全文链接:http://tecdat.cn/?p=27606
原文出处:拓端数据部落公众号
作为数据挖掘的一个重要研究方向—关联规则用于发现数据项之间隐含的深层次的关联,如Apriori模型可以通过对客户需求进行深入的分析来发现数据之间的潜在联系,为我们提供自动决策支持。
Apriori模型
关联规则是数据挖掘算法中主要技术之一,是在无指导学习系统中挖掘本地模式的最普便形式。在数据挖掘中,常见的关联规则挖掘模型有AIS、SETM、Apriori、DHP、MLT2L1、ML-TML1等。其中,Apriori算法是一种最有影响的挖掘关联规则频繁项集的模型。
Apriori模型原理
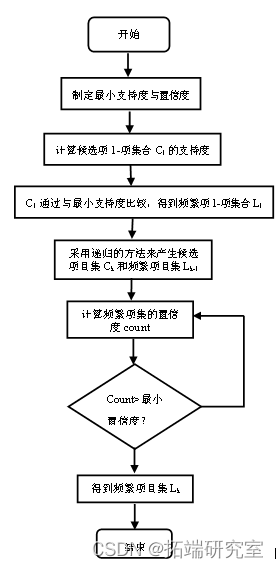
Apriori算法通过多次扫描事务数据库来产生频繁项目集,我们称这种方法为逐层搜索迭代法。具体地说,该算法的基本思想是通过对数据库的多次扫描来发现所有的频繁项集。首先第1遍扫描事务数据库生成频繁1项集,记为L1;然后基于L1第2遍扫描事务数据库生成频繁2项集,记为L2;依此迭代,基于L(k-1)第k遍扫描事务数据库生成频繁k项集,记为Lk。在后续的扫描中,首先以前一次所发现的所有频繁项集为基础,生成所有新的候选项集(Candidate Item sets),然后扫描数据库,计算这些候选项集的支持度,最后确定候选项集中哪些可成为频繁项集。重复上述过程直到再也产生不出新的频繁项集。
由此可见,Apriori算法是一种通过多次扫描事务数据库统计不同项的发生次数,以此来抽取频繁模式的过程。由于Apriori算法需要大量扫描事务数据库,因此利用Apriori算法的相关性质对其进行搜索空间压缩。
Apriori算法的性质如下:频繁项集中的所有非空子集也是频繁的。该属性可以通过如下方式证明:若A是非频繁的,那么集合A∪B也是非频繁的,即构成集合的子集是非频繁的,则该集合也是非频繁项集。Apriori算法的这一属性为反单调性,在实际挖掘过程中,如果一个集合不能通过测试,那么它的所有超集也都不能通过相同的测试。基于此,我们通过“连接”操作由现有频繁项集构造超集,通过“剪枝”操作过滤掉不能通过测试的超集,从而压缩下一次迭代的系统开销。
仿真
实验平台及数据
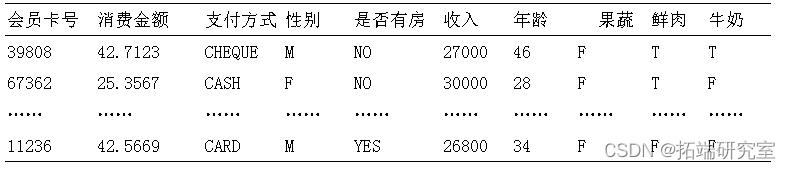
为了验证Apriori模型在DSS数据挖掘中应用的可行性,本文在Spss Modeler软件平台上对Apriori模型进行仿真。实验数据为某超市的DSS系统中的顾客及购买商品数据。数据包括1000条购买事务记录,每条购买事务记录中包含两大部分内容:第一部分是顾客的个人信息,主要变量有会员卡号、消费金额、支付方式、性别、年龄、收入等;第二部分是顾客一次购买商品的信息,主要变量有果蔬、鲜肉、奶制品等,均为二分类型变量,取值T表示购买,F表示未购买,下表为部分顾客购买数据。本文结合Apriori模型分析DSS中的顾客信息及购买数据分析哪些商品最有可能同时购买。
实验结果及分析
本文分别用Apriori算法和Carma算法对数据进行处理挖掘,具体结果如下所示。
(1)Apriori算法
