原文链接:http://tecdat.cn/?p=9368
原文出处:拓端数据部落公众号
向量自回归 (VAR) 是一种用于多变量时间序列分析的统计模型,尤其是在变量具有相互影响关系的时间序列中,本视频中我们介绍了向量自回归并在R软件中进行实现。
视频:向量自回归VAR数学原理及R软件经济数据脉冲响应分析实例
【视频】向量自回归VAR数学原理及R语言软件经济数据脉冲响应分析实例
,时长12:01
为什么用向量自回归
为了能够理解几个变量之间的关系。允许动态变化。
为了能够得到更好的预测。
一组时间序列由多个单一序列组成。
我们在建立时间序列模型时说,简单的单变量ARMA 模型可以很好地进行预测。那么,为什么我们需要多个序列?
例子如:CPI反映的是通胀,CPI高了,通胀风险大,而抑制通胀最重要的手段就是加息,反之,当CPI很低,就说明经济不景气,那么就需要降息。降息之后刺激经济增长。因此,可能需要一个联合的动态模型来了解动态的相互关系 并可能做一个更好的预测工作。
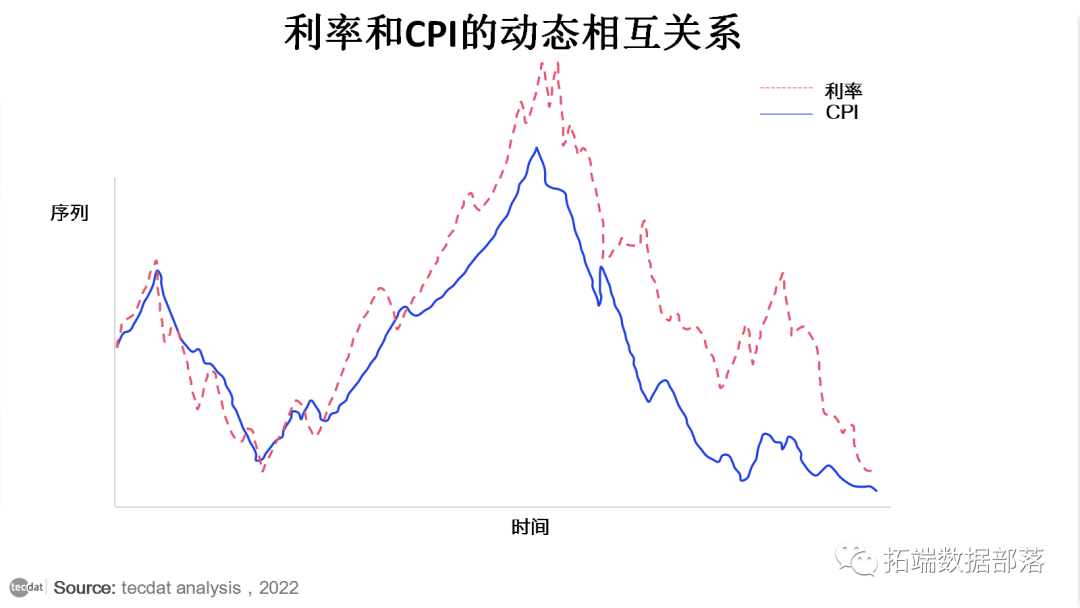
在观察 ARMA 和 GARCH 模型时,您会立即注意到估计和预测是针对一个变量进行的。在现实生活中,这并不成立。实际上,还有许多其他变量可能会影响其他变量。市场参与者和经济学家总是对宏观经济变量与他们有兴趣购买的资产之间的动态关系感兴趣。此操作可以帮助他们预测市场上可能发生的潜在情况。
使用 VAR 模型的基本要求是:
具有至少两个变量的时间序列。
变量之间存在动态关系。
它被认为是一个自回归模型,因为模型所做的预测取决于过去的值,这意味着每个观测值都被建模为其滞后值的函数。

ARIMA 和 向量自回归 模型之间的基本区别在于,所有 ARIMA 模型都用于单变量时间序列,其中 向量自回归 模型适用于多变量时间序列。此外,ARIMA 模型是单向模型,这意味着因变量受其过去值或滞后值本身的影响,其中 向量自回归 是双向模型,这意味着因变量受其过去值或另一个变量值的影响或受这两件事的影响。
什么是向量自回归
向量自回归模型是统计分析中经常使用的模型,它探索了几个变量之间的相互关系。
在开始建模部分之前,让我们先了解一下模型背后的数学。
单变量时间序列的典型自回归模型 (AR(p)) 可以表示为

其中
y t -i 表示较早时期的变量值。
A是一个时不变的 ( k × k ) 矩阵。
