这些方法在许多方面都被证明是有用的,尽管它们也有自己的挫折。使用 Block Maxima 方法时,没有确定块大小的标准化方法,类似于使用 POT 方法时没有标准阈值。这意味着统计学家将不得不用他们最好的判断来自己决定“正常”和“极端”之间的界限在哪里;值太低会导致较大的方差;过多的订单统计数据可能会导致较大的偏差。
极值分析面临的主要挑战之一是缺乏可用的数据。仅对一小部分数据进行建模可能会遇到挫折;它可能导致过度概括,或者模型是仅在特定情况下运行良好的模型。鉴于 EVT 只关注最极端的值,我们需要只适用于罕见和极端情况的模型。此外,鉴于我们正在尝试计算极端数据,我们在某种程度上试图尽可能地过度概括,同时仍然对数据提供准确的洞察力。
应用
从介绍中,您可能对使用极端分析的案例有所了解。简而言之,当您有兴趣查看数据中甚至可能从未发生过的极端/不规则事件时,简单的峰度工具可能会给出提示。在这里,我将为您提供几个实际应用及其结论以及如何将 EVT 纳入分析。
一、人类寿命的极限
该应用程序考虑了 1986 年至 2015 年间死亡的荷兰居民的死亡年龄数据。根据这些数据,他们想确定人类寿命的极限?!. 使用 POT 方法,通过最大似然估计量估计 EVI 对于女性和男性都是负数,这强烈表明存在年龄分布的有限端点。然后通过女性 124 岁和男性 125 岁来估计终点。有关分析和数据的详细信息,您可以查看通过极值理论限制人类寿命的论文。

二、终极运动记录
收集有关跑步、投掷和跳跃的运动记录的数据来回答这个问题,每项特定运动的最终记录是什么?!. 他们首先通过矩估计量来估计 EVI,该估计量对于大多数事件都变为负数,这表明端点有限。然后根据估计的 EVI 估计端点。更多细节可以在通过极值理论在田径运动中的记录中找到。

三、堤坝高度
这被认为是 EVT 最著名的应用之一。在荷兰,众所周知,该国近 40% 的地区都在海平面以下。确保该国免受 1953 年发生的任何可能的洪水的影响是非常重要的。然后需要 EVT 来回答一个重要的问题,即在一年内应该给予堤坝非常小的洪水概率?!通过收集 100 年的风暴数据,他们通过估计堤坝高度的极端分位数来回答这个问题,因为洪水的概率是 0.0001。