采用了46243条顾客在超市购买的数据进行分析,涉及意大利面、牛奶、水、面包饼干、咖啡、奶油蛋糕、酸奶、冷藏蔬菜、金枪鱼、啤酒、番茄酱、可乐、大米、果汁、咸饼干、油、冰冻鱼、冰淇淋、奶酪、罐装肉多种商品,如果顾客购买了该商品,则记为1,如果没有购买该商品,则记为0。
虽然 Apriori 算法可以直接挖掘生成表中的交易数据集,但是为了关联挖掘其他算法的需要先把交易数据集转换成分析数据集。
通过格式转换,发现数据源中共有二十种商品,设最低条件支持度为15%,最小规则置信度为30%,最大前项数为5,选择专家模式,挖掘出大类商品的15条关联规则,如图所示。生成的15条规则如下所示:
Rule1: milk→yoghurt,supprot =15.235%,confidence =52.165%;
Rule2: milk→biscuits,supprot =20.474%,confidence =51.531%;
Rule3: milk→coffee,supprot =15.027%,confidence =49.878%;
Rule4: milk→brioches,supprot =15.319%,confidence =49.675%;
Rule5: milk→water,supprot =27.851%,confidence =46.704%;
Rule6: milk→pasta,supprot =35.034%,confidence =45.855%;
Rule7: pasta→coffee,supprot =15.027%,confidence =39.891%;
Rule8: pasta→brioches,supprot =15.319%,confidence =38.834%;
Rule9: pasta→biscuits,supprot =20.474%,confidence =37.917%;
Rule10: pasta→milk,supprot =46.132%,confidence =34.824%;
Rule11: pasta→yoghurt,supprot =15.235%,confidence =34.649%;
Rule12: pasta→water,supprot =27.851%,confidence =34.296%;
Rule13: water→pasta, milk,supprot =16.065%,confidence =33.288%;
Rule14: biscuits→brioches,supprot =15.319%,confidence =30.795%;
Rule15: water→coffee,supprot =15.027%,confidence =30.047%;
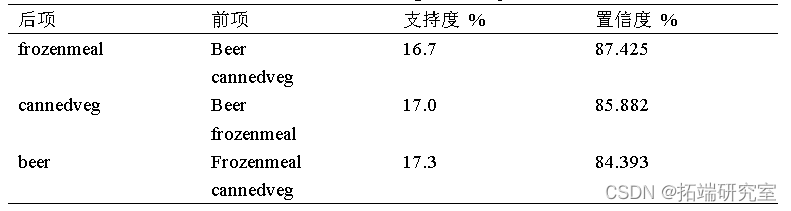
通过Spss Modeler使用Apriori模型对某超市DSS数据的分析,实验结果如表所示,实验产生了三条置信度和支持度最高的关联规则:分别为啤酒和罐头蔬菜→冷冻食品(S=14.6%,C=87.4%);啤酒和冷冻食品→罐头蔬菜(S=14.6%,C=85.9%);冷冻食品和罐头蔬菜→啤酒(S=14.6%,C=84.4%)。同时,三条关联规则的提升值都可以接受。因此,啤酒、罐头蔬菜、冷冻食品是最可能连带销售的商品。因此,在实际销售或者在商品的摆放过程中,可以将这些商品进行捆绑销售。