e t是一个误差项。
c是模型的截距。
这里的阶数 p 的意思是,最多使用 y 的 p滞后。
众所周知,向量自回归模型处理的是多元时间序列,这意味着会有两个或多个变量相互影响。因此,向量自回归 模型方程随着时间序列中变量数量的增加而增加。
假设有两个时间序列变量 y1 和 y2,因此要计算 y1(t),向量自回归 模型将使用两个时间序列变量的滞后。
例如,具有两个时间序列变量(y1 和 y2)的 VAR(1) 模型的方程如下所示:
其中,Y{1,t-1} 是 y1 的第一个滞后值,Y{2,t-1} 是 y2 的第一个滞后值。
![]()
我们可以清楚地了解模型的方程将如何随着变量和滞后值的增加而增加。例如,具有 3 个时间序列变量的 VAR(3) 模型方程如下所示。

所以这就是 p 值将如何增加模型方程的长度,而变量的数量将增加方程的高度。
选择模型的滞后数
有两种主要方法可以选择模型的滞后数:
经验方法,我们使用信息标准
推理方法包括使用假设检验

我们只考虑信息标准。有 3 个流行的信息标准,即:
赤池信息准则 (AIC)
施瓦茨-贝叶斯 (BIC)
汉南-奎恩 (HQ)
实际上,最佳滞后数是信息标准最小的滞后数。然后,我们估计 p=0,...,pmax 的 VAR(p) 并选择最小化 AIC、BIC 或 HIQ 的值 p。
向量自回归模型的估计包括以下步骤:
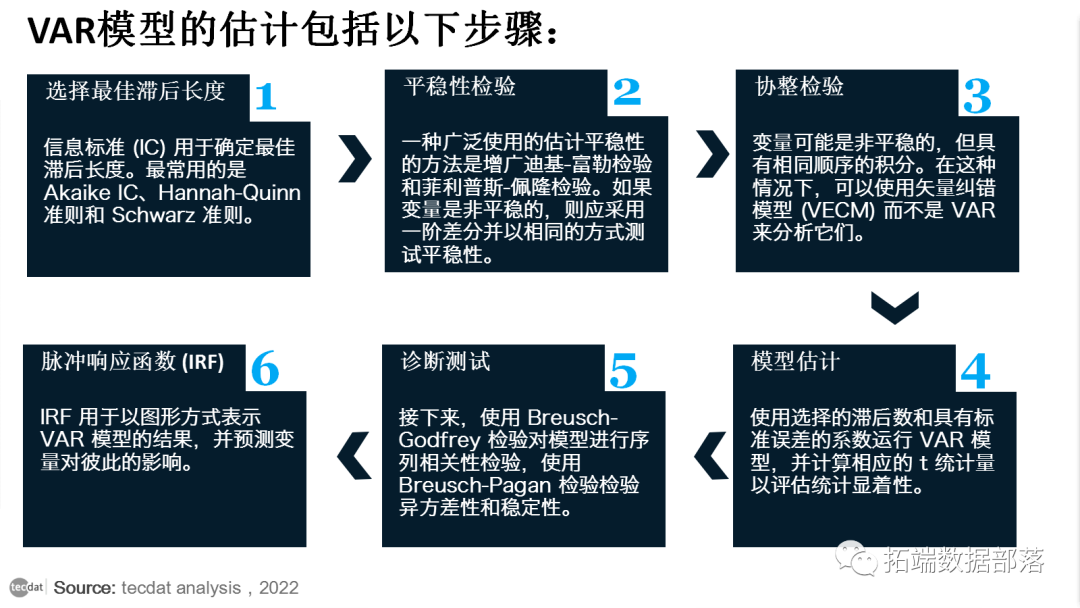
选择最佳滞后长度
信息标准 (IC) 用于确定最佳滞后长度。最常用的是 Akaike IC、Hannah-Quinn 准则和 Schwarz 准则。
平稳性检验
下一步是估计变量的平稳性。一种广泛使用的估计平稳性的方法是增广迪基-富勒检验和菲利普斯-佩隆检验。如果变量是非平稳的,则应采用一阶差分并以相同的方式测试平稳性。
协整检验
变量可能是非平稳的,但具有相同阶数的积分。在这种情况下,可以使用矢量纠错模型 (VECM) 而不是 向量自回归 来分析它们。如果变量是协整的,则在以下分析中应用 VECM 而不是 向量自回归 模型。VECM 应用于非变换的非平稳序列,而 向量自回归 使用变换的或平稳的输入。
模型估计
使用选择的滞后数和具有标准误差的系数运行 向量自回归 模型,并计算相应的 t 统计量以评估统计显着性。
诊断测试