四、摩天大楼
另一个有趣的应用是对摩天大楼的数据建模并检查其高度和楼层数的限制。全球摩天大楼的数据来自高层建筑和城市人居委员会 (CTBUH)。对摩天大楼的数量分布拟合了对数线性模型。进行 EVT 分析以预测极端高度和楼层数。用极值理论预测城市天际线 论文 有详细的分析和结果。

五、风险管理
在这里我不会列举一个具体的应用程序,因为有几个与保险和银行领域的风险管理相关的应用程序使用 EVT。一个关键工具是风险价值 (VAR) 和期望损失,它们都用于根据极端情况评估偿付能力。这些领域还有更多其他的 EVT 工具和实现,您可以查看EXTREME VALUE THEORY AS A RISK MANAGEMENT TOOL 进一步讨论和应用。
R语言极值理论EVT:基于GPD模型的火灾损失分布分析
极值理论关注风险损失分布的尾部特征,通常用来分析概率罕见的事件,它可以依靠少量样本数据,在总体分布未知的情况下,得到总体分布中极值的变化情况,具有超越样本数据的估计能力。因此,基于GPD(generalized pareto distribution)分布的模型可更有效地利用有限的巨灾损失数据信息,从而成为极值理论当前的主流技术。
针对巨灾发生频率低、损失高、数据不足且具有厚尾性等特点,利用GPD模型对火灾经济损失数据进行了统计建模;并对形状参数及尺度参数进行了估计。模型检验表明,GPD模型对巨灾风险厚尾特点具有较好的拟合效果和拟合精度,为巨灾风险估计的建模及巨灾债券的定价提供了理论依据。
火灾损失数据
本文使用的数据是在再保险公司收集的,包括1980年至1990年期间的2167起火灾损失。已对通货膨胀进行了调整。总索赔额已分为建筑物损失、利润损失。
-
base1=read.table( "dataunivar.txt",
-
header=TRUE)
-
base2=read.table( "datamultiva.txt",
-
header=TRUE)
考虑第一个数据集(到目前为止,我们处理的是单变量极值),
-
-