同时,本实验结果的商品销售关系网状图如图所示,表明了顾客可能同时购买的所有商品之间的联系,其中网状图中的不同点分别代表着不同的商品,点与点之间的连线代表着同时被顾客购买的联系。通过设定商品同时出售的频数的阈值,可以得到一些顾客同时购买机率较大的商品。可以看到,网状图的结论与Apriori模型挖掘的关联规则结论是一致的。
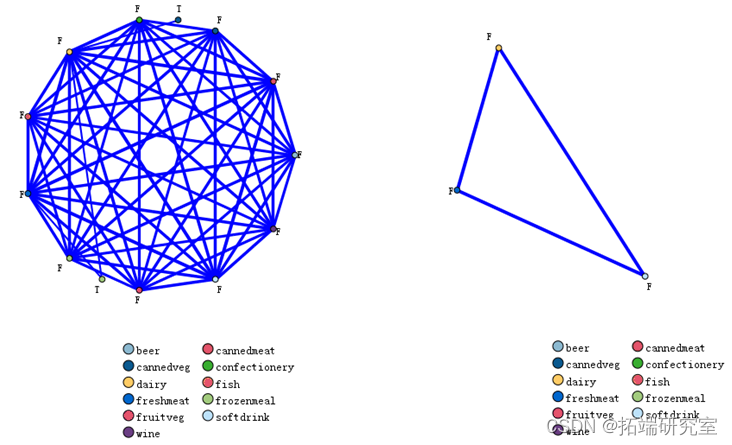
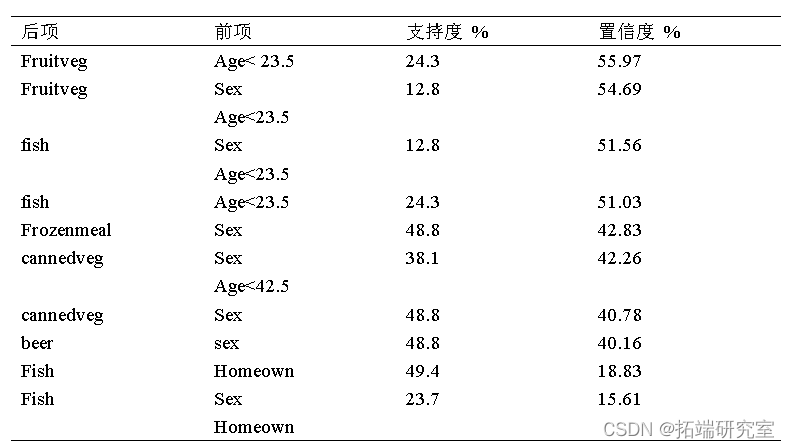
然后,本文对不同性别、年龄的顾客购买的商品之间的销售关系进行了Apriori模型的关联规则挖掘。实验结果如表所示,其中性别与购买商品的联系如图所示,(a)为不同性别顾客可能同时购买的所有商品之间的联系,其中网状图上方的两个点F、M分别代表着男性顾客与女性顾客,网状图下方的点分别代表不同的商品,点与点之间的连线代表着购买关系。通过设定商品同时出售的频数的阈值,可以得到不同性别的顾客同时购买的概率比较大的商品(b)。由图可知,男性最有可能同时购买饮料、牛奶、罐头蔬菜、甜食、冷冻熟食、果熟等商品,而女性则最有可能同时购买饮料、甜食、牛奶、罐头蔬菜等,因此,商家在推销其商品时可以针对不同性别的顾客制定不同的营销策略。
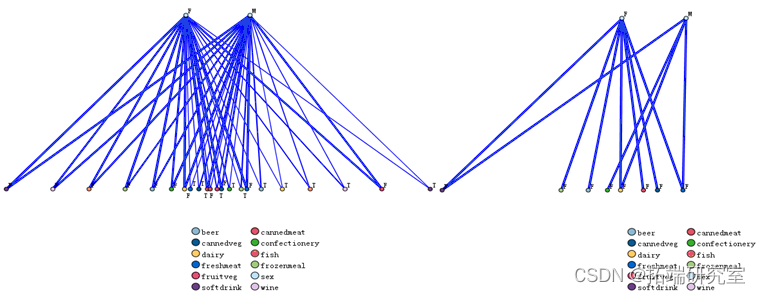
分析及建议: 通过图可以清晰的看到购买牛奶、意大利面、水、咖啡的顾客比较多,建议超市可以加大对这些商品的采购,由上述结果可知,同时购买牛奶、意大利面的情况占总订单数的46.132%,水和牛奶或意大利面和水分别占总订单数的27.851%,购买牛奶的人有45.855%会购买意大利面,46.704%的人会购买水,购买意大利面的人有34.824%会购买牛奶,有34.296%的人会购买水,由此可见,意大利面、水、牛奶这三种商品关联度较高,可以将意大利面、水、牛奶摆放在一块,从而增加销量。此外,在符合支持度和置信度的条件下没有顾客购买冷冻食、果汁等,建议有关人员减少这几种商品的进货量,但为了保持商品的多样性,还是要适当地进货。
Carma算法
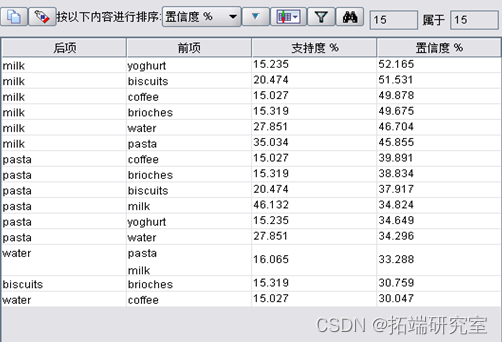
该实验数据仍采用上述数据,商品种类涵盖意大利面、牛奶、水、面包饼干、咖啡、奶油蛋糕、酸奶、冷藏蔬菜、金枪鱼、啤酒、番茄酱、可乐、大米、果汁、咸饼干、油、冰冻鱼、冰淇淋、奶酪、罐装肉,如果顾客购买了该商品,则记为T,如果没有购买该商品,则记为F。将Carma节点最小支持度设为7.0%,最小置信度设为15.0%,大小规则为5,Carma算法数据流如图3所示,由其生成的商品关联规则所示。生成16条规则如下所示:
Rule1: milk→yoghurt,supprot =15.235%,confidence =52.165%;
Rule2: milk→biscuits,supprot =20.475%,confidence =51.531%;
Rule3: milk→coffee,supprot =15.027%,confidence =49.878%;
