原文链接:http://tecdat.cn/?p=24694
原文出处:拓端数据部落公众号
本文首先展示了如何将数据导入 R。然后,生成相关矩阵,然后进行两个预测变量回归分析。最后,展示了如何将矩阵输出为外部文件并将其用于回归。
数据输入和清理
首先,我们将加载所需的包。
-
-
library(dplyr) #用于清理数据
-
library(Hmisc) #相关系数的显着性
然后,我们将使用 Fortran 读入数据文件并稍微清理数据文件。
-
-
# 确保将您的工作目录设置为文件所在的位置
-
# 位于,例如setwd('D:/下载) 您可以在 R Studio 中通过转到
-
# 会话菜单 - '设置工作目录' - 到源文件
-
-
# 选择数据的一个子集进行分析,存储在新的
-
# 数据框
-
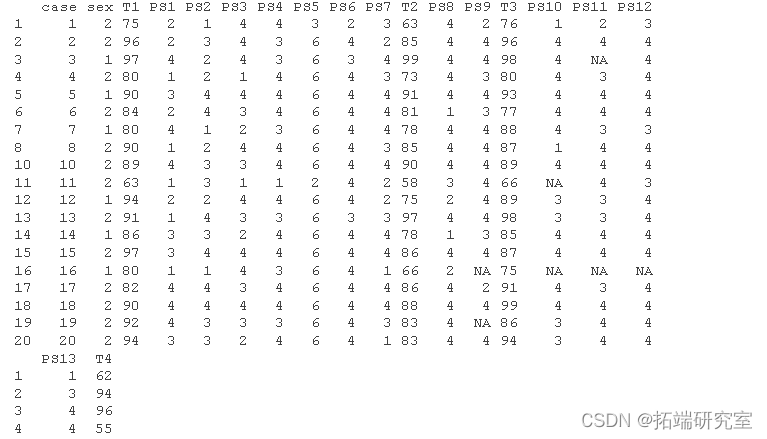
sub <- subset(des,case < 21 & case != 9)# != 表示不等于
-
-
#让我们看看数据文件
-
sub #注意 R 将原始数据中的空白单元格视为缺失,并将这些情况标记为 NA。 NA 是默认值
-
-
-
# 使用 dplyr 对特定测试进行子集化
-
select(sub, c(T1, T2, T4))
-
-
-
# 使用 psych 包获取描述
-
-
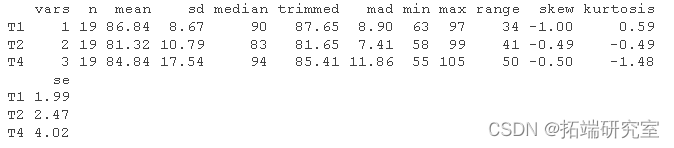
请注意,R 将原始数据中的空白单元格视为缺失,并将这些情况标记为 NA。NA 是 R 实现的默认缺失数据标签。
