全文链接:http://tecdat.cn/?p=27530
原文出处:拓端数据部落公众号
市场风险指的是由金融市场中资产的价格下跌或价格波动增加所导致的可能损失。
市场风险包含两种类型:相对风险和绝对风险。绝对风险关注的是整个资产收益的波动率,而相对风险关注的是资产收益与某一基准(比如某个市场指数或投资组合)相比较的跟踪误差。
市场风险也可以按照与经济和金融变量(比如,利率、股票指数)的关联性分为直接风险和间接风险:直接风险指的是与这些基准经济金融变量线性相关的风险(比如债券、股票、期货),而间接风险则是与这些变量有非线性关联成分的风险(比如,期权、复杂衍生品)。
度量市场风险目前最常用的工具是在险价值(Value at Risk, VaR)。
VaR的定义与计算方法
VaR度量的是在一段时间内某种置信水平下某风险资产的可能损失。比如,某个投资组合在95%置信水平下的日度VaR是10万元,表示在任何交易日,该资产的损失只有5%的可能会超过10万元。
VaR在金融机构中使用非常普遍,很多机构设置内部VaR进行止损,如果某天损失超过内部VaR,就需要马上清空仓位进行止损。
正态分布法
正态分布法假设收益率服从正态分布,运用矩估计可以简单求得:
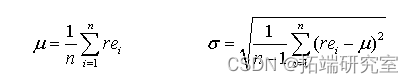
此时所求的在置信水平![]() 下的VaR就是:
下的VaR就是:
![]()
例 假设某银行的风险管理部门希望以正态分布法计算日度的VaR,其资产的标准差为1.4%,且资产当前市值为5300万元,请计算其95%置信水平下的VaR。
答: 标准正态的下5%分位点为-1.65,则其收益率的VaR是-1.65×1.4%=-2.31%,其总资产的VaR就等于2.31%×5300万元=122430元,即单日损失超过122430元的可能性仅有5%。
因为日度的标准差可以简单的通过变换来得到月度、季度或是年度的标准差,在正态分布法的框架下,VaR也可以由此进行变换,得到其他期限状况下的VaR:
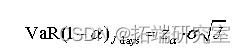
日度损失换算成年度则是
![]()
例:以R编程实现正态分布法非常简便,以HS300指数2014年的日数据为例,其99%置信水平下的单日VaR可以通过以下一段R代码来计算。
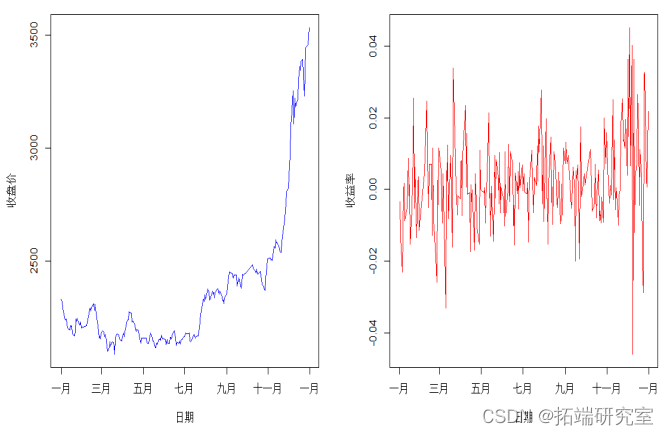
首先画出HS300指数在2014年的时序图和日收益率图,其R代码和图表如下:
-
HS300date<as.Date(HS30$e)将导入数据中的日期识别为日期格式的序列
-
n<-now(HS0) #计算样本的观测数
-
re<log(HS300$close[2:n]/HS300$close[1:(n-1)]) #计算日收益率
-
par(fro=c(1,2)) 将图表工作区分为2列画图区
-
plt(HS300dte,HS00$close,typ='l',col'b,xlab='日期', ylab='收益率') #画出日收盘价和日收益率的时序图
然后针对收益率序列估计其均值和方差,并计算VaR:
-
#正态分布法
-
-
alha<-0.99 #设定置信水平
-
-
s0<-HS30$cse[n] #设定初始资产价值
-
-
m-mean(e) #计算均值
-
-
sgma-sd(e) #计算标准差
-
-
daR<-(musiga*qorm(alpa,0,1)) #计算每日VaR
-
-
VaR<-*sigma*qnormalph,0,1)*qrt(52) #计算全年VaR,假设日收益率为0.