Rule4: milk→brioches,supprot =15.319%,confidence =49.675%;
Rule5: milk→water,supprot =27.851%,confidence =46.704%;
Rule6: milk→pasta,supprot =35.035%,confidence =45.855%;
Rule7: pasta→biscuits,supprot =20.475%,confidence =37.917%;
Rule8: pasta→milk,supprot =46.133%,confidence =34.824%;
Rule9: pasta→water,supprot =27.851%,confidence =34.296%;
Rule10: water→milk,supprot =46.133%,confidence =28.196%;
Rule11: water→pasta,supprot =35.035%,confidence =27.264%;
Rule12: biscuits→milk,supprot =46.133%,confidence =22.871%;
Rule13: biscuits→pasta,supprot =35.035%,confidence =22.159%;
Rule14: yoghurt→milk,supprot =46.133%,confidence =17.277%;
Rule15: brioches→milk,supprot =46.133%,confidence =16.496%;
Rule16: coffee→milk,supprot =46.133%,confidence =16.247%;
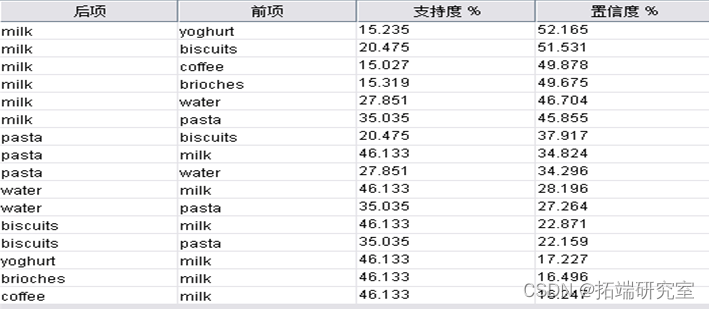
分析及建议: 通过上述规则可以清晰的看到顾客同时购买牛奶、意大利面、水、饼干的比较多,建议超市可以将这些商品放在同一货架上进行销售。Carma算法所得结果相比Apriori算法略有不同,它比Apriori算法更加精准。商家可以多进牛奶、意大利面、水、酸奶、奶油蛋糕、饼干等商品,而对于冰冻食品,则可以减少进货量。
结束语
数据挖掘所得到的信息资源无论是对于企业的管理人员还是员工来说都是十分有价值的,它使企业能够充分利用现有的信息资源,在激烈的社会竞争中取得区别于其他企业的独特优势。本文使用关联规则算法中的Apriori模型对企业DSS数据进行关联规则挖掘,首先详细说明了Apriori模型的具体原理和实施步骤,然后,通过实例研究和对实验结果的分析,进一步明确了数据挖掘技术在以客户为中心的电子商务时代扮演着越来越重要的角色,随着数据挖掘理论的进一步发展和深化,必然会带给DSS更为广泛的应用前景和市场价值,同时提高企业的竞争力。
参考文献
- Gorry G A, Scott Morton M S. A Framework for Management Information Systems[J]. Sloan Management Review, 1971, 13(1): 50-70.
