原文链接:http://tecdat.cn/?p=24761
原文出处:拓端数据部落公众号
本文档通过一些探索性数据分析来制定河流的评级曲线和流量预测。目的是利用 (1) 在底部安装单元的定期部署期间测量的瞬时流量和 (2) 来自长期部署在河流中的水位数据记录器的瞬时深度测量,以创建和更新评级曲线。额定曲线将用于计算 HOBO 压力传感器部署期间(大约 1 年)的流量。所得数据将用于创建和验证河流 10-15 年期间的回归和 DAR 流量估计。
介绍
评级曲线
由于与河流流量连续测量相关的高成本,最好使用河流高度测量来估计流量。使用压力传感器可以连续测量水流高度。当辅以周期性的流量测量时,幂函数可以关联河流高度和流量(Venetis):
![]()
其中:Q代表稳态排放,H代表流高(阶段),H0是零排放阶段;K 和 z 是评级曲线常数。按照惯例,Q 和 H 通常在参数估计之前进行对数变换。
当河流水位过程线的上升和下降阶段导致相同河流高度的不同流量时,就会发生不稳定流。由此产生的受滞后影响的评级曲线将呈现为一个循环而不是一条线。Petersen-Øverleir 描述的修正琼斯公式和 Zakwan 可能用过了:
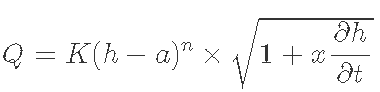
其中 Q 是流量,h 是河流高度。偏一阶导数 ![]() 使用有限差分近似为 J:
使用有限差分近似为 J:
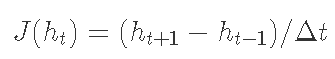
其中 ht 是时间 t 的水流高度,Δt 是时间区间。这可以被认为是河流高度和时间之间函数的斜率或瞬时变化率,它是使用测量的河流高度值估计的。K、a、n 和 x 是评级曲线常数。
许多不同的方法可用于求解额定曲线参数。我们使用非线性最小二乘回归来最小化评级曲线参数的残差平方和 (SSE)。残差 SSE 计算如下:
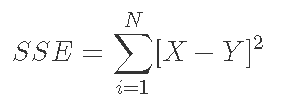
其中:X 是测量值,Y 是预测值。非线性优化方法搜索参数组合以最小化目标函数(在这种情况下为残差 SSE)。彼得森 应用 Nelder-Mead 算法求解琼斯公式。扎关 使用广义减少梯度和遗传算法提出非线性优化方法。大多数方法需要仔细规划有点接近全局最小值的参数起始值,或者存在识别替代局部最小值的风险。为了减少局部最小值收敛的可能性, R 提供了在许多不同的起始值上迭代非线性最小二乘优化的功能(Padfield 和 Matheson).
未控制的流量估计
评级曲线允许在部署水流深度数据记录器的时间段内开发每日水流记录。然而,当站点未启用时,对每日流量的估计需要额外的信息。统计信息传递和经验回归是两种相对简单的方法,可用于估算测量不当的流域中的流量。统计传输程序使用面积和径流之间的假设关系,简单地将流量持续时间曲线或每日流量值从有测量的流域传输到未测量的流域。最常用的统计传递方法是流域面积比。使用流域面积比,通过将面积比与日流量相乘,日流量从一个流域转移到另一个流域:
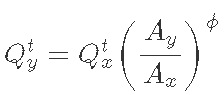
其中, ![]() 是未测量盆地 y 和时间 t 的流量,