创建和导出相关矩阵
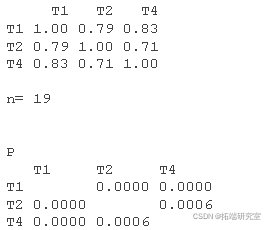
现在,我们将创建一个相关矩阵,并向您展示如何将相关矩阵导出到外部文件。请注意,创建的第一个相关矩阵使用选项“pairwise”,该选项对缺失数据执行成对删除。这通常是不可取的,因为它删除了变量,而不是整个案例,因此可能会使参数估计产生偏差。第二个选项,“complete”,对缺失数据实施列表删除,这比成对删除更可取,因为参数估计偏差较小(删除整个案例,而不仅仅是特定变量)。
-
# 在变量之间创建一个相关矩阵
-
cor <- cor( "pairwise.complete.obs",
-
cor #相关矩阵

-
-
rcorr( test) # 相关性的显著性
-
-
-
# 将相关矩阵保存到文件中
-
write.csv( cor, "PW.csv")
-
-
-
cor(test, method = "pear")
-
cor #注意我们使用列表删除时的差异
-

-
-
# 将相关矩阵保存到硬盘上的文件中
-
write.csv(cor, "cor.csv")
-
多元回归
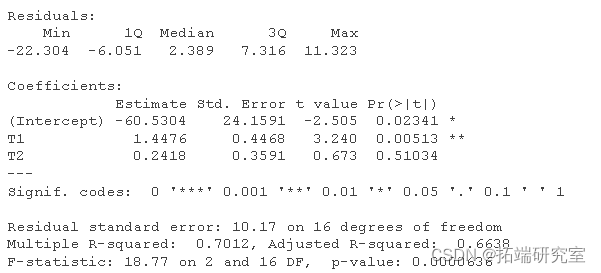
现在,我们将做一些多元回归。具体来说,我们将查看测试 1 和 2 是否预测测试4。我们还将检查一些模型假设,包括是否存在异常值以及检验之间是否存在多重共线性(方差膨胀因子或 VIF)。其中一些代码可帮助您将残差、预测值和其他案例诊断保存到数据帧中以供以后检查。请注意,lm 命令默认为按列表删除。