接下来,使用 Breusch-Godfrey 检验对模型进行序列相关性检验,使用 Breusch-Pagan 检验检验异方差性和稳定性。
脉冲响应函数 (IRF)
IRF 用于以图形方式表示 向量自回归 模型的结果,并预测变量对彼此的影响。
格兰杰因果检验
这些变量可能是相关的,但它们之间可能不存在因果关系,或者影响可能是双向的。Granger 检验表明变量之间的因果关系,并根据 向量自回归 系统中一对变量的当前值和过去值的交互作用显示因果关系的方向。
向量自回归 在以下几种情况下很有用
向量自回归 面临的一个批评是它们是非理论的。也就是说,它们不是建立在某些将理论结构强加于方程的经济理论之上。假设每个变量都会影响系统中的所有其他变量,这使得对估计系数的直接解释变得困难。尽管如此,向量自回归 在以下几种情况下很有用:

1. 在不需要明确解释的情况下预测相关变量的集合;
2. 测试一个变量是否对预测另一个变量有用(格兰杰因果检验的基础);
3. 脉冲响应分析,分析一个变量对另一个变量突然但暂时变化的响应;
4. 预测误差方差分解,其中每个变量的预测方差比例归因于其他变量的影响。
R语言用向量自回归(VAR)进行经济数据脉冲响应研究分析
自从Sims(1980)发表开创性的论文以来,向量自回归模型已经成为宏观经济研究中的关键工具。这篇文章介绍了VAR分析的基本概念,并指导了简单模型的估算过程。
单变量自回归
VAR代表_向量自回归_。为了理解这意味着什么,让我们首先来看一个简单的单变量(即仅一个因变量或内生变量)自回归(AR)模型,其形式为yt=a1yt−1+et。
平稳性
在估算此类模型之前,应始终检查所分析的时间序列是否稳定,即它们的均值和方差随时间变化是恒定的,并且不显示任何趋势行为。
有一系列统计检验,例如Dickey-Fuller,KPSS或Phillips-Perron检验,以检验序列是否稳定。另一种非常常见的做法是绘制序列并检查其是否围绕恒定的平均值(即水平线)移动。如果是这种情况,它很可能是稳定的。
自回归滞后模型
像AR(p)模型一样,仅凭其自身的滞后对宏观经济变量进行回归可能是一种限制性很大的方法。通常,更合适的假设是还有其他因素。通过包含因变量的滞后值以及其他(即,外生)变量的同期和滞后值的模型来实现这种想法。同样,这些外生变量应该是稳定的。对于内生变量yt和外生变量xt例如_自回归分布滞后_或ADL,模型可以写成
yt=a1yt−1+b0xt+b1xt−1+et.