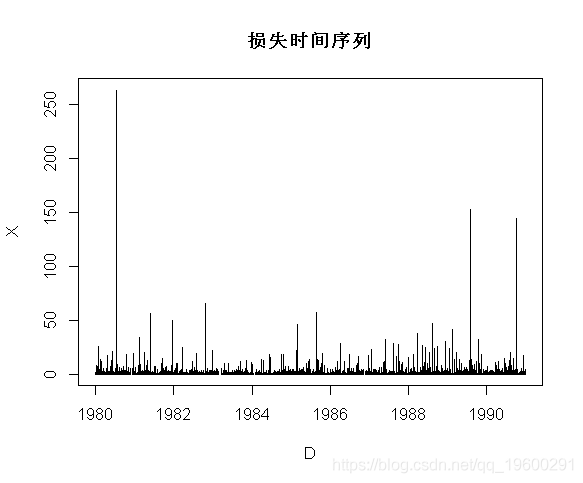
> D=as.Date(as.character(base1$Date),"%m/%d/%Y")
-
> plot(D,X,type="h")
图表如下:
然后一个自然的想法是可视化
例如
-
-
> plot(log(Xs),log((n:1)/(n+1)))
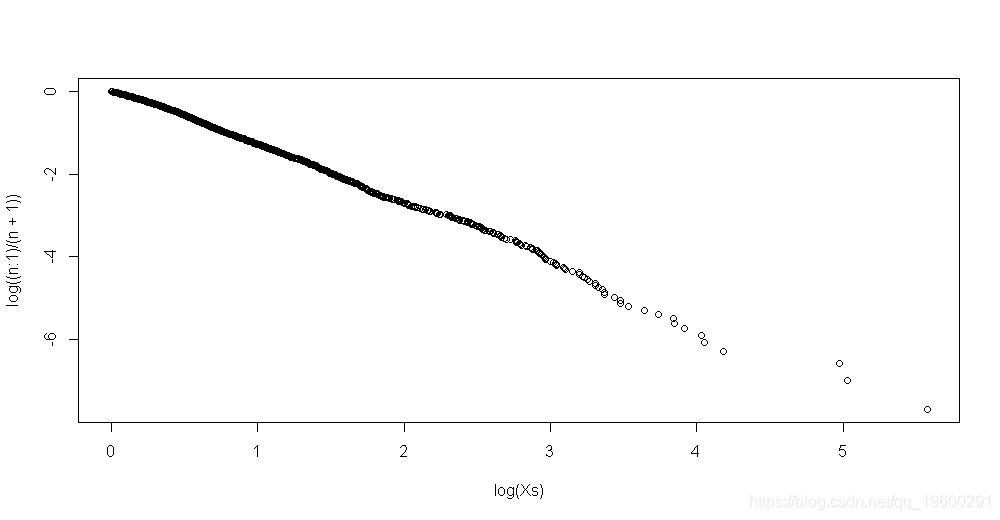
线性回归
这里的点在一条直线上。斜率可以通过线性回归得到,
-
-
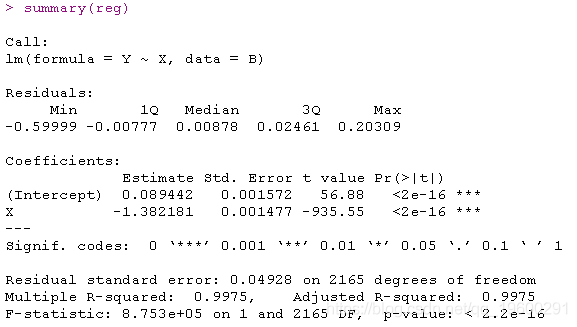
lm(formula = Y ~ X, data = B)
-
lm(Y~X,data=B[(n-500):n,])
-
lm(formula = Y ~ X, data = B[(n - 100):n, ])


重尾分布
这里的斜率与分布的尾部指数有关。考虑一些重尾分布
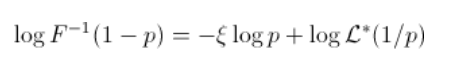
由于自然估计量是阶次统计量,因此直线的斜率与尾部指数相反 . 斜率的估计值为(仅考虑最大的观测值)
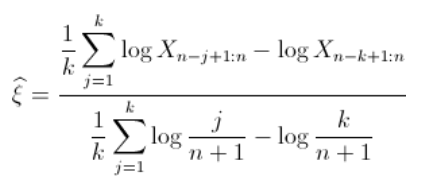
希尔估算量
那么可以得到收敛性假设。进一步
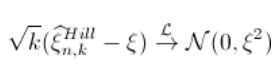
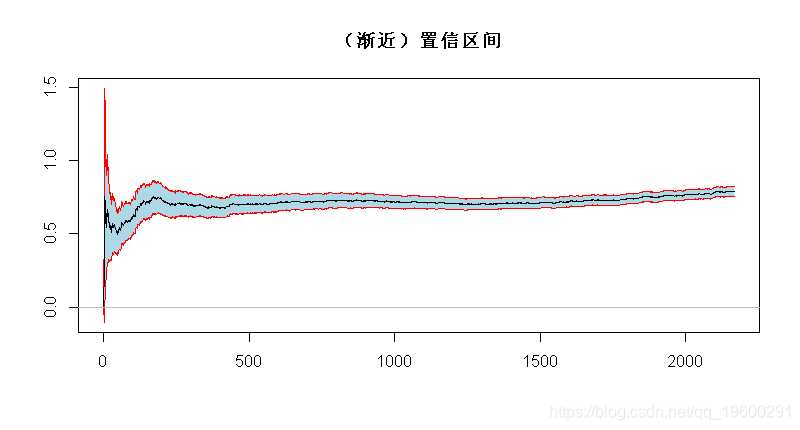
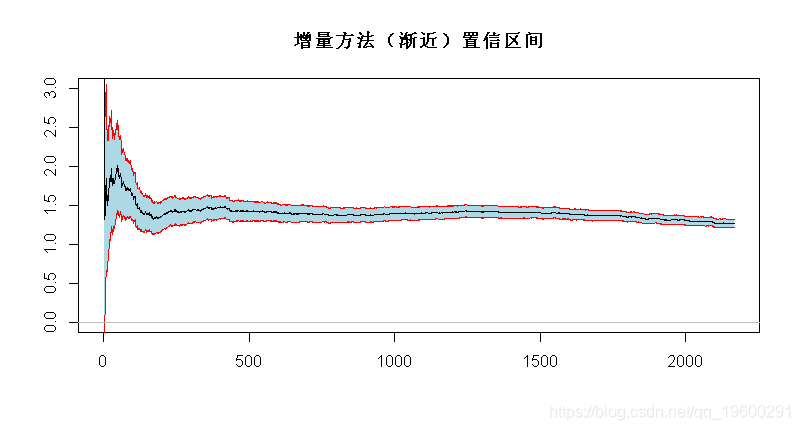
基于这个(渐近)分布,可以得到一个(渐近)置信区间
-
> xi=1/(1:n)*cumsum(logXs)-logXs
-
> xise=1.96/sqrt(1:n)*xi
-
-
> polygon(c(1:n,n:1),c(xi+xise,rev(xi-xise)),
增量方法
与之类似(同样还有关于收敛速度的附加假设)
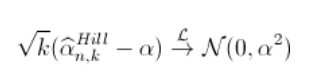