是未测量盆地 y 和时间 t 的流量, ![]() 是测量盆地 x 和时间 tt 处的流量,和
是测量盆地 x 和时间 tt 处的流量,和 ![]() 是盆地的面积比。参数 ϕ 通常等于 1(Asquith、Roussel 和 Vrabel )。然而,阿斯奎斯、鲁塞尔和弗拉贝尔 提供了在德克萨斯州应用时用于流域面积比的 ϕ 的经验估计值。有了可用的短期流量记录,可以使用排水面积比方法评估各种流量仪表的性能。此外,可以使用非线性最小二乘法开发 ϕ 的局部值。如果主要输出是流量持续时间曲线,则主要关注的是候选量具有相似的径流因变量并且在未治理流域的合理距离内。但是,如果主要输出包括每日流量估计,则具有具有相同流量超出概率时间的候选量具更为重要。
是盆地的面积比。参数 ϕ 通常等于 1(Asquith、Roussel 和 Vrabel )。然而,阿斯奎斯、鲁塞尔和弗拉贝尔 提供了在德克萨斯州应用时用于流域面积比的 ϕ 的经验估计值。有了可用的短期流量记录,可以使用排水面积比方法评估各种流量仪表的性能。此外,可以使用非线性最小二乘法开发 ϕ 的局部值。如果主要输出是流量持续时间曲线,则主要关注的是候选量具有相似的径流因变量并且在未治理流域的合理距离内。但是,如果主要输出包括每日流量估计,则具有具有相同流量超出概率时间的候选量具更为重要。
基于经验回归的方法需要一段时间的测量流量和一些预测变量来估计径流因变量。通常,使用日降雨量数据将回归模型拟合到测量的流量数据:
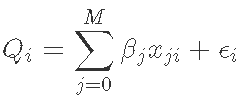
其中 Qi是第 i 天的预测排放量,β 是第 j 个变量的系数,x 是第 i 天的预测变量值。假设误差项 ϵi 正态分布在均值零附近。使用简单线性或多元线性回归 Q通常在估计回归系数之前进行对数变换。如果预测变量和因变量之间的关系预期为非线性多项式,则可以包括项。然而,称为广义加性模型的线性回归的扩展允许将这些非线性项相对容易地拟合到数据中。对于广义加性模型,因变量取决于应用于每个预测变量的平滑函数的总和。此外,广义加性模型可以拟合具有非正态分布的误差分布的因变量。然而,与线性或多元线性回归相比,广义加性模型由于缺乏单一模型系数而更难以解释。因此,每个单独的平滑函数对因变量均值的影响通常以图形方式传达。
方法
数据采集
数据来源于水位数据记录器。部署了一个额外的数据记录器,为部署在水下的数据记录器提供环境大气压力校正。从 2020-03-02 到 2021-..-...,水位数据记录器几乎连续部署,并设置为每隔 15 分钟记录一次水位。
-
-
## 制作要导入的文件列表
-
-
list.files(path = here("Data
-
-
##创建一个空白的tibble来填充
-
tibble()
-
-
-
## 遍历文件路径以读取每个文件
-
for (i in fihs) {
-
x <- read_csv(
-
-
copes
-
bind_rows(hf, x)
-
rm(x)
-
-
-
-
表 1:在每个站点测量的 15 分钟流级别的汇总统计数据

-
ggplot(hdf) +