这种ADL模型的预测性能可能会比简单的AR模型更好。但是,如果外生变量也依赖于内生变量的滞后值怎么办?这意味着xt也是内生的,还有进一步的空间可以改善我们的预测。
向量自回归模型
因此,如上所述,VAR模型可以重写为一系列单独的ADL模型。实际上,可以通过分别估计每个方程来估计VAR模型。
标准VAR模型的协方差矩阵是_对称的_,即,对角线右上角的元素(“上三角”)将对角线左下角的元素(“下三角”)镜像。这反映了这样一种想法,即内生变量之间的关系仅反映相关性,并且不允许做出因果关系的陈述,因为在每个方向上的影响都是相同的。
在所谓的_结构化_ VAR(SVAR)模型的背景下分析了同时因果关系,或更确切地说,是变量之间的结构关系,该模型对协方差矩阵施加了限制 。
在本文中,我考虑VAR(2)过程。
此示例的人工样本是在R中生成的
-
set.seed(123) # 由于可复制性的考虑,重置随机数发生器
-
-
# 生成样本
-
t <- 200 # 时间序列观察数
-
k <- 2 # 内生变量数
-
p <- 2 # 滞后阶数
-
-
# 生成系数矩阵
-
A.1 <- matrix(c(-.3, .6, -.4, .5), k) # 滞后系数矩阵1
-
A.2 <- matrix(c(-.1, -.2, .1, .05), k) # 滞后系数2
-
A <- cbind(A.1, A.2) # 系数矩阵
-
-
# 生成序列
-
-
series <- matrix(0, k, t + 2*p) # 带有0的原始序列
-
for (i in (p + 1):(t + 2*p)){ # 生成e ~ N(0,0.5)的序列
-
series[, i] <- A.1%*%series[, i-1] + A.2%*%series[, i-2] + rnorm(k, 0, .5)
-
}
-
-
series <- ts(t(series[, -(1:p)])) # 转换为时间序列格式
-
names <- c("V1", "V2") # 重命名变量
-
-
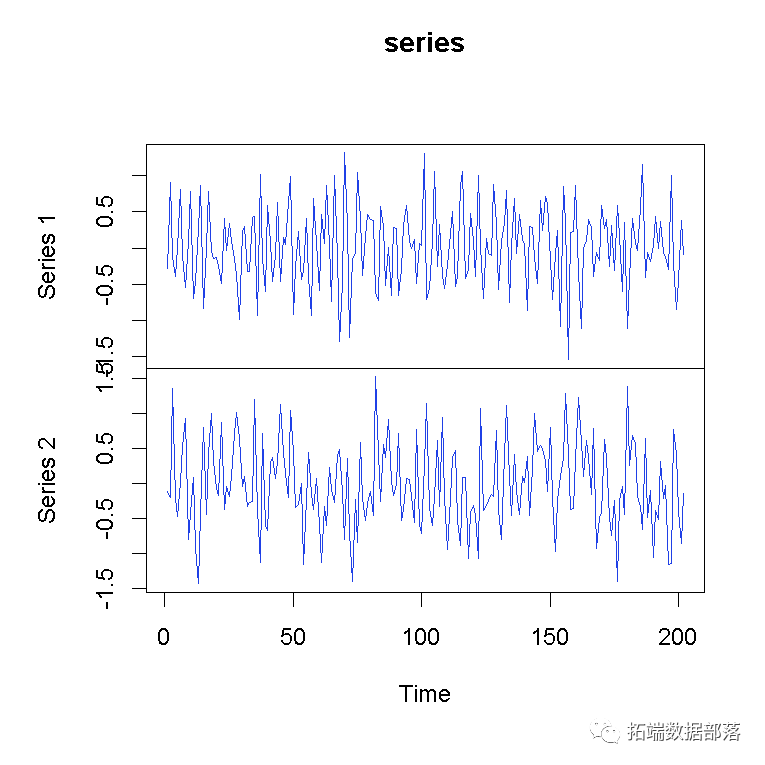
plot.ts(series) # 绘制序列
估算值
简单VAR模型的参数和协方差矩阵的估计很简单。
为了估计VAR模型,加载并指定数据(y)和 模型。
比较
VAR分析中的一个中心问题是找到滞后的阶数,以产生最佳结果。模型比较通常基于信息标准,例如AIC,BIC或HQ。通常,由于是小样本预测,AIC优于其他标准。但是,BIC和HQ在大型样本中效果很好 。
可以计算标准信息标准以找到最佳模型。在此示例中,我们使用AIC:
通过查看,summary我们可以看到AIC建议使用2的阶数。