summary(model)
-
-
# 将拟合值和预测值保存到数据框
-
Predicted
-
-
# 保存个案诊断(异常值)
-
hatvalues(model)
-
-
-
# 多重共线性检验
-
vif(model)
-
![]()
-
-
vcov(ol) #保存系数的方差协方差矩阵
-
cov(gdest) #保存原始数据的协方差矩阵
-
模型结果及其含义:
-
多重 R 平方 告诉您在给定模型中自变量的线性组合的情况下预测或解释的因变量的方差比例。
-
调整后的 R 平方 告诉您总体水平 R 平方值的估计值。
-
残差标准误差 告诉您残差的平均标准偏差(原始度量)。如果平方是均方误差 (MSE),则包含在残差旁边的方差分析表中。
-
F 统计量之后的显着性项 提供了针对没有预测变量的仅截距模型的综合检验(您的模型是否比仅平均值更好地预测您的结果?)
-
方差分析表 Mean Sq 残差的方差
-
方差膨胀因子 告诉您模型中的预测变量之间是否存在多重共线性。通常大于 10 的数字表示存在问题。越低越好。
-
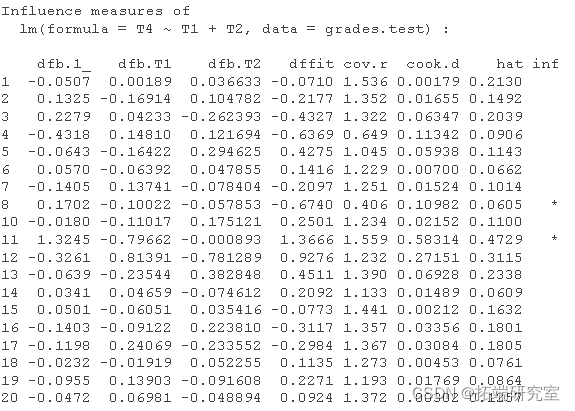
影响度量 提供了许多个案诊断。在此输出中,相应的列编号按各自的顺序表示:截距的 dfbeta、X1 的 dfbeta、x2 的 dfbeta、dffits(全局影响,或 Yhat(预测的 Y)基于案例的删除而改变了多少)、协方差比率(通过删除此观察值,估计的协方差矩阵的行列式的变化),库克的距离(影响),杠杆率(就独立预测变量的值而言,观察值有多不寻常?),显着性检验标志着案例作为潜在的异常值。请注意,发现异常值的一种方法是寻找超出均值 2 个标准差以上的残差(均值始终为 0)。