最终的计算结果为,在99%置信水平下,持有HS300股指的每日最大可能损失2.64%,在2014年年末预计明年最大可能损失为1542.94点。
针对某些衍生品或投资组合,如果其资产价值与某个风险因子呈线性关系,也可以通过正态分布法来计算VaR,此时该方法称为Delta-Normal法:
![]()
厚尾分布法
实际中虽然正态分布法使用最多,但有时也需要考虑到收益率分布不是正态的情形。事实上,资产收益率在实证中已经被发现大多数时候有尖峰厚尾的现象,即尾部的分布密度较正态分布要大,从而导致实际收益分布的下分位点大于正态分布的分位点。此时就需要考虑采用一些对于厚尾分布有所度量的分布。
Weibull分布可以对于厚尾性质有所度量。当然其他类型的如Beta分布,对数正态、Gumbel分布等也可以度量厚尾,具体的思路和计算方法与此相同,这里主要以Weibull分布为例进行介绍。Weibull分布密度函数形式如下:
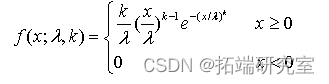
Weibull分布函数要求随机变量大于0,实际中可以通过指数变换得到。使用这些厚尾分布估计收益率的分布时,大多数采用极大似然估计法,用R中的mle函数或者optim函数可以很方便地实现。同样考虑例6.2中的HS300指数日度数据,其采用Weibull分布法计算VaR的R代码如下:
-
#weibull分布法
-
rdata<-ex(re) #将收益率数据指数化,使其保持大于0
-
lgbull<untion(params){ #写出对数似然函数
-
labda-pram[1] #规模参数(scale parameter)
-
k<-aram[2] #形状参数 (shpe araete)
-
-
for(i in 1:n){ #用循环计算对数似然函数之和lgw<lg+log(k/lmba)((reata[/labda(k-1)*exp-(reata[i]labd)^k))
-
-
xle<-otimc(1,),lgwbul,ethod BFS,contlist(nscal=-1)) #用优化函数求解最大值,初始参数设都是1
-
ambda<-xme$par[1] #求得规模参数
-
k<-ml$par[2] #求得形状参数
-
dVaR<-lg(qeibul(1-alpa,k,ambda)) #求解得到分布的上1%分位点
Weibull分布法得到的99%置信水平下每日最大可能损失是5.59%,比正太分布得出的VaR高得多,体现了Weibull分布对于尾部和极端风险给予了更大的重视,显得更加保守。
历史数据排序法
历史数据排序法非常简单,只需要将历史的收益率序列按照升序排列,假设序列长度为n,设与n*5%往上最接近的整数为K,则95%置信水平的VaR就是第K个收益率序列值。
例 假设你资产的初始价值为1亿元,你将最近100天的每日收益率从低到高排序,最低的6个收益率如下:
-0.0101,-0.0096,-0.0034,-0.0025,-0.0019,-0.0011
则此资产在95%置信水平下的VaR为0.0019×1亿=19万元。
有时并不会往上取与n*5%最近的整数,而是将最接近此数值的两个收益率求平均来得到更准确的VaR。排序在R中也可以简单实现,同样以HS300指数为例,其代码如下:
-
#历史数据排序法
-
re<sor(redecresin=T) #按降序排列
-
orer<trunc(*alha) #求取99%分位点所指示的序号的整数部分
-
-
if(nrde==n){aR<-sr[n]}else{
-
da<-(sre[rder]+sener])/2 #对该序号周围的2个值求平均
-
}
最后计算得到在99%置信水平下,每日最大可能损失为2.58%,略小于正态分布法得到的VaR。