(使用增量方法获得)。同样,我们可以使用该结果得出(渐近)置信区间
-
-
> alphase=1.96/sqrt(1:n)/xi
-
> polygon(c(1:n,n:1),c(alpha+alphase,rev(alpha-alphase)),
Deckers-einmal-de-Haan估计量
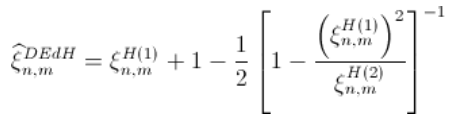
然后(再次考虑收敛速度的条件,即),
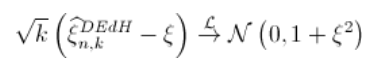
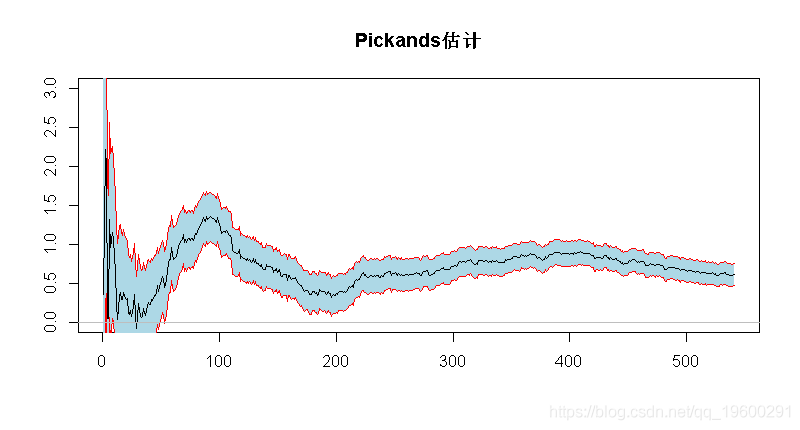
Pickands估计
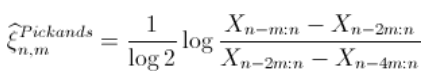
由于 ![]() ,
,
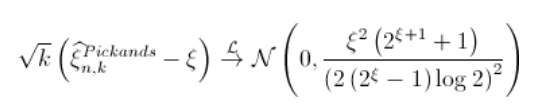
代码
-
> xi=1/log(2)*log( (Xs[seq(1,length=trunc(n/4),by=1)]-
-
+ Xs[seq(2,length=trunc(n/4),by=2)])/
-
-
> xise=1.96/sqrt(seq(1,length=trunc(n/4),by=1))*
-
+sqrt( xi^2*(2^(xi+1)+1)/((2*(2^xi-1)*log(2))^2))
-
-
> polygon(c(seq(1,length=trunc(n/4),by=1),rev(seq(1,
拟合GPD分布
也可以使用最大似然方法来拟合高阈值上的GPD分布。
-
-
> gpd
-
$n
-
[1] 2167
-
-
$threshold
-
[1] 5
-
-
$p.less.thresh
-
[1] 0.8827873
-
-
$n.exceed
-
[1] 254
-
-
$method
-
[1] "ml"
-
-
$par.ests
-
xi beta
-
0.6320499 3.8074817
-
-
$par.ses
-
xi beta
-
0.1117143 0.4637270
-
-
$varcov
