原文链接:http://tecdat.cn/?p=25569
原文出处:拓端数据部落公众号
在投资组合管理、风险管理和衍生品定价中,波动性起着重要作用。事实上如此重要,以至于您可以找到比您可以处理的更多的波动率模型。接下来是检查每个模型在样本内外的表现如何。以下是您可以做的三件事:
1. 基于回归的检验——Mincer Zarnowitz 回归
这个想法很简单,回归预测的实际(实现)值:
![]()
现在我们共同检验假设:
![]()
截距为零意味着你的预测是无偏的。矛盾的是,如果截距是0.02,这意味着为了使两边相等,我们在预测中平均增加0.02,所以它一直在低估观察值。斜率应该是1,也就是说,你的预测完全 "解释 "了观察值。
2. 配对比较——Diebold Mariano 检验。
假设您有两个模型,它们产生两组预测。因此,您有两组误差。调用这些误差
![]()
在两种方法相同的情况下,这两个向量的差 ![]() 平均为零(或这些向量的函数,例如 e1^2 – e2^2)。在仅使用相同方法复制预测的极端情况下,差正好为零。更重要的是,我们知道这种差是如何分布的(渐近地..),因此我们可以测试它是否确实偏离零。
平均为零(或这些向量的函数,例如 e1^2 – e2^2)。在仅使用相同方法复制预测的极端情况下,差正好为零。更重要的是,我们知道这种差是如何分布的(渐近地..),因此我们可以测试它是否确实偏离零。
难以理解这一点。如果不知道 2 的结果的可能性有多大,就不可能测量 0 和 2 之间的距离。在 {-3,3} 之间均匀分布的 2 的结果并不像具有标准正态分布的 2 的结果那样不可能。
产生明显更小的误差(通常是平方误差或绝对误差)的方法是首选。您可以轻松地将其扩展到多个比较。
3. Jarque-Bera 检验
在这种情况下,我们有一个准确的波动率预测。我们可以将序列中心化并使用我们对标准差的预测对其进行标准化。准确地说:
![]()
应该有均值零和标准差一。新的标准化序列通常不会呈正态分布,但您可以使用此检验来衡量模型获取原始序列的偏度和峰度的程度。
实证研究中,前两个方案对一般的预测评估是有效的,然而,波动率是不可观察的,所以我们用什么作为观察值并不清楚。我们所做的是用一个替代物来代替 "观察到的",通常是收益率的平方。在这里你可以找到更准确的替代方法,但是,它们是基于日内信息的,所以你需要获得日内数据源。
我们看看在 R 中是如何工作的。
我从谷歌提取数据,采集5年的标准普尔指数收益序列,并估计标准 garch(1,1) 和另一个更准确的 GJR-garch(不对称 garch)。
-
-
dat0= as.matrix(getSymbol
-
-
n = NROW
-
-
-
plot
-
-
-
gjrc <- ugarchspec
-
gjrmodel = fit
-
-
gjrfit = sigma
-
-
Nit = as.dsigma
-
-
resq = ret^2
-
-
Nsq = Nfit^2
-
-
Tsq = Tfit^2
-
-
plot
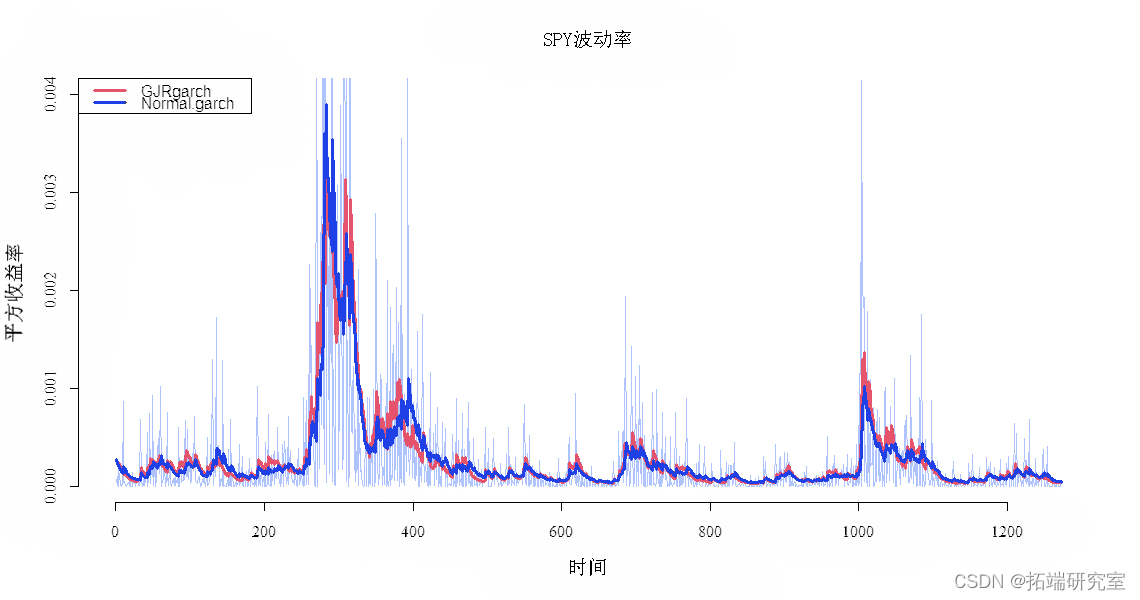
具有两种 Garch 模型的 SPY 波动率
-
#########################
-
-
# mincer-zarnowitz回归
-
#########################
-
-
-
-
Nmz = lm
-
Tmz = lm
-
-
-
-
linsis
-

lineesis

-
#########################
-
-
#DM检验
-
-
#########################
-
-
-
-
dmst

对于平方损失函数,两组预测之间没有区别
-
-
#########################
-
-
# Jarque Bera 检验
-
-
#########################
-
-
stanN = scale
-
-
stajr = scale
-
-
scret = scale# 没有波动率模型,只有无条件波动率
-
-
jbtest$stat
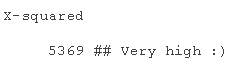
rjbtestat

rjteststat

最受欢迎的见解
1.R语言基于ARMA-GARCH-VaR模型拟合和预测实证研究