核密度估计法
核密度估计法是统计中常用的估计分布函数序列值的非参数方法,其基本的算法形式是:
R中有专门进行核密度估计的包Kernsmooth.同样以HS300指数日度数据为例,以核密度方法计算VaR的R代码如下:
常见的核函数有高斯核、均匀核、三角函数核等等,我们以高斯核为例讲述这类方法,高斯核函数就是标准正态分布密度函数:
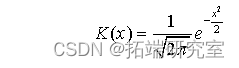
求得核密度函数序列之后,就可以通过对收益率升序排列之后的核密度函数累加,当累加值达到5%时,选取其附近的两个收益率平均值作为95%置信水平的VaR估计值。
R中有专门进行核密度估计的包Kernsmooth.同样以HS300指数日度数据为例,以核密度方法计算VaR的R代码如下:
-
#核密度估计法
-
ds<-density(re,w = "nrd0", djust= 1,
-
keel = c("gaussn",n=1000) #计算出核密度函数,核密度函数的观测数设定为1000,使用的是Gaussian核。
-
cumy<-c(0,1000)
-
for(i in 1:1000){umy[]<-sum(dsy[1i])*ds$} #计算出累积密度函数函数值,其中ds$bw是核密度估计时所使用的窗宽
-
for(i in 1:1000){ifcmy[i<(-alpha){node<-i}} #找出最后一个累积密度函数低于1%的序号
-
dVR-(ds$x[noder](cum[norder+]-1+alp)+dsxnordr+1(1-ala-cumy[e]))(umy[rer+-cuyorde]) #用插值法找出核密度估计出的观测序列的上1%分位点。
最后计算出的99%置信水平下,每日最大可能损失值为4.96%,远大于正态分布法所得到的数值,与Weibull分布法得出的数值较为接近。
混合时间序列加权法
混合时间序列加权法也称为Hybrid方法,是一种半参数的方法。其基本思想是对于近期发生的价格变化赋予更大的权重,但需要注意的是,并不是在收益率上直接赋权(这可能改变收益率的原始数值),而是对收益率在历史数据排序法中的排序赋权。其基本算法步骤如下
步骤1:对于收益率序列给出其权重序列:
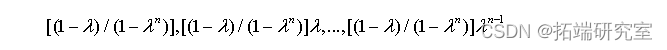
其中lamda是退化参数,取值在0和1之间,常见的取值有0.96,0.97,0.99等。如此最近一期的权重最大。
步骤2:对收益率升序排列
步骤3:将从低到高的收益率序列对应的权重累加,若累加值达到所需的显著性水平,比如5%,则可以通过线性插值法计算出对应的VaR。
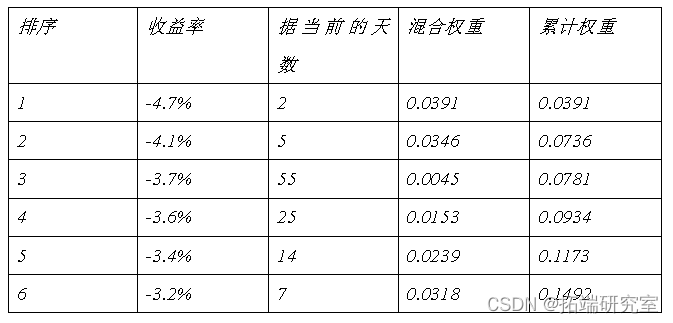
表中0.05位于排序1和2之间的收益率,即-4.7%和-4.1%之间,则可以使用线性插值法计算VaR=(0.05-0.0391)/(0.0736-0.0391)×(-4.1%)+(0.0736-0.05)/(0.0736-0.0391)×(-4.7%)=-4.51%,即利用混合时间加权法得出的95%置信水平下的VaR是4.51%。
混合时间加权法也可以通过R简单实现,以HS300指数日度数据为例,其R代码如下:
-
#混合时间加权法
-
weight-ep(0,n) #计算出每个收益率的权重,距离当前越近的观测权重愈大。
-
data<-sa[oere,dreing=F),] #通过对数据框的排序得到升序的收益率及其对应的权重
-
cumweght<-rep(0,n) #用循环计算累积权重,并求出第一个超过1-alpha的序号
-
if(cumweight[1]>1-alpha){norder<-1} #当第一个就超过了1-alpha,就需要直接令序号等于1.