summary(var.aic)-
## VAR Estimation Results:
-
## =========================
-
## Endogenous variables: Series.1, Series.2
-
## Deterministic variables: none
-
## Sample size: 200
-
## Log Likelihood: -266.065
-
## Roots of the characteristic polynomial:
-
## 0.6611 0.6611 0.4473 0.03778
-
## Call:
-
## VAR(y = series, type = "none", lag.max = 5, ic = "AIC")
-
##
-
##
-
## Estimation results for equation Series.1:
-
## =========================================
-
## Series.1 = Series.1.l1 + Series.2.l1 + Series.1.l2 + Series.2.l2
-
##
-
## Estimate Std. Error t value Pr(>|t|)
-
## Series.1.l1 -0.19750 0.06894 -2.865 0.00463 **
-
## Series.2.l1 -0.32015 0.06601 -4.850 2.51e-06 ***
-
## Series.1.l2 -0.23210 0.07586 -3.060 0.00252 **
-
## Series.2.l2 0.04687 0.06478 0.724 0.47018
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
##
-
##
-
## Residual standard error: 0.4638 on 196 degrees of freedom
-
## Multiple R-Squared: 0.2791, Adjusted R-squared: 0.2644
-
## F-statistic: 18.97 on 4 and 196 DF, p-value: 3.351e-13
-
##
-
##
-
## Estimation results for equation Series.2:
-
## =========================================
-
## Series.2 = Series.1.l1 + Series.2.l1 + Series.1.l2 + Series.2.l2
-