-
geom_line+
-
facet_wrap +
-
scale_x_datetim+
-
scale_y +
-
guid +
-
th +
-
theme

图 1:每个站点的 15 分钟区间流深度记录。
使用底部安装的流量计在每个 SWQM 站点进行定期流量测量。测量横截面积、水流高度和速度。使用这些测量值,该设备利用指数速度方法来报告瞬时流量。流量测量设备一次部署几天,在每个站的不同流量条件下捕获完整的水文过程线。只有两个流量计可用,因此在站点之间轮流部署。此外,一台设备停止工作并进行了几个月的维修。以 15 分钟的间隔记录流量。
在数据探索过程中,每个站点的低流量数据中明显存在过多噪声。在停滞或接近停滞条件期间,多普勒流量计记录高度可变的流速并报告不切实际的流量。由于过多的数据噪声,从数据记录中清除了极低或停滞的流量时期。未来的部署将需要考虑在什么条件下长期部署是合适的。对于像这样的小流,定期的风暴流部署可能是最合适的部署。
-
-
## 制作要导入的文件列表
-
file_paths <- paste0(he ".csv"))
-
-
##创建一个空白的tibble来填充
-
iq <- tibble()
-
-
## 遍历文件路径以读取每个文件
-
for (i in file_paths) {
-
x <- read_csv
-
file <- i
-
idf <- bind_rows
-
rm
-
}
-
-
-
iqdf <- iqdf %>%
-
## 使用 `dplyr::` 指定要使用的重命名函数,以防万一
-
dplyr::rename(Sam)
-
-
-
-
ggplot(iqdf)+
-
geom_point(aes(Dme, Flow), alpha = 0.2) +
-
facet_wrap
-

图 2:每个站点记录数据的周期。
-
-
## 为了将测量深度与IQ的流速测量结合起来
-
## ##我们需要插值测量深度到每分钟,因为深度是偏移。然后我们就可以连接这些数据。我们将使用线性插值。
-
-
-
-
##使用purrr::map在每个站点上运行插值运算
-
hdf %>%
-
split%>%
-
map %>%
-
bind_row %>%
-
as_tibble
-
##这就是我们要开发评级曲线的数据框架。
-
idf %>%
-
left_join %>%
-
select %>%
-
mutate -> iqdf
-
评级曲线发展
由于植物生长、植物枯死、沉积、侵蚀和其他过程,河内和河岸的条件全年都会发生变化。这些不断变化的条件可能需要开发多个评级曲线。探索性数据分析用于确定变化时期和滞后影响评级曲线的可能性。一旦确定了评级曲线周期和适当的公式,公式中的评级曲线参数 (1) 和 (2) 通过非线性最小二乘估计回归使用 R (Padfield )。该方法利用 Levenberg-Marquardt 算法和多个起始值来寻找全局最小 SSE 值。
单独的评级曲线用于使用测量的河流高度估计河流流量。Nash-Sutcliffe 效率 (NSE) 和归一化均方根误差用于评估测量和估计流量之间的拟合优度。NSE 是归一化统计量,用于评估相对于测量数据方差的相对残差方差,计算公式如下:
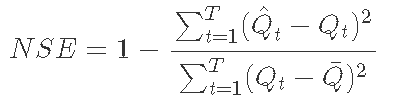
其中 ![]() 是观察到的排放量的平均值,
是观察到的排放量的平均值, ![]() 是 t时刻的估计流量,Qt 是 t时刻观察到的流量。NSE 的值范围从 −∞ 到 1,其中 1 表示完美的预测性能。NSE 为零表示模型具有与数据集均值相同的预测性能。
是 t时刻的估计流量,Qt 是 t时刻观察到的流量。NSE 的值范围从 −∞ 到 1,其中 1 表示完美的预测性能。NSE 为零表示模型具有与数据集均值相同的预测性能。
nRMSE 是一个基于百分比的指标,用于描述预测和测量的排放值之间的差异:
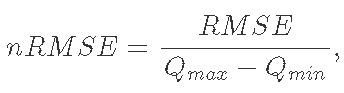
其中
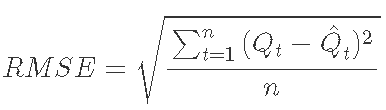
其中 Qt 是在时间 t 观察到的流量, ![]() 是 t 时刻的估计排放量,n是样本数,
是 t 时刻的估计排放量,n是样本数, ![]() 和
和 ![]() 是观察到的最大和最小排放量。产生的 nRMSE 计算是一个百分比值。
是观察到的最大和最小排放量。产生的 nRMSE 计算是一个百分比值。
结果
站点
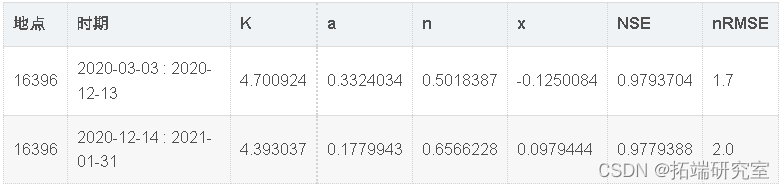
基于探索性分析,为站点制定了两条评级曲线。评级曲线周期为2020-03-03至2020-11-30和2020-12-01至2021-01-31。由于观察到的水层中存在明显的不稳定流动,我们应用了琼斯公式(公式(2))。两个时间段都产生了 NSE 大于 0.97 和 nRMSE 小于 3% 的评级曲线,表明非常适合(表 2; 数字 3)。数字 3 确实表明在极低流量测量中存在一些有偏差的流量估计。这归因于多普勒流量计在低流量时记录的流量变化。
-
-
## 为站点 制作数据框
-
-
if %>%
-
group_split %>%
-
## 删除最大流量未超过 10 cfs 的事件
-
imap %>%
-
bind_rows
-
## 为站点 2020 年 12 月 14 日至 2021 年 1 月制作数据框
-
idf %>%
-
diff_time %>%
-
group_split %>%
-
imap(~mutate) %>%
-
bind_rows %>%
-
-
##使用nls估计琼斯公式中的参数
-
-
## 一些起始参数。 nls_multstart 将使用多个
-
##起始参数和模型选择查找
-
##全局最小值
-
stlower
-
stupper
-
##适合nls
-
rc<- nls(jorm,
-
suors = "Y")
-
-
##设置参数起始限制
-
-
##nls
-
nls(jorm
-
suors = "Y")
-
-
-
## 使用参数结果设置数据框。 将使用它来报告参数和 GOF 指标
-
dfresu <- tibble(Site )
-
-
-
## 开发评级曲线预测和
-
## 使用 GOF 指标创建表
-