-
if(cmweght[i]<1-lha){noder-i}}
-
ifnorer>1){ #用插值法计算每日VaR
-
dVaR<-(kata$r[nordr]*(cmeigorr+1-+aha)+da$enorer+]*1-pa-cuweit[order])/(cuwig[nrde1]-cumweght[norder])
-
}else{VaR-kdtae[1]}
计算得到最小的日收益对应的权重已经大于1%,故而选择最小的日收益作为混合时间加权法的VaR,即99%置信水平下每日最大可能损失为4.59%。混合时间加权的优点在于不改变原始数据,所求得的VaR必然是原始数据或其线性组合。如果置信度设为95%,重新运行程序得到每日的最大可能损失为2.19%。
蒙特卡罗模拟法
之前介绍的这些方法都是在历史数据充分,且资产结构本身比较简单的情况下才比较有效的VaR计算方法。当资产结构变得复杂,比如有复杂的衍生产品,或资产价格变动的历史数据不足,或者需要考虑更复杂更严格的价格变化过程时,就需要使用随机模拟的方法来确定价格变化的过程和VaR。
最简单的MonteCarlo模拟方程就是以正态分布来模拟收益率的序列。在假设均值和波动率已知的情形下,考察收益率的可能变化水平:

VaR的回测
在学习VaR的回测方法之前,有必要复习一下假设检验的基本原理。假设检验的基本逻辑是:小概率事件不可能发生。若在原假设下,小概率事件发生了,则可以怀疑原假设不成立,由此拒绝原假设。
例题: VaR的滚动计算与回测:从中证800中任选一只股票,选定2013年至今的日度收盘价序列为研究样本,以90天为窗宽,以正态分布法滚动计算日度95%VaR,并画出收盘价时序图和VaR预测的最坏变化图进行对比。并以样本外一天是否超过VaR的次数来回测VaR。
编程的要点如下:
输入项:中证800的股票成分向量;取数据的方法:随机选择一只股票后,用quantmod包的getSymbols函数取数据。
主要算法:产生随机数并判别上市时间是否早于2013年;根据取出来的时序数据计算收益率,并以每90天计算一个VaR,共n-90个VaR,可以回测n-91次。
输出项:收益率和VaR的时序图;VaR回测中损失超额的次数和判定结果。
R代码如下:
-
-
coe1-sust(zz800$ID[sn],1,2)
-
code2<-sbst(zz80$ID[sn],3,8)
-
-
close<-zdata[,4]
-
-
### VaR
-
-
a
-
-
re<-log(close)-log(lag(close))
-
-
-
# tdate<-NULL
-
len<-90
-
-
-
-
-
for(i in 1:(n-len-1)){
-
mu-mea(re[(i+1:(i+len)])
-
-
sigma<-sd(re[(i+1):(i+len)])
-
-
dva[i]<-(m-sigma*qnorm(-alpha0,1))
-
-
if(re[i+1+le]<dvar[i]bcktest<-backtet+1}#次日收益低于昨天的VaR就记录一次损失超出事件
-
-
-
backalpha<-0.05
-
-
cvale<-qnom(bakapha-2-len,lp
-
if(backtes>cvalue)bkreult<-'reject'}else{bkresult'acept'} #判定是否接受VaR的计算结果
-
-
