原文链接:http://tecdat.cn/?p=22732
原文出处:拓端数据部落公众号
关联规则分析是一种揭示项目如何相互关联的技术。关联规则分析也称为购物篮分析。在这篇文章中,我将解释关联规则模型以及如何在R中提取关联规则。关联规则模型适用于交易数据(查看文末了解数据获取方式)。交易数据的一个例子可以是客户的购物历史。
视频:R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
关联规则模型、Apriori算法及R语言挖掘杂货店交易数据与交互可视化
,时长07:03
问题
当我们去杂货店购物时,我们通常有一个标准的购物清单。每个购物者都有一份独特的清单,具体取决于个人的需求和偏好。家庭主妇可能会为家庭晚餐购买健康食材,而单身汉可能会购买啤酒和薯条。了解这些购买模式可以通过多种方式帮助增加销售额。如果有一对经常一起购买的物品 X 和 Y:X 和 Y 都可以放在同一个货架上,这样会提示购买一件商品的买家购买另一件商品。
虽然我们可能知道某些物品经常一起购买,但问题是,我们如何发现这些关联?

定义
方法一:支持度。这表示项目集的受欢迎程度,以项目集出现的交易比例来衡量。在下图中,啤酒 的支持度为5份中的 3 份,即 60%。
如果您发现超过一定比例的商品销售往往会对您的利润产生重大影响,您可以考虑将该比例作为您的支持度门槛。然后,您可以将支持值高于此阈值的项集标识为重要项集。

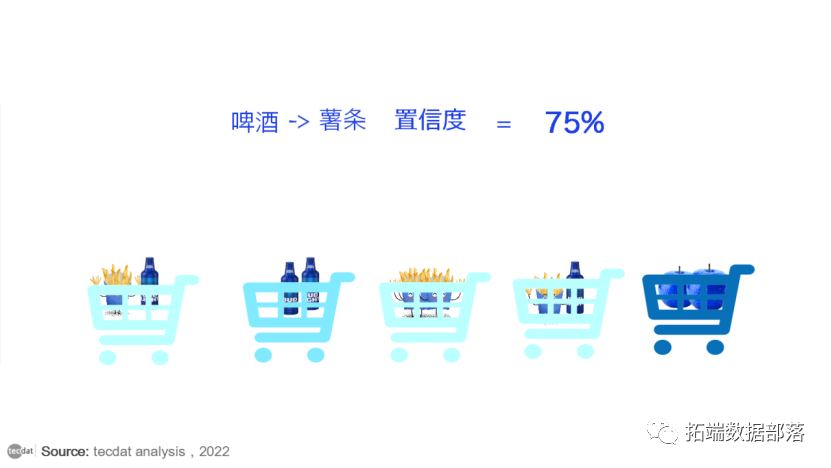
方法2:置信度。这表示在购买商品 X 时购买商品 Y 的可能性有多大,表示为 {X 箭头 Y}。这是通过与项目 X 的交易比例来衡量的,其中项目 Y 也出现。在交易中,啤酒对薯条的置信度为3份中的2份,即67%。
置信度度量的一个缺点是它可能会歪曲关联的重要性。这是因为它只考虑了啤酒的受欢迎程度,而不考虑薯条。如果薯条通常也很受欢迎,那么包含啤酒的交易也将包含薯条的可能性更高,从而夸大了置信度。为了说明这两个组成项目的基本受欢迎程度,我们使用了第三种度量,称为提升度。
方法3:提升度。这表示在购买商品X时购买商品Y的可能性有多大,同时控制商品Y的受欢迎程度。在上述交易 中,啤酒 对 薯条 的提升为1.11,这意味着项目之间有关联。提升值大于 1 表示如果购买了商品 X,则很可能购买商品 Y,而小于 1 的值表示如果购买了商品 X,则不太可能购买商品 Y。

但是,企业主通常不会询问单个项集。相反,所有者会对拥有完整的流行项集列表更感兴趣。要获得此列表,需要计算每个可能的项目组合的支持值,然后将满足最小支持阈值的项目集列入候选名单。
在只有 10 件商品的商店中,要检查的可能组合总数将高达 1023 种。在拥有数百件商品的商店中,这个数字呈指数增长。
有没有办法减少要考虑的项目配置数量?