df %>%
-
dfres %>%
-
-
NSE(predicted, as.numeric(Flow))-> dfres
-
-
##显示表
-
kable(dfres)
-
表 2:站点 的评级曲线参数估计和拟合优度指标
-
-
##绘制评级曲线结果
-
-
p1 <- ggplot +
-
geom_pointlpha = 0.25) +
-
geom_abline +
-
scale_x_continuous
-
theme()
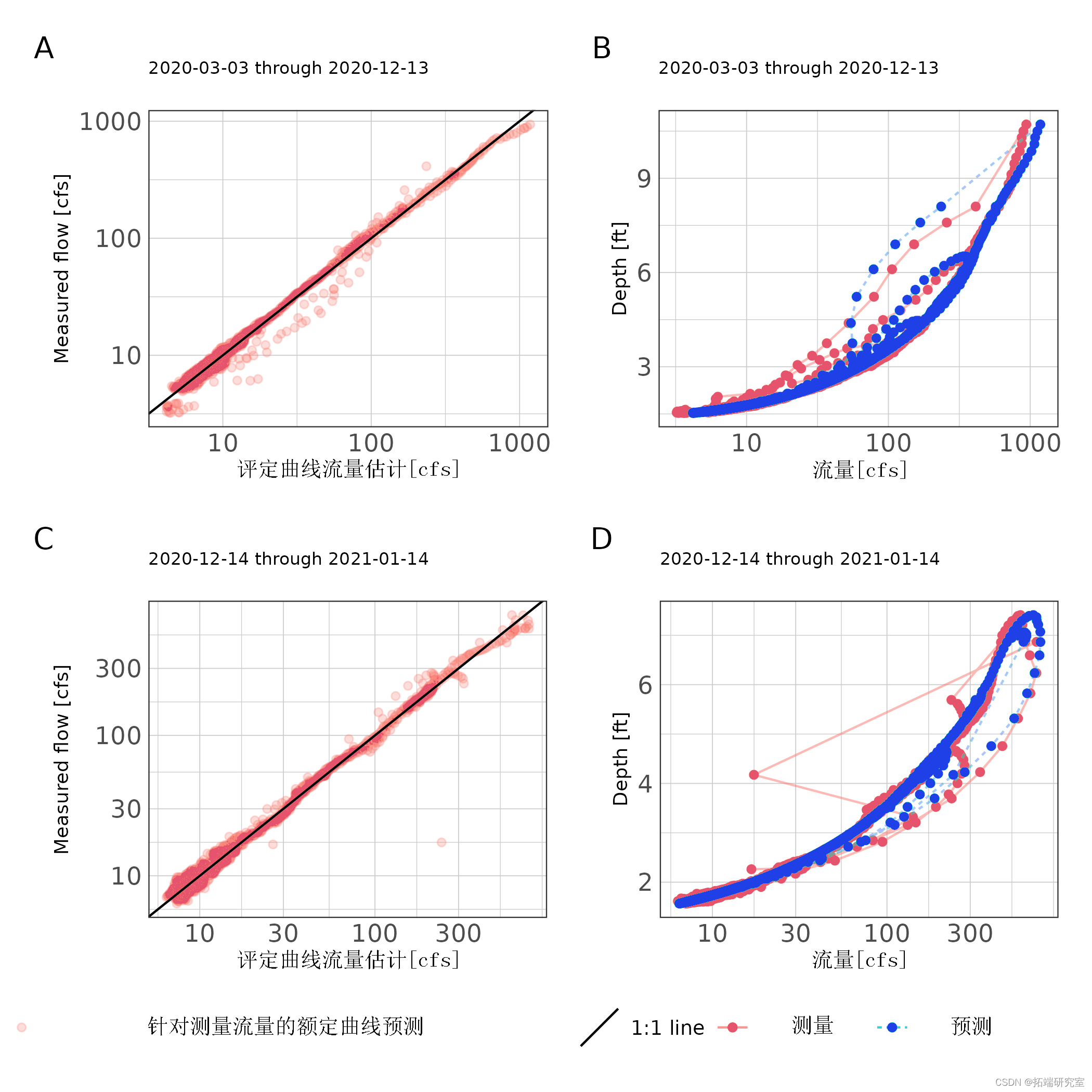
图 3:站点 处每个额定曲线周期的额定曲线估计流量与实测流量(A、C)和阶段流量预测(B、D)的散点图。
站点 16397
探索性分析表明,在该站点使用幂函数(公式 (1)) 因为在水文过程图中没有观察到不稳定的流动条件。评级曲线预测导致 NSE 大于 0.95,表明非常适合(表 2)。nRMSE 小于 5%,这对于在该站获得的较小样本量来说可能是一个很好的结果,并且可能受到观察到的低流量方差的影响(表 2; 图 3).
-
-
## 设置数据框以将评级曲线拟合到 1697
-
-
##幂函数
-
-
##参数起始限制
-
-
rc_7 <- nls(prm,
-
stalower
-
supors = "Y")
-
-
-
## 使用参数结果设置数据框。 稍后将使用它来报告参数和 GOF 指标
-
dfres <- tibble(Sit,
-
K,
-
H0 ,
-
Z["Z"]])
-
-
df167 %>%
-
mutate(pr = exp(predict(rc))) -> df
-
表 3:站点 167 的评级曲线参数估计和拟合优度指标

-
-
##绘制评级曲线结果
-
p1 <- df7 %>%
-
ggplot() +
-
geom_point +
-
geom_abline+
-
scale_x_continuous +
-
scale_y_continuous
-
p1 + p2 + plot_annotation
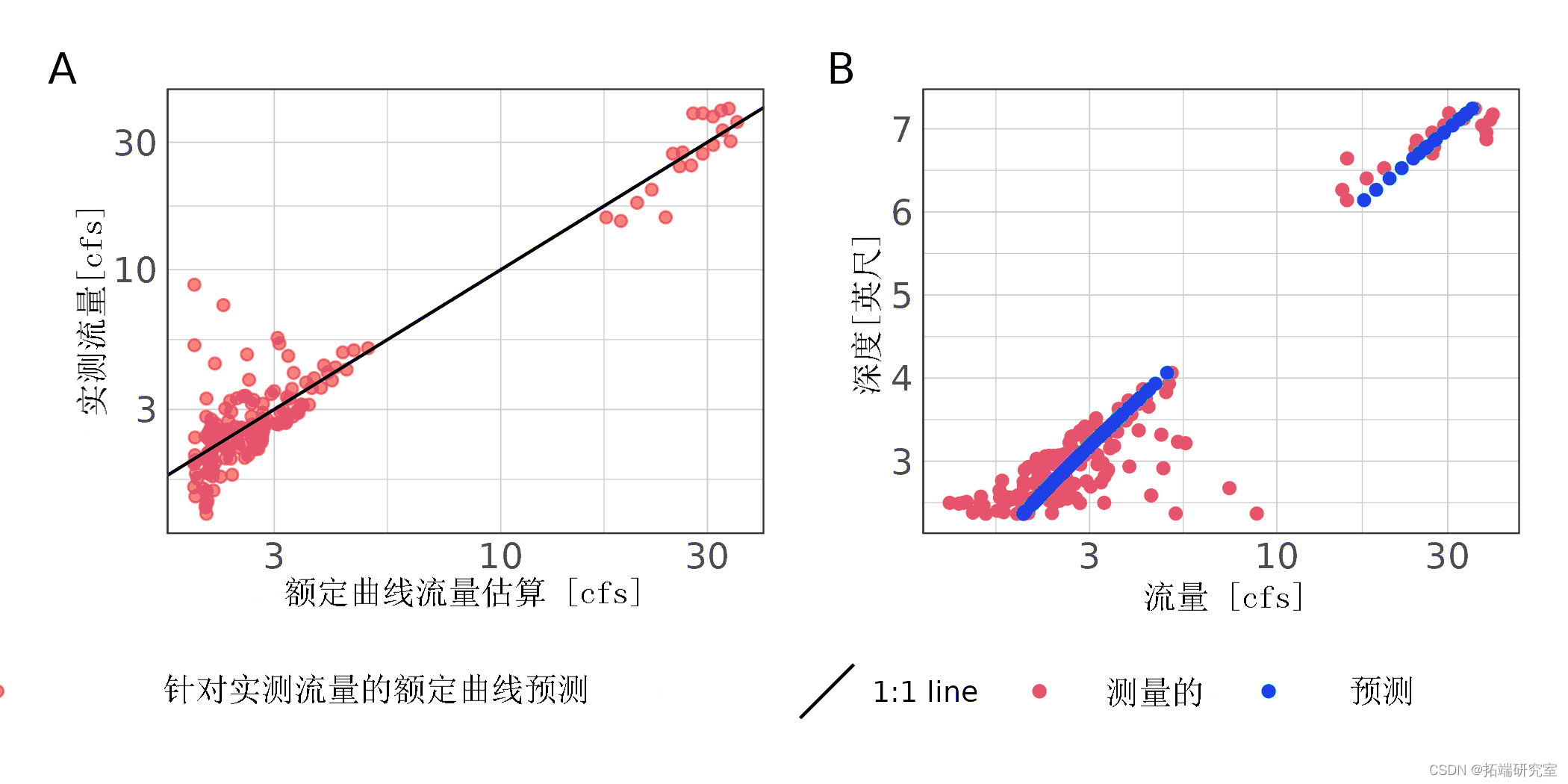
图 4:167 站的额定流量估计流量与实测流量 (A) 和阶段流量预测 (B) 的散点图。
站点 162
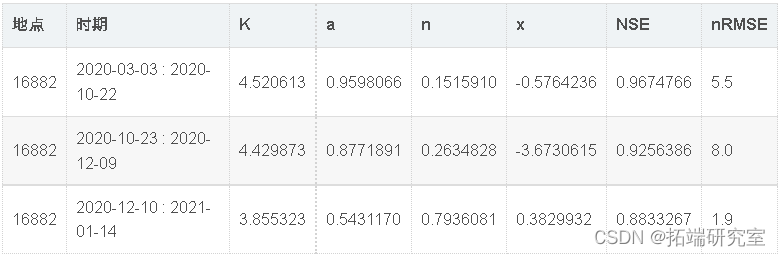
基于探索性分析,为站点166制定了3条评级曲线。评级曲线周期为2020-03-03至2020-05-30;2020-06-01 至 2020-10-31;和 2020-11-01 至 2021-01-31。由于观察到的水层中存在明显的不稳定流动,我们应用了琼斯公式(公式(2))。3 月至 9 月的结果表明评级曲线具有非常好的拟合(NSE > 0.96,nRMSE <6%;表 4)。低流量下观测值和预测值之间的巨大差异可归因于具有极快的水流高度变化(> 1.5 英尺/小时)的事件,参数估计难以拟合(图 5 )。其余评级曲线的拟合优度指标有所下降,但仍表明性能良好(表 4)。测得的中低流量值的高方差影响评级曲线性能(图 5).