- Agrawal.R, T.Imieliński, A Swami. Mining association rules between sets ofitems in large databases[C]. ACM SIGMOD Record,1993,22(2):207-216.
- V.P.Singh. Consumer Behavior and Firm Strategies in a Changing Retail Environment[D]. Northwestern University, 2003:63-100.
- J.Jim. Consumer Heterogeneity in the Long-term Effects of Price Promotions[D]. University of California Irvine, 2004:5-21.
- Lee jin A, Han Jonggyu, Chi Kwang Hoon. Mining quantitative association rule of earthquake data[C]. ACM International Conference Proceeding Series.2009:349-352.
- 李虹, 蔡之华. 关联规则在医疗数据分析中的应用[J]. 微机发展,2003,13(6):94-97.
- 杨引霞, 谢康林, 朱扬勇, 等. 电子商务网站推荐系统中关联规则推荐模型的实现[J]. 计算机工程,2004,30(19):57-59.
- 胡晓青, 王波. 基于数据挖掘的金融时序频繁模式的快速发现[J]. 上海理工大学学报,2006,28(4):381-385.
- 宋钰, 何小利, 张刚园. 关联规则在医药云数据定向中的应用与仿真[J]. 计算机仿真,2013,30(2),239-242.
- 王和勇, 蓝金炯. 微群核心用户挖掘的关联规则方法的应用[J].图书情报工作,2014,58(2):115-120.
- R N Anthony. Planning and Control Systems: A Framework for Analysis [D]. MA, USA: Graduate School of Business Administration, Harvard University Cambridge, 1965.
- H A Simon. The New Science of Management Decision [M]. New York, USA: Harper Brothers, 1960.
- Spague R H. A Framework for the Development of Decision Support Systems [J]. MIS Quarterly (S0276-7783), 1980, 12: 1-26.
- Bonczek R H,C W Holsapple, A B Whinston. Foundations of Decision Support Systems [M]. New York, USA: Academic Press, 1981.
- 吉根林, 帅克, 孙志挥. 数据挖掘技术及其应用[J]. 南京师大学报(自然科学版), 2000, 23(2): 25-27.
- 杨炳儒. 知识工程与知识发现[M]. 北京:冶金工业出版社, 2000.
- 王安麟. 复杂系统的分析与建模[M]. 上海:上海交通大学出版社,2004.
- 李小兵, 吴锦林, 薛永生等. 关联规则挖掘算法的改进与优化研究[J]. 现代电子技术,2005,(4).
- Jiawei Han, Micheline Kamber. 数据挖掘概念与技术[M]. 北京:机械工业出版社,2001,152~161.
- Savasere A, Ong B, Mitbander B. An efficient algorithm for mining association rules in large databa ses[A]. Proc 1995,Int Conf Very Large Databases(VLDB’95)[C].1995.
- 陈江平, 傅仲良, 徐志红. 一种Apriori的改进算法[J]. 武汉大学学报(信息科学版),2003,28(1),94-99.

最受欢迎的见解
6.采用SPSS Modeler的Web复杂网络对所有腧穴进行分析
7.R语言如何在生存分析与COX回归中计算IDI,NRI指标