apriori算法
apriori原理可以减少我们需要检查的项目集的数量。简而言之,apriori原理指出,如果一个项目集是不频繁的,那么它的所有子集也必须是不频繁的。这意味着,如果发现 {苹果} 不常见,在合并流行项集列表时,我们不需要考虑 苹果和啤酒组合,也不需要考虑任何其他包含苹果的项集组合。
寻找高支持项集
使用 apriori 原理,可以修剪需要检查的项集的数量,并且可以通过以下步骤获得热门项集的列表:
步骤 0。从只包含一个项目的项目集开始,例如 {啤酒} 和 {草莓}。
步骤 1。确定项集的支持。保留满足最小支持阈值的项集,并删除不满足的项集。
步骤 2。使用您在步骤 1 中保留的项集,生成所有可能的项集配置。
步骤 3。重复步骤 1 和 2,直到不再有新项集。
下面的动画说明了这个迭代过程:
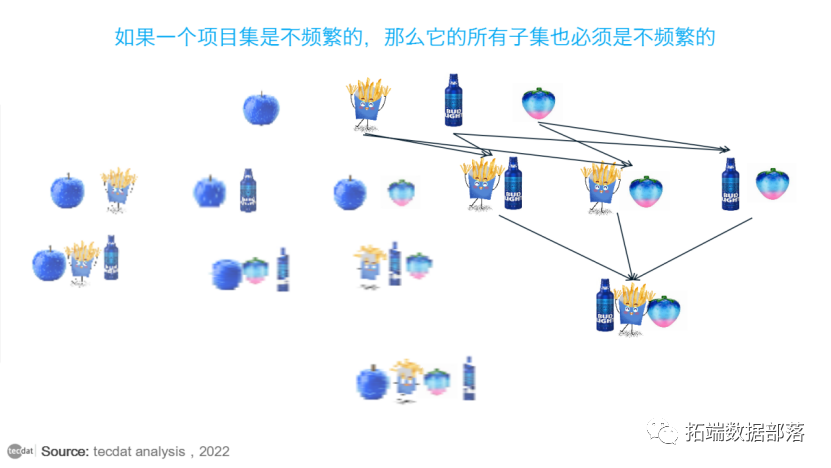
使用 Apriori 算法减少候选项集
正如动画中所见,{苹果} 被确定为支持度较低,因此将其删除,并且不需要考虑所有其他包含 苹果 的项集配置。这将要考虑的项目集的数量减少了一半以上。
请注意,您在步骤 1 中选择的支持阈值可能基于正式分析或过去的经验。如果您发现超过一定比例的商品销售往往会对您的利润产生重大影响,您可以考虑使用该比例作为您的支持门槛。