-
-
## 制作 3 个不同的数据框以适应琼斯公式。
-
-
iqpdf %>%
-
filter(DaTime > as.POSIXct)
-
#filter %>%
-
group_split %>%
-
imap %>%
-
bind_rows
-
-
## 估计每个数据集的参数
-
-
##设置参数起始限制
-
stlower
-
stupper
-
-
rc<- nls(jonrm
-
surs = "Y")
-
-
##设置参数起始限制
-
stlower
-
stupper
-
rc <- nls(jorm,
-
stawer,
-
suprs = "Y")
-
-
##设置参数起始限制
-
stalower
-
-
-
-
## 使用参数结果设置数据框。稍后将使用它来报告参数和 GOF 指标
-
dfres <- tibble(Site
-
-
K ,
-
a ,
-
n ,
-
x )
-
-
## 开发评级曲线预测和
-
## 使用 GOF 指标创建表
-
-
-
##显示表
-
kable(df)
-
表 4:站点 16882 的评级曲线参数估计和拟合优度指标
-
-
##绘制评级曲线结果
-
-
p1 <- ggplot(df_03) +
-
geom_point +
-
geom_abline+
-
scale_x_continuous +
-
scale_y_continuous +
-
theme_ms()
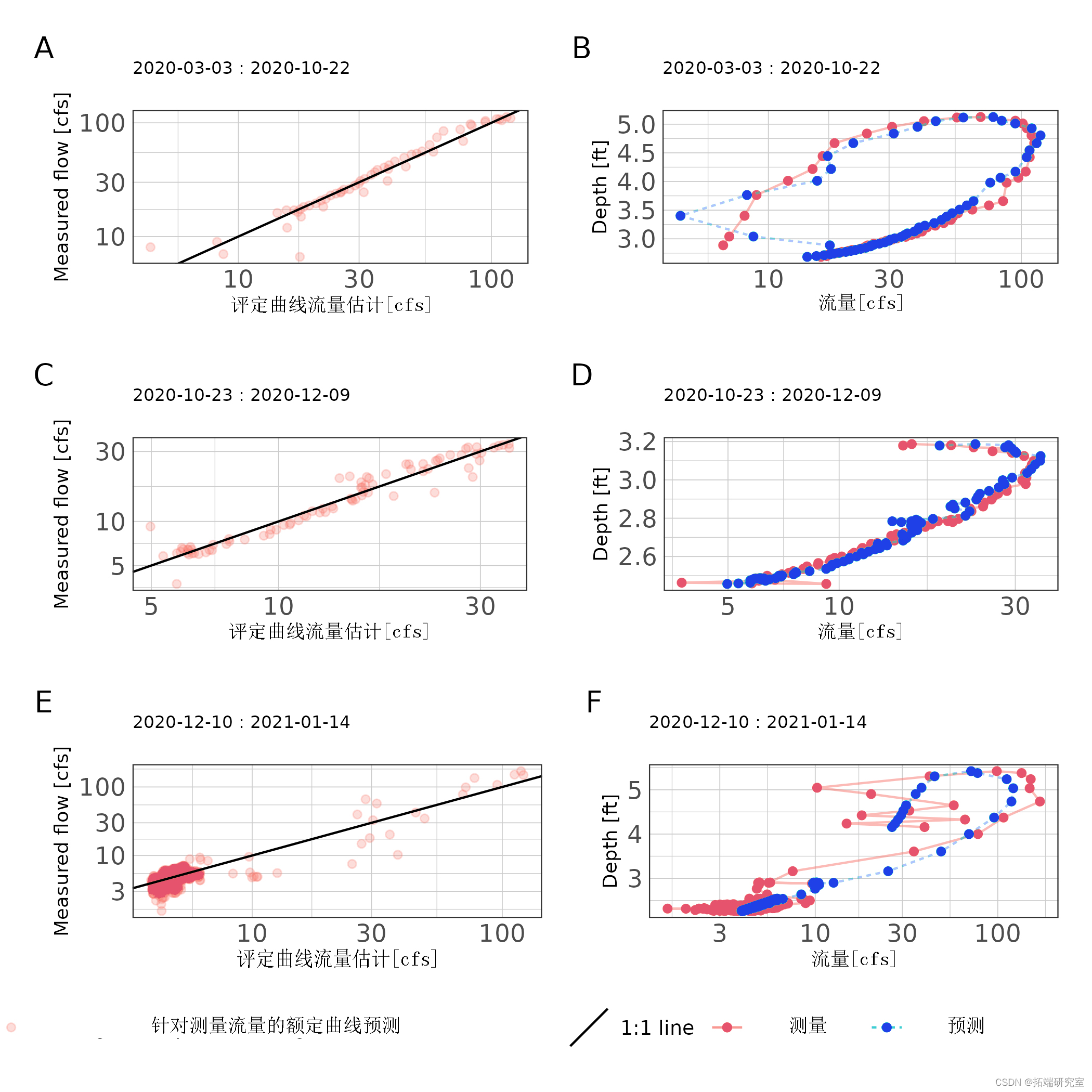