-
[,1] [,2]
-
[1,] 0.01248007 -0.03203283
-
[2,] -0.03203283 0.21504269
-
-
$information
-
[1] "observed"
-
-
$converged
-
[1] 0
-
-
$nllh.final
-
[1] 754.1115
-
-
attr(,"class")
-
[1] "gpd"

或等效地
-
> gpd.fit
-
$threshold
-
[1] 5
-
-
$nexc
-
[1] 254
-
-
$conv
-
[1] 0
-
-
$nllh
-
[1] 754.1115
-
-
$mle
-
[1] 3.8078632 0.6315749
-
-
$rate
-
[1] 0.1172127
-
-
$se
-
[1] 0.4636270 0.1116136
它可以可视化尾部指数的轮廓似然性,
> gpd.prof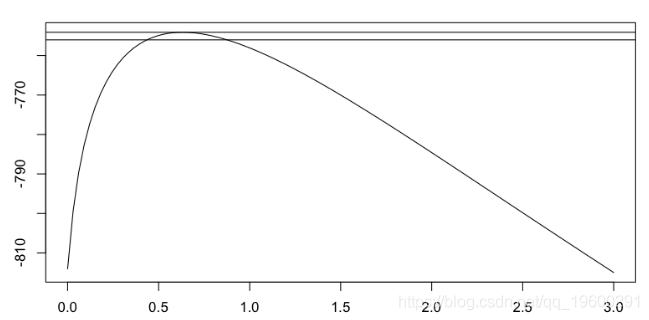
或者
> gpd.prof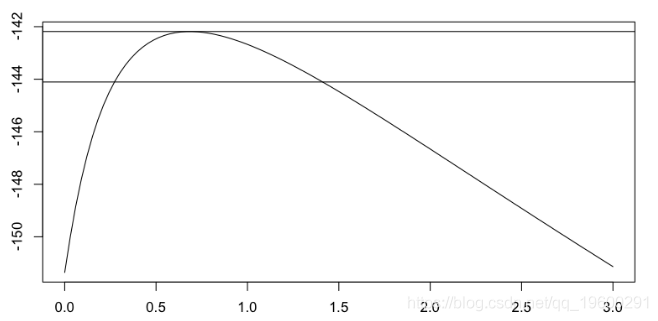
因此,可以绘制尾指数的最大似然估计量,作为阈值的函数(包括置信区间),
-
Vectorize(function(u){gpd(X,u)$par.ests[1]})
-
-
plot(u,XI,ylim=c(0,2))
-
segments(u,XI-1.96*XIS,u,XI+
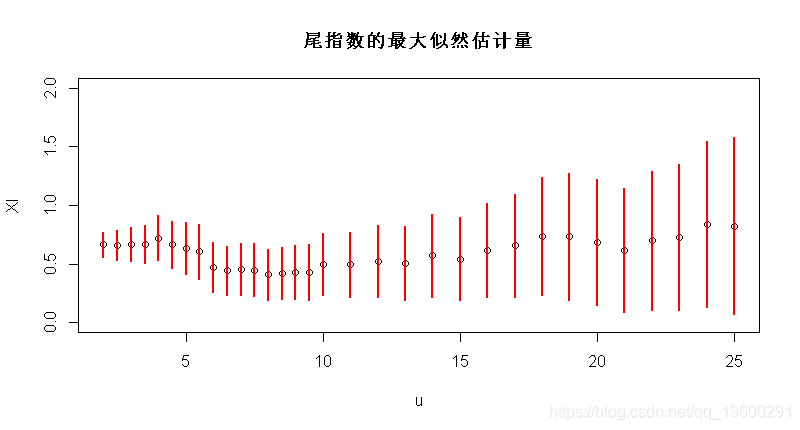
最后,可以使用块极大值技术。
-
gev.fit
-
$conv
-
[1] 0
-
-
$nllh
-
[1] 3392.418
-
-
$mle
-
[1] 1.4833484 0.5930190 0.9168128
-
-
$se
-
[1] 0.01507776 0.01866719 0.03035380
尾部指数的估计值是在这里最后一个系数。

最受欢迎的见解
1.R语言基于ARMA-GARCH-VaR模型拟合和预测实证研究