R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
关联规则挖掘是一种无监督的学习方法,从交易数据中挖掘规则。它有助于找出数据集中的关系和一起出现的项目。在这篇文章中,我将解释如何在R中提取关联规则。
关联规则模型适用于交易数据。交易数据的一个例子可以是客户的购物历史。
数据分析的第一件事是了解目标数据结构和内容。出于学习的目的,我认为使用一个简单的数据集更好。一旦我们知道了这个模型,就可以很容易地把它应用于更复杂的数据集。
在这里,我们使用杂货店的交易数据。首先,我们创建一个数据框并将其转换为交易类型。
读取数据
-
n=500 # 交易数量
-
-
trans <- data.frame() # 收集数据的数据框架
创建数据并将其收集到交易数据框中。
-
for(i in 1:n)
-
{
-
count <- sample(1:3, 1) # 从1到3的物品计数
-
如果(i %% 2 == 1)
-
{
-
if(!add_product %in% selected)
-
{
-
tran <- data.frame(items = add_product, tid = i)
检查交易数据框中的数据。

接下来,我们需要将生成的数据框转换为交易数据类型。
as(split(\[, "items"\], \[, "tid"\]), "transa")
为了检查交易数据的内容,我们使用 inspect() 命令。

挖掘规则
sort(rules_1, dby = "confidence")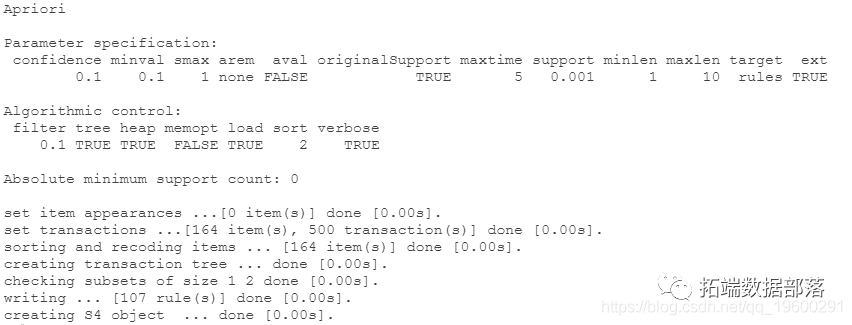
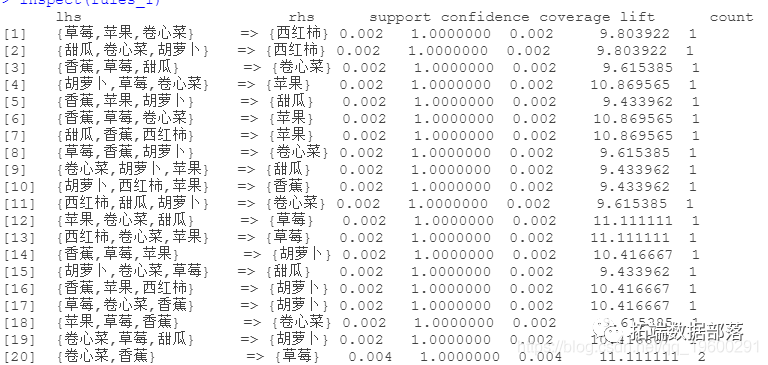
.......
我们从上面的列表中获取第一个rhs项(规则后项)来检查该项的规则。但如果你知道目标项目,可以在参数中只写rhs="melon"。
inspect(rules_1@rhs\[1\])
> rhs_item <- gsub("\\\}","", rhs)
我们为我们的rhs_item建立规则
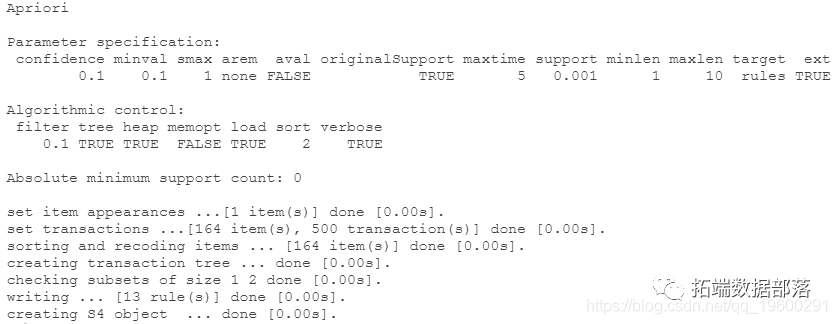
按 "置信度 "排序并检查规则
sort(rules_2, "confidence")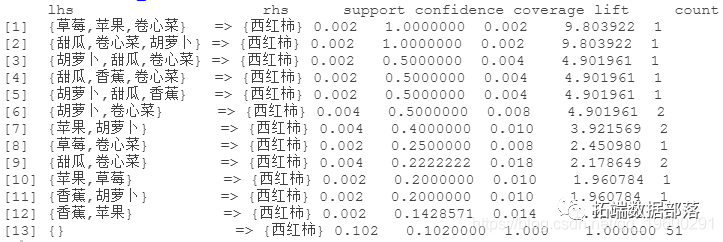