图 5:16882 站每个额定曲线周期的额定曲线估计流量与实测流量(A、C、E)和阶段流量预测(B、D、F)的散点图。
每日流量估算
-
-
# 使用原始数据集
-
# 按日期使用评级曲线估计流量
-
# 聚合表示每日流量,报告汇总统计数据。
-
-
hodf %>%
-
dplyr::select%>%
-
group_split(站点) %>%
-
bind_rows()
-
-
## 制作模型的数据框,预测数据,然后映射预测函数,并取消嵌套数据框。
-
tibble) %>%
-
~exp( newdata = .y))
-
)) %>%
-
tidyr::unnest%>%
-
as_tsibble
-
-
##绘制数据
-
-
ggplot() +
-
geom_line+
-
geom_point +
-
facet_wrap +
-
scale_y_continuous +
-
theme_ms()
-
-
-
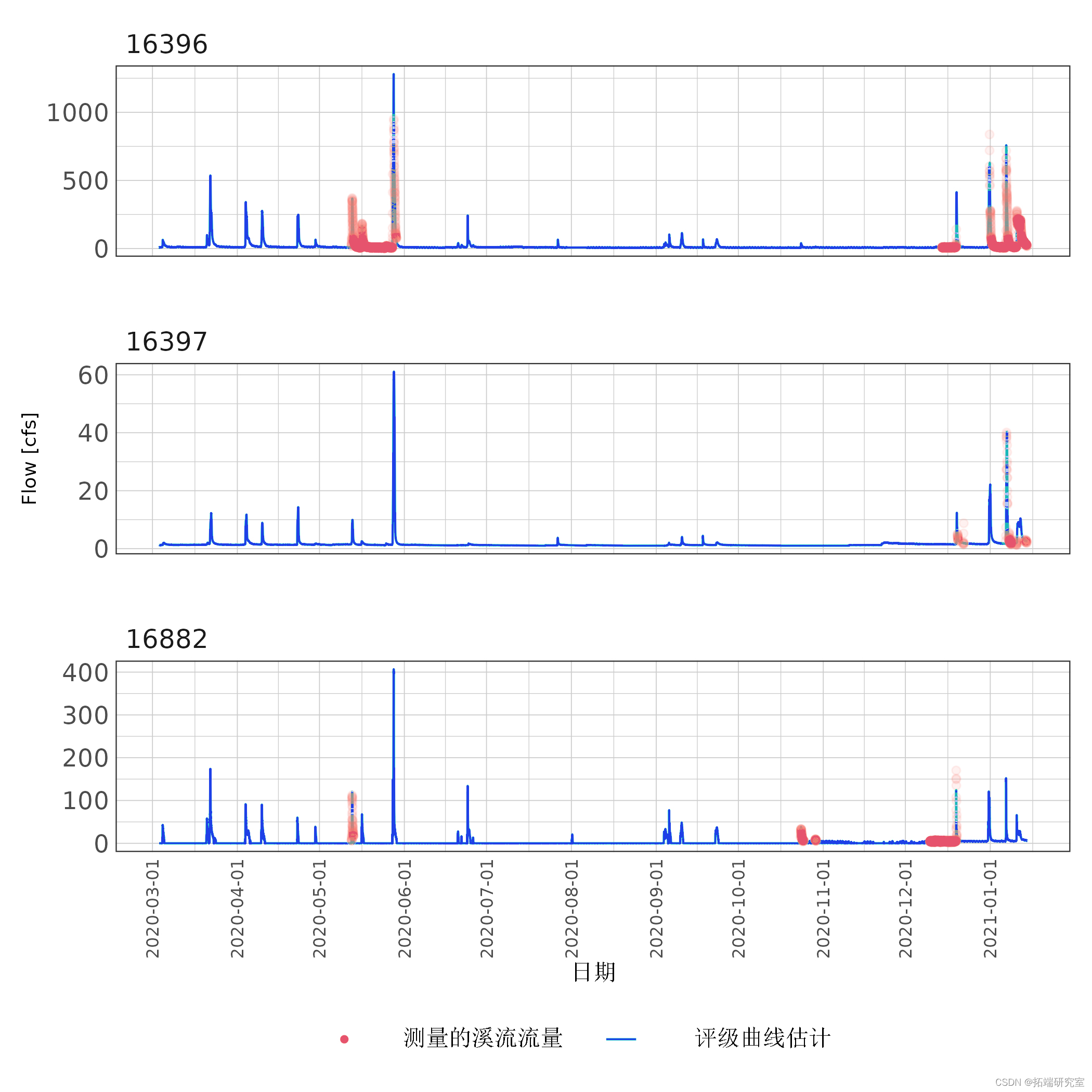
图 6:15 分钟流量估算与叠加测量流量值
-
-
## 计算平均每日流量并报告统计数据
-
-
dplyr::select(Site, DTime) %>%
-
group_by_key() %>%
-
index_by(date = ~as_date(.)) %>%
-
## 报告摘要统计
-
meflow %>%
-
as_tibble() %>%
-
dplyr::select %>%
-
tbl_summary %>%
-
as_kable()
-
表 5:每个站点平均日流量估计的汇总统计数据