-
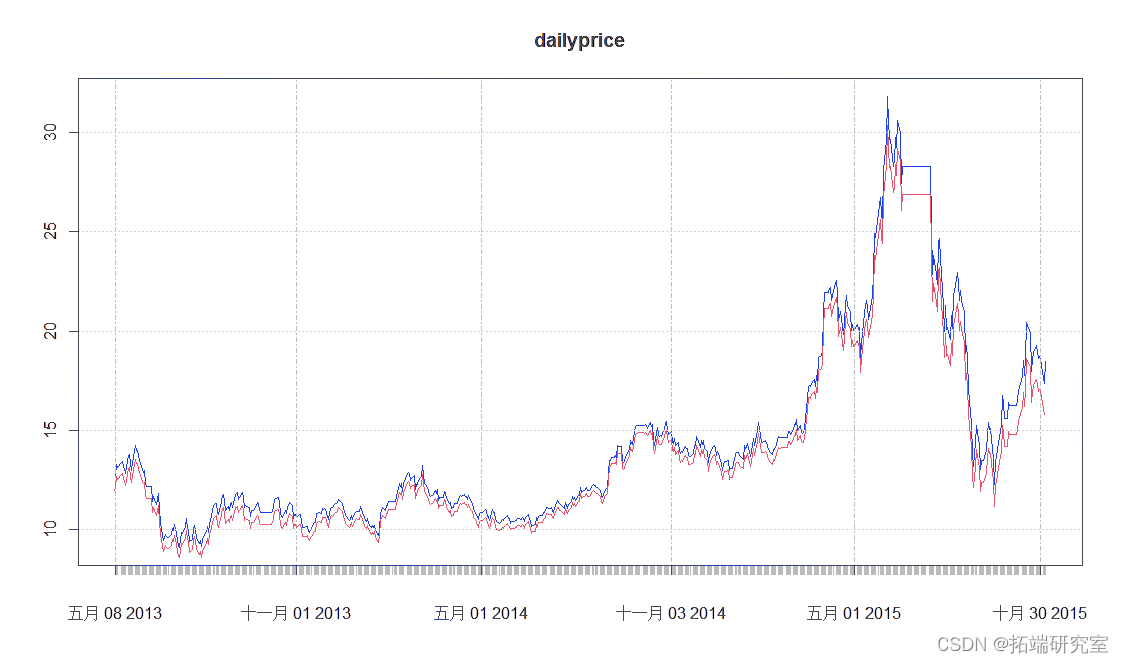
##将VaR的计算结果所显示的最低可接受价格与当天的实际价格画在一张图表上
-
plo.ts(aiypice)
-
lines(Vaprdic,cl='red')

结果示例:
自测题:
从中证800中任选一只股票,选定2012年至今的日度收盘价序列为研究样本,以60天为窗宽,以核密度估计法滚动计算日度95%VaR,并画出收盘价时序图和VaR预测的最坏变化图进行对比。并以样本外一天是否超过VaR的次数来回测VaR,判定VaR的计算是否合理。
信用风险与分类模型
信用风险指的是在金融交易中,由对手方可能的违约带来的风险。信用事件可以狭义地定义为债券的违约(Default on a bond),即债券发行机构无法支付承诺的利息支付或本金偿还, 但广义的来说,信用风险的变化就可以被称作信用事件。
信用风险其实包含了很多维度的风险,其变化经常是难以预计的,但在商业社会中,信用风险往往具备双向性,其变化的方式通常服从下图所示的模式:
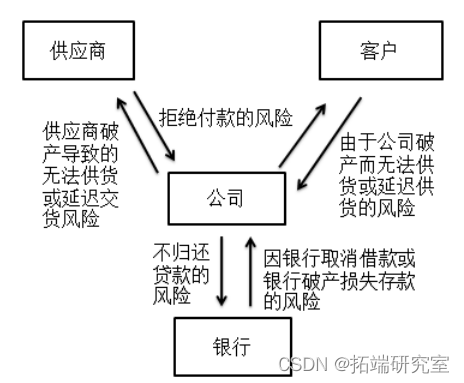
信用风险计量有如下关键指标:
违约概率(probability of default, PD):客户在一定时间内违约的可能性,对应于客户信用评级,一般将违约概率转换为客户的信用评级。
违约损失率(loss given default, LGD):违约发生时风险暴露的损失程度,对应于债项评级。
风险暴露(exposure at default, EAD):违约发生时可能发生损失的贷款额。
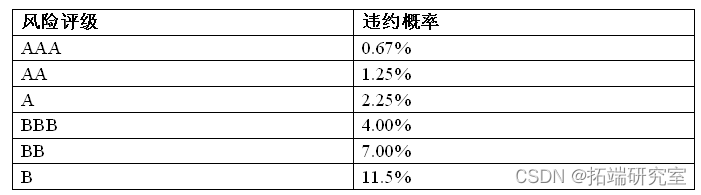
违约概率是指债务人未来发生违约的可能性大小,获得违约概率最普遍的方法是根据一组具有相同风险特征的债务人的违约历史纪录,计算发生违约的比率,作为类似债务人未来违约概率的估计。PD由债务人主体的信用水平决定,所以,PD常用于对公司或其他主体进行信用评级。以下是某评级机构的对公贷款的评级情况:
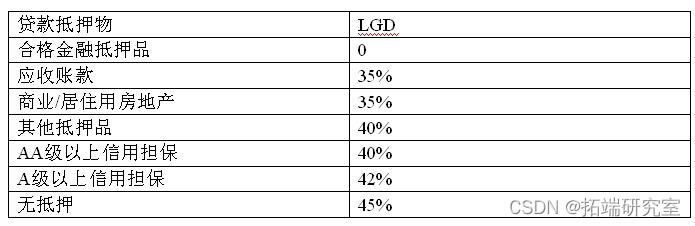
违约损失率(LGD)反映一旦债务人违约将给债权人造成损失的严重程度,计算方法是违约后损失的金额与违约前总的风险头寸暴露之比。LGD决定了贷款回收的程度,LGD=1-回收率。对于同一债务人,不同的交易可能具有不同的LGD。对于同一债务人的两笔贷款,如果一笔提供了抵押品,而另一笔没有,那么前者的LGD将可能小于后者的LGD不仅受到债务人信用能力的影响,更受到交易的特定设计和合同的具体条款,如抵押、担保等的影响。根据贷款的不同,其LGD的分布情况的例子如下:
风险暴露(EAD)在不同的信用事件中有不同的定义:
1) 固定本金贷款 :EAD = 债项帐面价值+ 应收利息
2) 未来不确定款项(贷款承诺、循环额度等) : EAD = 已使用的额度+ 应收利息+ 未使用额度中预期提取金额
3) 衍生工具: EAD=市价+风险溢量
本课主要介绍的是用分类模型来识别违约可能或预测PD的方法。分类模型的基本做法是,对于给定的一系列企业的指标(数据来源可能是许多同质企业,或者各类型的企业都有),然后以一段时间的考察期,观察企业是否发生违约,并以此考察期内的所有观测作为训练样本,就可以估计分类模型,之后再通过估计出的分类模型来判别一家新的企业是否会违约。基本的分类模型包括:线性判别分析、Logit模型、Probit模型、支持向量机、决策树、神经网络、Lasso回归等方法。