结果可视化
最后,我们从规则集_2中绘制出前5条规则。
> plot(rules_2\[1:5\])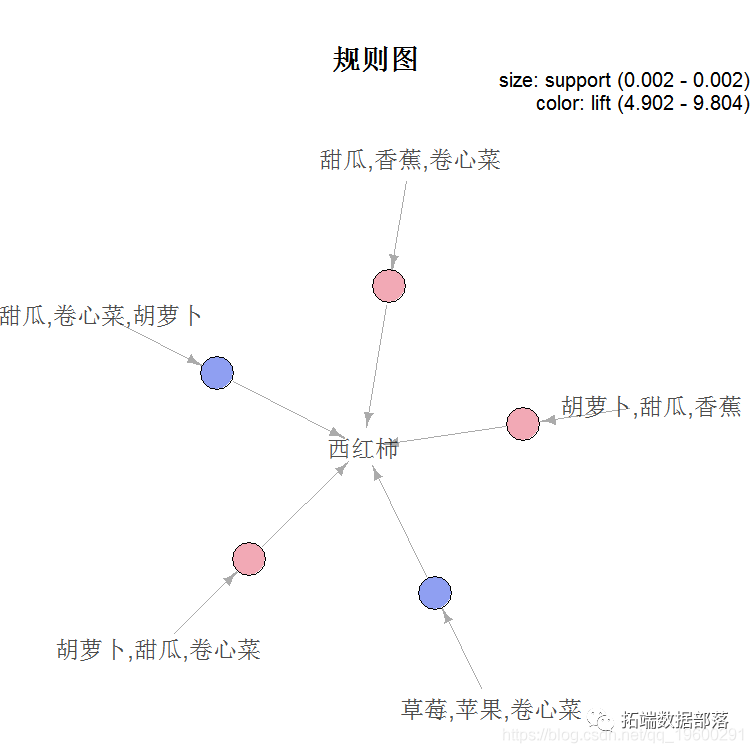
图1
绘制全部规则
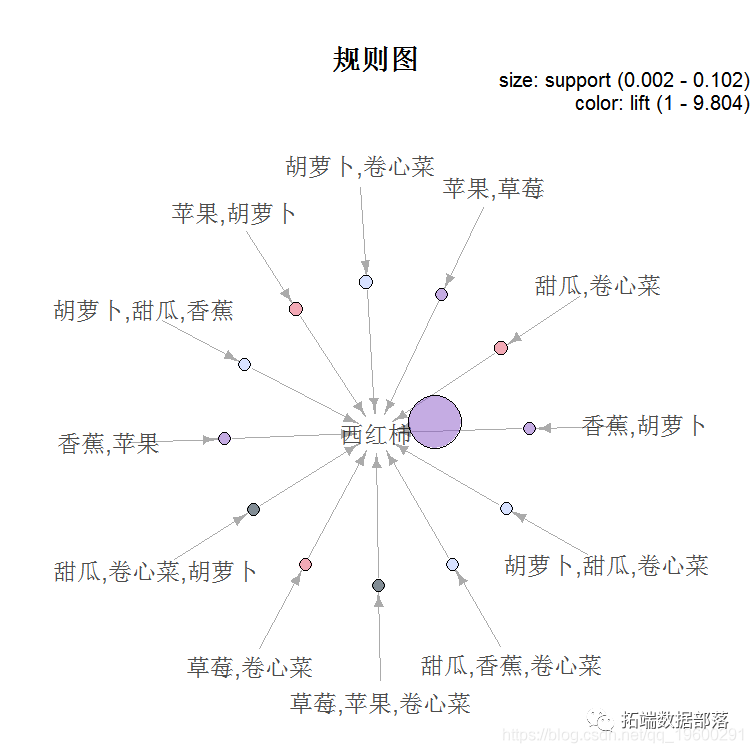
图2
交互可视化
绘制出前5条规则
-
precision = 3
-
igraphLayout = layout_nicely
-
list(nodes = nodes, edges = edges, nodesToDataframe = nodesToDataframe,
-
edgesToDataframe = edgesToDataframe,
-
x$legend <- legend
-
htmlwidgets::createWidget( x, width = width,
-
height = height)
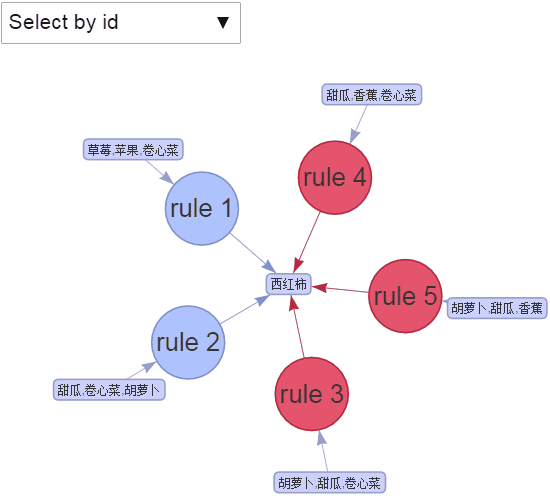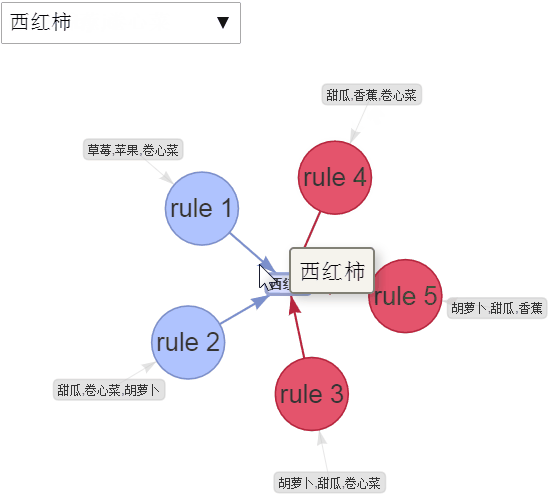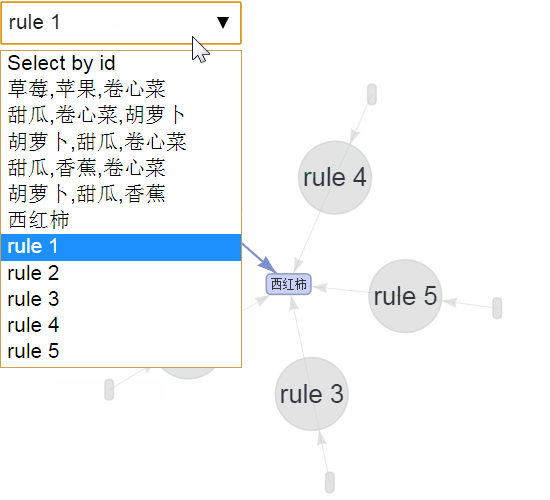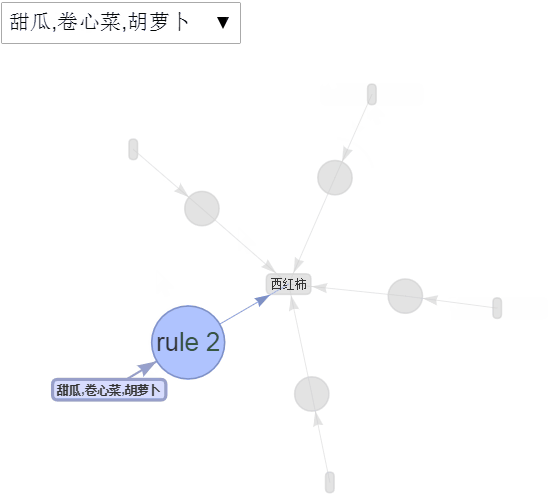