-
ggplot(mean_daily_flow %>% fill_gaps()) +
-
geom_line(aes(date, mean_daily)) +
-
facet_wrap(~Site, ncol = 1, scales = "free_y") +
-
scale_x_date("Date", date_breaks = "1 month",
-
date_labels = "%F") +
-
labs(y = "Mean daily streamflow [cfs]") +
-
theme_ms() +
-
guides(x = guide_axis(angle = 90)) +
-
theme(axis.text.x = element_text(size = 8))
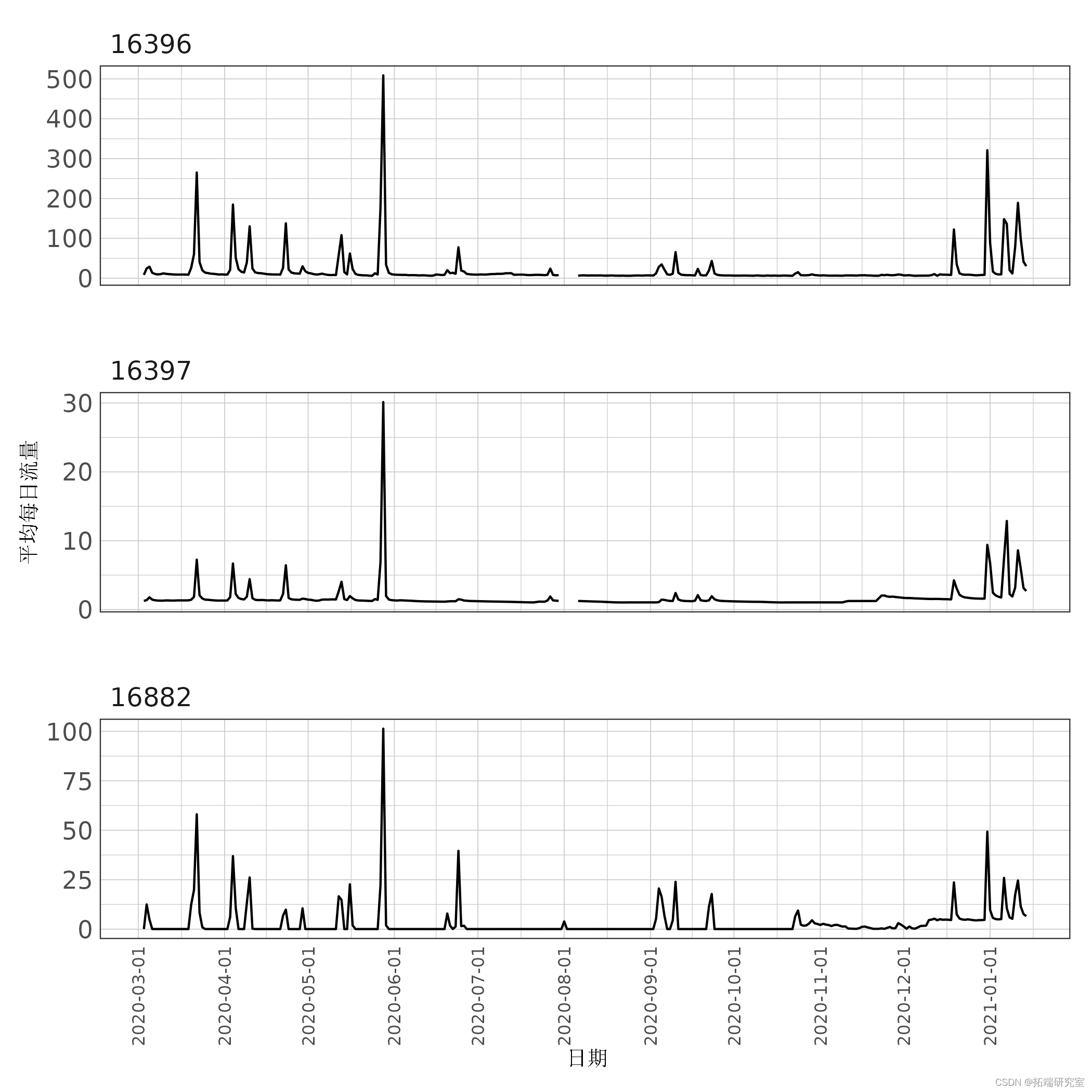
图 7:平均每日流量估计。
-
##导出数据
-
melow %>%
-
writcsv("modf.csv")
参考
Asquith, William H., Meghan C. Roussel, and Joseph Vrabel. 2006. “Statewide Analysis of the Drainage-Area Ratio Method for 34 Streamflow Percentile Ranges in Texas.” 2006-5286. U.S. Geological Survey.

最受欢迎的见解
1.R语言基于ARMA-GARCH-VaR模型拟合和预测实证研究