##
-
## Estimate Std. Error t value Pr(>|t|)
-
## Series.1.l1 0.67381 0.07314 9.213 < 2e-16 ***
-
## Series.2.l1 0.34136 0.07004 4.874 2.25e-06 ***
-
## Series.1.l2 -0.18430 0.08048 -2.290 0.0231 *
-
## Series.2.l2 0.06903 0.06873 1.004 0.3164
-
## ---
-
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
-
##
-
##
-
## Residual standard error: 0.4921 on 196 degrees of freedom
-
## Multiple R-Squared: 0.3574, Adjusted R-squared: 0.3443
-
## F-statistic: 27.26 on 4 and 196 DF, p-value: < 2.2e-16
-
##
-
##
-
##
-
## Covariance matrix of residuals:
-
## Series.1 Series.2
-
## Series.1 0.21417 -0.03116
-
## Series.2 -0.03116 0.24154
-
##
-
## Correlation matrix of residuals:
-
## Series.1 Series.2
-
## Series.1 1.000 -0.137
-
## Series.2 -0.137 1.000`
-
-
仔细观察结果,我们可以将真实值 与模型的参数估计值进行比较:
真实值
-
A
-
## [,1] [,2] [,3] [,4]
-
## [1,] -0.3 -0.4 -0.1 0.10
-
## [2,] 0.6 0.5 -0.2 0.05
-
# Extract coefficients, standard errors etc. from the object
-
# produced by the VAR function
-
est_coefs <- coef(var.aic)
-
-
# 仅提取两个因变量的系数,并将它们组合为一个矩阵
-
-
# 输出四舍五入的估计值
-
round(est_coefs, 2)
-
## Series.1.l1 Series.2.l1 Series.1.l2 Series.2.l2
-
## [1,] -0.20 -0.32 -0.23 0.05
-