图3
绘制全部规则

图4
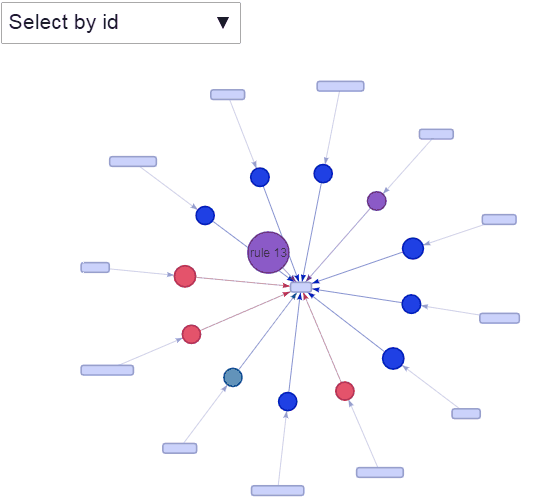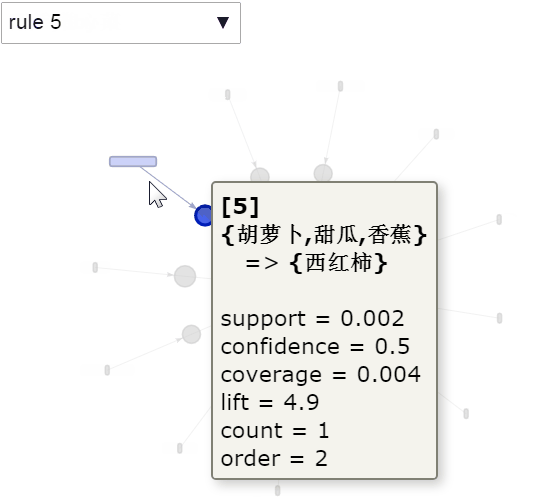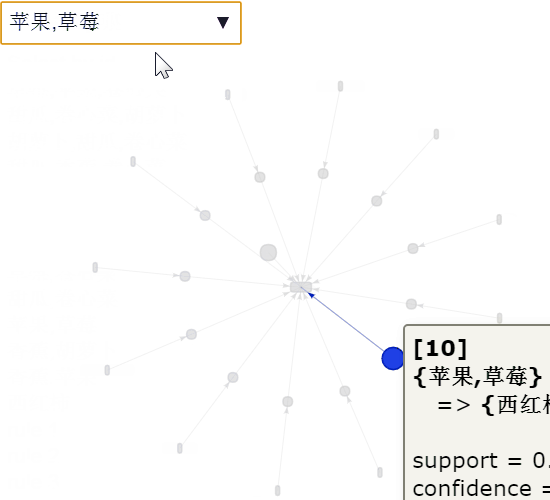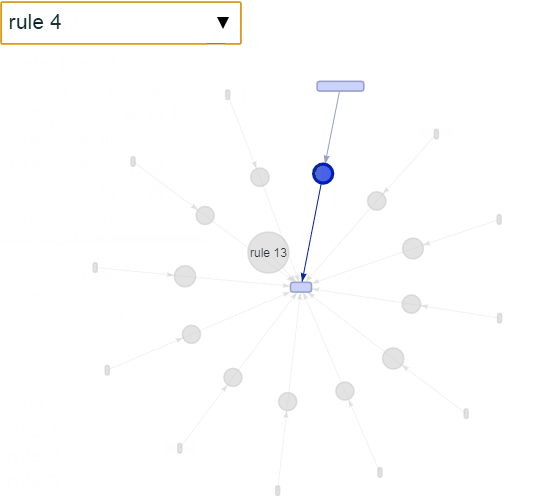
图5
数据获取
在下面公众号后台回复“商店数据”,可获取完整数据。

点击文末“阅读原文”
获取全文完整资料。
本文选自《R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化》。
点击标题查阅往期内容
用SPSS Modeler的Web复杂网络对所有腧穴进行关联规则分析
PYTHON在线零售数据关联规则挖掘APRIORI算法数据可视化
R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
python关联规则学习:FP-Growth算法对药品进行“菜篮子”分析
基于R的FP树fp growth 关联数据挖掘技术在煤矿隐患管理