下面以Logit回归模型为例介绍使用分类模型法进行PD预测的主要步骤。
步骤1: 数据准备
首先需要确定模型用于训练和验证的样本,例如,可以按70%和30%的比例随机抽取总体样本中的观测分别作为训练样本和验证样本;然后奇异值和缺失值进行处理,常见的方法包括直接删除、中位数填充、插值法等等。直接删除是删除某个日期内出现了指标缺失情况的企业观测,该方法虽简单,但有可能导致样本不足;中位数填充指的是用其他未缺失的指标值的中位数代替缺失值进行填充;插值法可以是通过指标的时间序列变化来进行插值。
步骤2:变量构建
尽量收集全所有跟违约率有关的财务指标、宏观经济指标、行业景气指标和市场指标,比如针对财务报表,如下的一些财务比率数据就可以计算出来:
- 经营活动–例如存货周转率、预售账款与销售成本的比率、等等
- 资本结构–例如固定资产占总资产比率、流动债务(current debt)占总债务的比率、等等
- 债务偿还能力–利息比率(利息支出/总收入)、总债务/总资产、等等
- 杠杆–资产负债率(总负债/总资产)、总负债/股东权益、等等
- 流动性–快速比率((现金+应收款)/流动负债)、现金比率(现金及现金等价物/流动负债)、等等
- 盈利性–利润率、资本回报率、等等
而宏观经济指标如工业增加值增速、CPI、PPI、PMI等也可以收集起来。
步骤3:模型建立
经典的Logit回归模型的形式是:
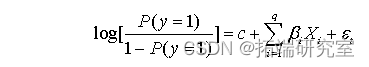
该模型主要包括3个部分:
- 随机性部分:一个二元反应变量y,y = 1 or 0 ,即事件可能发生或不会发生。对于银行评级而言,y = 1即指违约事件,y = 0则为非违约事件。我们关注的是“y = 1”出现的概率,用P(y=1) 表示。
- 系统性部分:线性预测值在PD预测中,财务因素多为连续变量,而一些关于企业的定性数据绝大多数转化为非连续变量。
- 关联函数:关联函数能够将反应变量Y的随机性部分和系统性部分联系起来。Logit回归法中使用的关联函数为经典联系函数,自变量P的经典联系函数(logit(P))是某一事件发生机率的对数,即logit(P) = log(P/(1 − P))
最后,各个主模型的PD结果通过Logit回归导出:
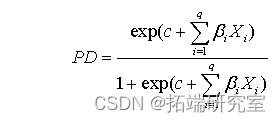
一般来说,在PD预测公式中会用到4到8个财务因素,而可能用到的定性因素也在4个左右。
步骤4:模型评价
在将PD预测出来之后,其实模型的分类工作就基本完成,可以假设PD超过一个阈值的观测将会发生违约,然后与实际数据(验证样本)对比,来评价模型的预测效果。常见的评价指标包括简单的基于假设检验的Neyman-Pearson原则,以及ROC曲线。
Neyman-Pearson原则指的是模型的第一类错误和第二类错误应该满足一定的条件。第一类错误(Type I Error)指的是将违约企业误判为不违约的企业,第二类错误(Tyep II Error)指的是将不违约的企业误判为违约企业。Neyman-Pearson原则要求,第一类错误率和第二类错误率应该满足如下的关系式:

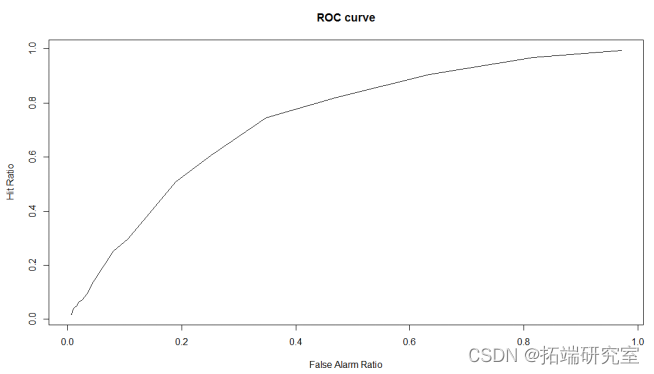