## [2,] 0.67 0.34 -0.18 0.07
所有估计值都有正确的符号,并且相对接近其真实值。
脉冲响应
一旦我们确定了最终的VAR模型,就必须解释其估计的参数值。由于VAR模型中的所有变量都相互依赖,因此单个参数值仅提供 有限信息。为了更好地了解模型的动态行为,使用了脉冲响应(IR)。可以绘制因变量的轨迹,产生在许多宏观论文中都可以找到的那些波浪曲线。
在下面的示例中,我们想知道受到冲击后序列2的行为。指定了我们想要脉冲响应的模型和变量后,我们将时间范围设置n.ahead为20。该图给出了序列2的响应。
-
# 计算脉冲响应
-
-
# 绘制脉冲响应
-
plot(ir.1)
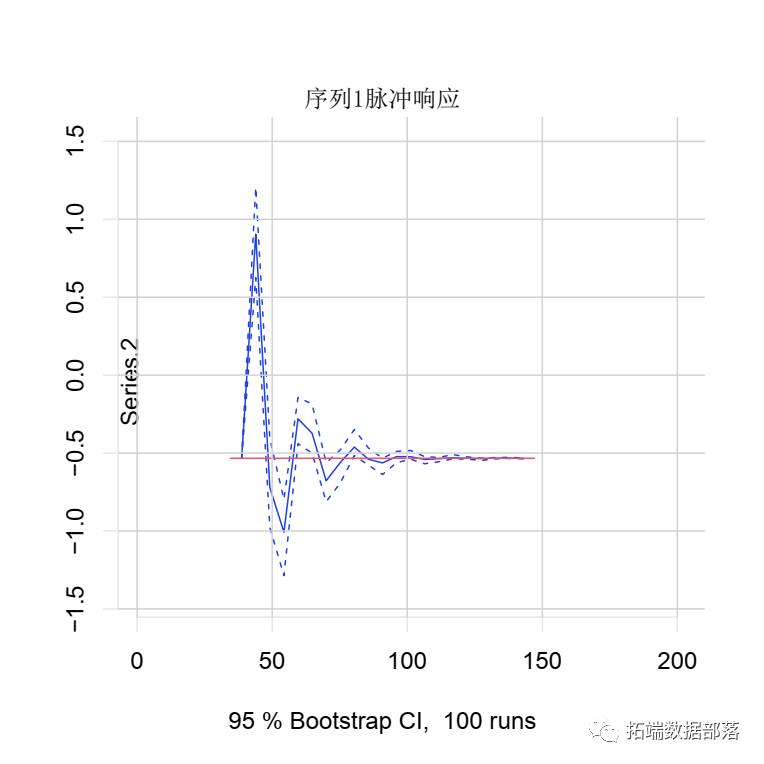
请注意,_正交_选项很重要,因为它说明了变量之间的关系。在我们的示例中,我们已经知道不存在这样的关系,因为真正的方差-协方差矩阵(或简称协方差矩阵)在非对角元素中是对角为零的对角线。但是,由于具有200个观测值的有限时间序列数据限制了参数估计的精度,因此协方差矩阵的非对角元素具有正值,这意味着 非零同时效应。为了在IR中排除这种情况,我们设置了ortho = FALSE。结果是,脉冲响应在周期0中从零开始。也可以尝试另一种方法并进行设置ortho = TRUE,那么绘图从零开始。
要了解这一点,还可以计算并绘制_累积_脉冲响应函数,以了解 总体长期影响:
-
# 计算脉冲响应
-
-
# 绘图
-
plot(ir.2)
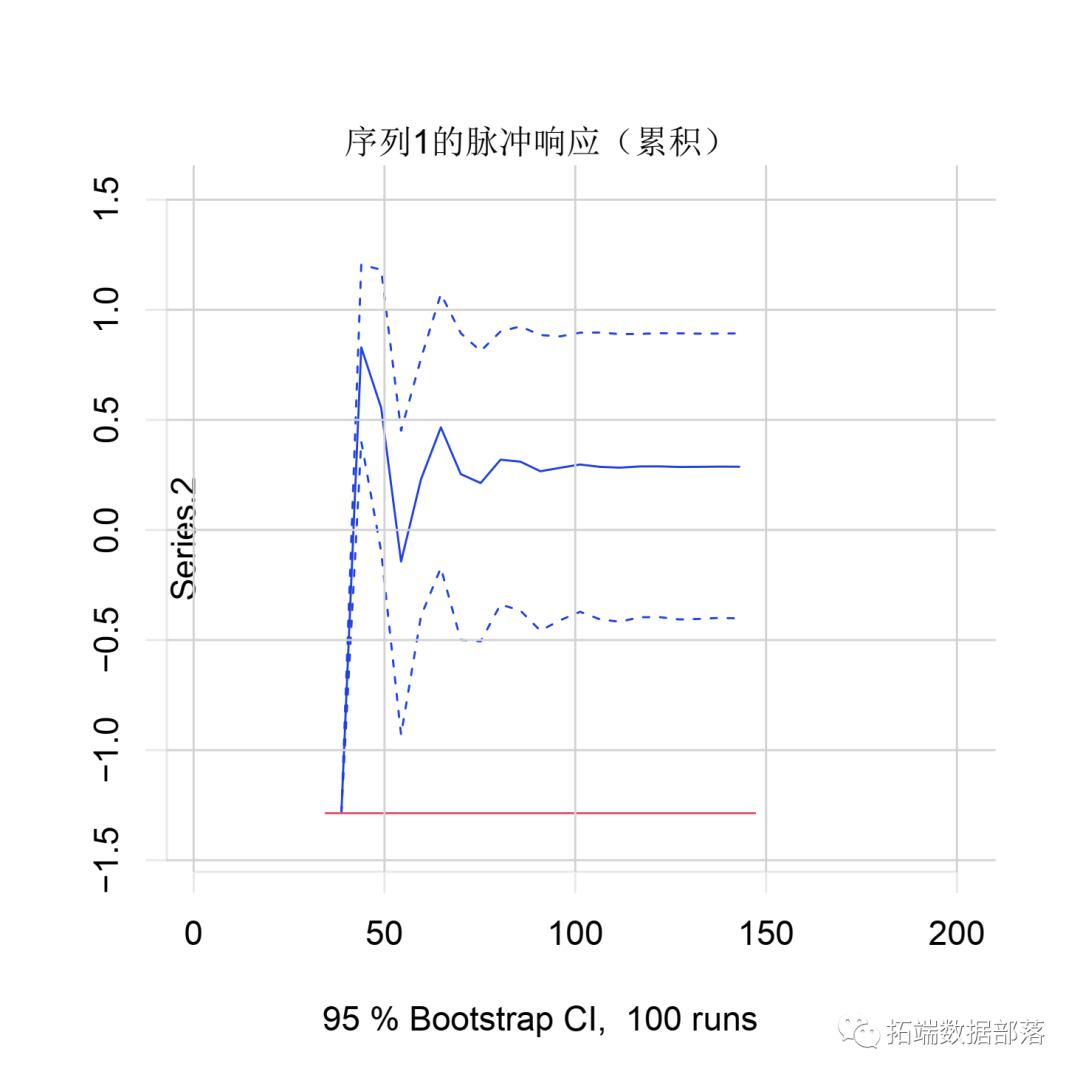
我们看到,尽管序列2对序列1中的 反应在某些时期是负面的,但总体效果却是显着正面。
点击标题查阅往期内容
向量自回归VAR的迭代多元预测估计 GDP 增长率时间序列|数据分享
ARIMA、GARCH 和 VAR模型估计、预测ts 和 xts格式时间序列
向量自回归(VAR)模型分析消费者价格指数 (CPI) 和失业率时间序列
Matlab创建向量自回归(VAR)模型分析消费者价格指数 (CPI) 和失业率时间序列
Stata广义矩量法GMM面板向量自回归 VAR模型选择、估计、Granger因果检验分析投资、收入和消费数据
R语言时变向量自回归(TV-VAR)模型分析时间序列和可视化
R语言arima,向量自回归(VAR),周期自回归(PAR)模型分析温度时间序列
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
R语言用LASSO,adaptive LASSO预测通货膨胀时间序列
Python中的ARIMA模型、SARIMA模型和SARIMAX模型对时间序列预测