接收操作特征曲线(receriver operating characteristic, ROC): ROC曲线及AUROC系数主要用来检验模型对客户进行正确排序的能力。ROC曲线描述了在一定累计正常客户比例下的累计违约客户的比例,模型的分别能力越强,ROC曲线越往左上角靠近。AUROC系数表示ROC曲线下方的面积。AUROC系数越高,模型的风险区分能力越强。在下图6.8中,AUROC系数表示ROC曲线下方的面积。
ROC曲线下面积的大小可以作为模型预测正确性高低的评判标准。即AUROC系数越大,表示该模型的区分能力越好。
除了采用Logit模型分类之外,常用的分类方法还有probit模型、最近邻方法、支持向量机、神经网络等。
Probit模型
Probit模型与Logit模型非常类似,只是关联函数变成了正态分布,即
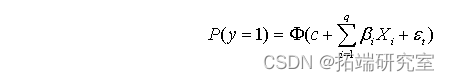
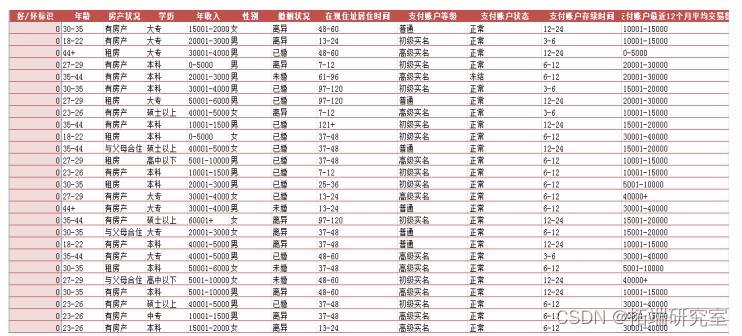
如下所示的表格是某个需要分类的样本的训练集和测试集(只显示前27行)。该样本是某互联网企业注册用户的信用调查表,调查了用户的年龄、性别、收入、住房、居住时间等状况,同时收集了支付账户等级、支付金额等数据,并且按照其之前的违约情况,将客户分成了好客户和坏客户。总的客户数量有3万个,其中坏客户(有过明确违约情况的)仅有688个。将前15000个作为训练样本,后15000个作为需要分类验证的样本。
那么针对该样本,先在Excel中将有序数据全部用自然数代替之后,再使用Logit回归进行分类的R代码如下:
-
#设定工作空间路径
-
#读取数据,并清洁数据(将缺失简单记作0)
-
fdata<-rea.sv('reitdtacsv'headT,strngAsFctrs=F)
-
-
m-roud(n/2)tdata-fdat[1:m];vdaa<-fat[(m+1):n,] #分出训练样本和验证样本
-
#使用训练样本估计Logit模型
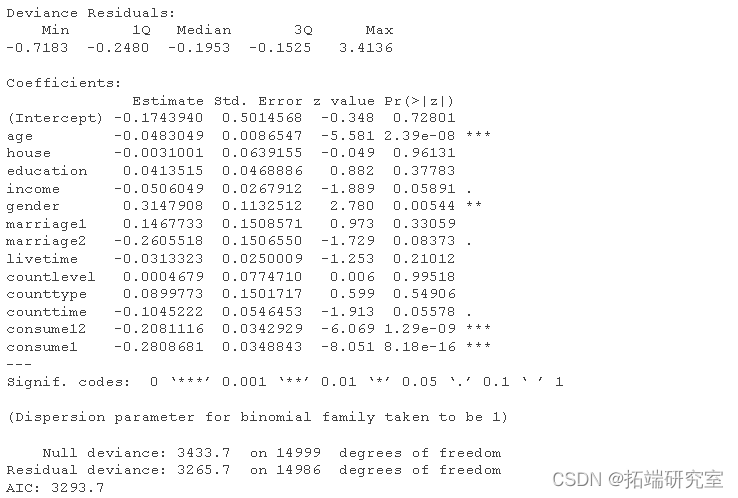
模型估计出的结果如下:
-
-
-
k<-predit.glm(,vat,type="resone",se.fit=T) #用估计出的模型拟合验证样本
-
-
###计算预测情况表格
-
maa <- data.frame(pdft = prdited, df = vta$deflt) #预测值和真实值表格
-
-
nr1<-0; nr2<-0 #令原假设是客户不违约,统计第一类错误和第二类错误的次数
-
-
Ptble<-rbind(Pefult,Pnefult) #预测表现
-
##NP值计算
-
r1<-nr1/sum(ata$df==0) #第一类错误率
-
r2<-nr2/sum(mdt$df) #第二类错误率
-
NP<-r1/(1-r2) #NP值
-
-
###画ROC曲线
-
-
#计算命中率和误警率
-
HR<-sum(pft==vatadefultpt==1)/sum(vda$deft)
-
-
}
-
plot(TFR, THR, o") #画出ROC曲线
例子: 从中证800中任意抽取一只股票,选取2012年至今的数据,构建如下指标,每60天的VaR(置信水平75%),每60天的波动率,每60天的累积交易量,每60天的离差(最大减最小),然后计次日的收益率低于昨日收盘算出来的VaR为违约事件。试使用如下的Logit模型拟合违约概率:
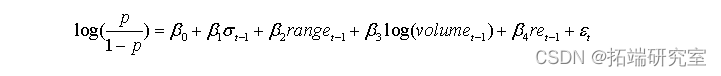
以2012年至2014年的数据为样本内,2015年数据为样本外数据。请报告Logit模型的样本内回归结果和样本外分类效果。
编程的代码如下:
-
-
##提取数据中的收盘价、交易量、最高价和最低价序列
-
cose-zdata[,4]
-
volm-zdata[,5]
-
high<-zdata[,2]
-
lo<-zdata[,3]
-
M15<-length(clos) #计算2015年的日期数
-
-
### VaR
-
-
defaut<-rep(0,n-len-1)
-
pre<-rep(0,n-len-1)
-
fori in 1:(n-len-1)){
-
mu<-mean(re[(i+1):(i+len)])
-
-
range[i]<-log(high[ (i+len)])-log(low[(i+len)])
-
-
}
-
-
-
indata<-tdata[1:(N-M15),]
-
outdata<-tdata[(N-M15+1):N,]
-
-
##logit 模型
-
km<-predict.glm(pm,outdata,type="response",se.fit=T)
-
predicted<-km$fit
-
###计算预测情况表格
-
mdata <- data.frame(pdft = m$fit, df = outa$deault) #预测值和真实值表格
-
nr1<-0; nr2<-0 #令原假设是客户不违约,统计第一类错误和第二类错误的次数
-
-
Ptable<-rbind(Pfalt,Pndefault) #预测表现
-
-
##NP值计算
-
r1<-nr1/sum(mdata$df==0) #第一类错误率
-
r2<-nr2/sum(mdata$df) #第二类错误率
-
NP<-r1/(1-r2) #NP值
-
-
##ROC
-
-
plot(TFR,THR,type='l',main="ROCcurve",xlab="FalseAlarmRatio",ylab="Hit Ratio")
-
-
自测题
从中证800中随机选择50只股票(报告这50只股票的代码),选取其2012年至今的数据进行如下的计算。
- 采用前3支选出来的股票和50支股票的等权重价格指数序列,以60天为时间窗口,计算95%置信水平下的单日VaR序列。画出这些VaR序列的时序图(4幅图)。
- 在5%的显著性水平下,对上面计算出的VaR序列进行回测,报告回测的结果(违反次数,是否接受),并分析个股和指数在VaR取值和回测上的差异性。对于回测不合格的股票或等权重指数,画出其回测日的收盘价和对应的VaR预测出的最坏可接受价格曲线,分析哪些交易日容易出现低于VaR预测的最坏价格的情形。
- 对于这50支股票,以90天为窗口计算最后选出来的3支股票的75%置信水平的单日VaR,并将收盘价低于VaR预测的最坏价格水平的交易日记为违约日,其余日期为不违约日。采用Logit模型,以昨日对数交易量、最近90天波动率、昨日价格振幅为因子,以2012至2013年的数据为训练样本,2014至今的数据为预测样本,对违约概率进行拟合和预测。报告拟合结果(Logit模型估计结果)和预测效果(包括NP值和ROC曲线)。

最受欢迎的见解
1.R语言基于ARMA-GARCH-VaR模型拟合和预测实证研究