接下来,让我们绘制一些模型图。
-
-
# 制作模型的图表
-
plot(T4 ~ T1, data =test)
-
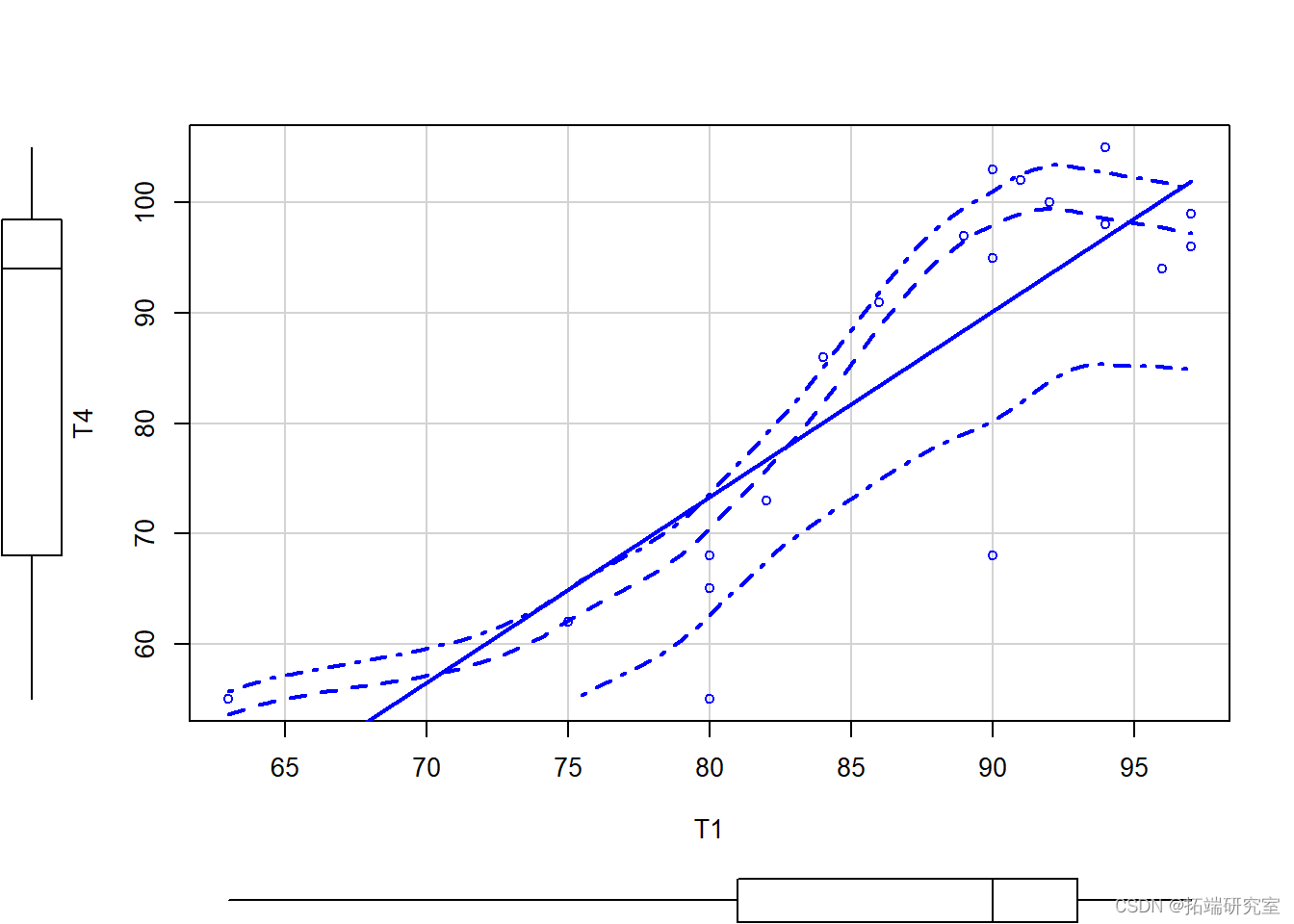
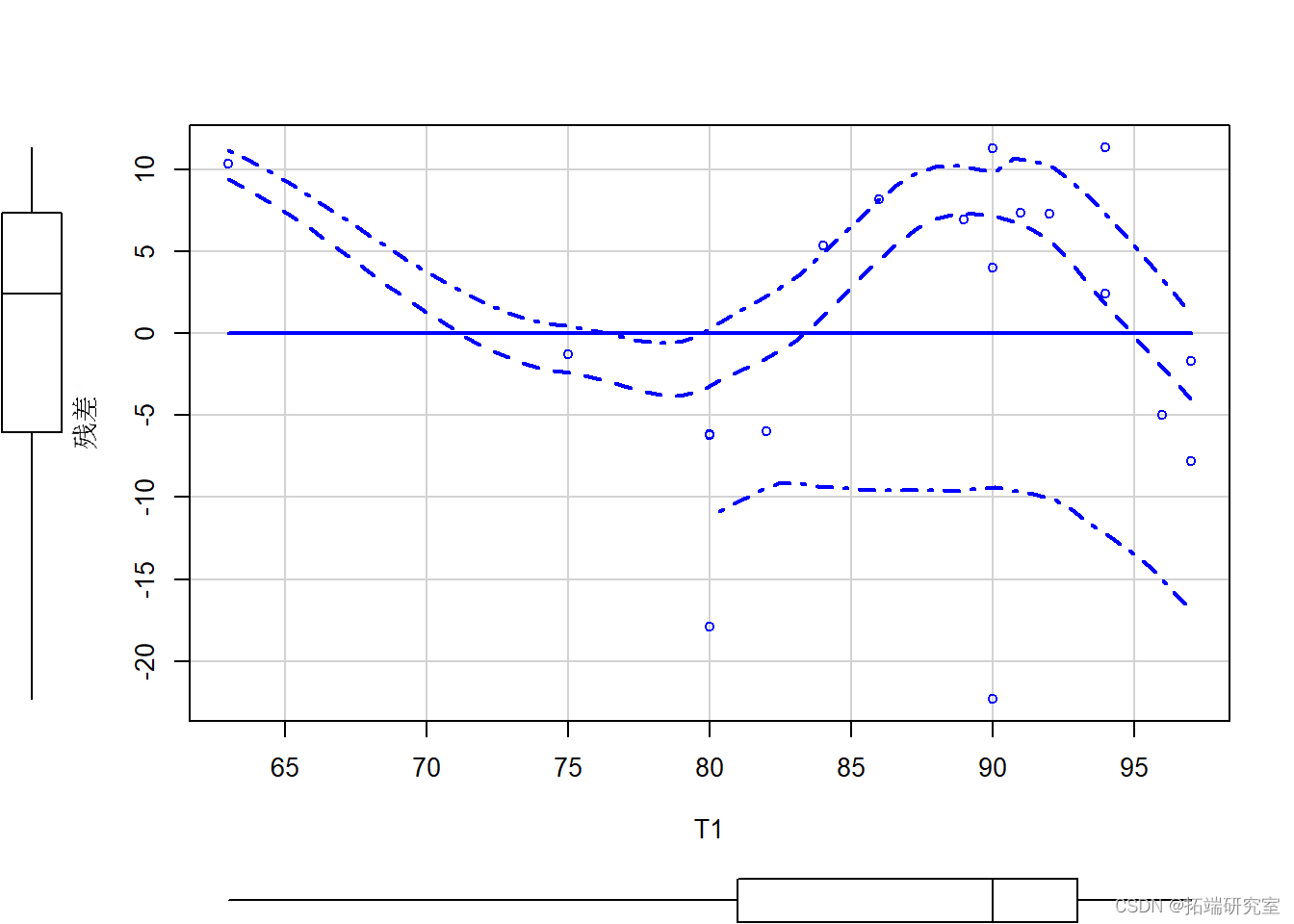
绿线表示线性最佳拟合,而红线表示LOESS(局部加权回归)_拟合。红色虚线表示LOESS(局部加权回归)_平滑拟合线的 +-1 标准误差。第一个散点图命令的额外参数标记每个数据点以帮助识别异常值。注意第二个图,如果残差是正态分布的,我们会有一条平坦的线而不是一条曲线。
使用多元回归来显示系数如何是残差的函数
现在,让我们看看系数是如何作为残差的函数的。我们将从之前的回归中构建 T1 的系数。首先,我们将创建 T4(标准)的残差,控制 T1 以外的预测变量。
-
-
-
residuals(mot4) #将残差保存在原始数据框中
-
接下来,我们为 T1(预测变量)创建残差,控制 T1 以外的预测变量。我们在 T2 上回归 T1,得到 Y=b0+b1T2,其中 Y 是 T1。残差是所有与 T2 无关的东西。
现在我们使用 T4 运行回归,将所有 T2 作为 DV 删除,T1 将所有 T2 作为自变量删除。
anova

-
-
summary(modf) #模型结果
-
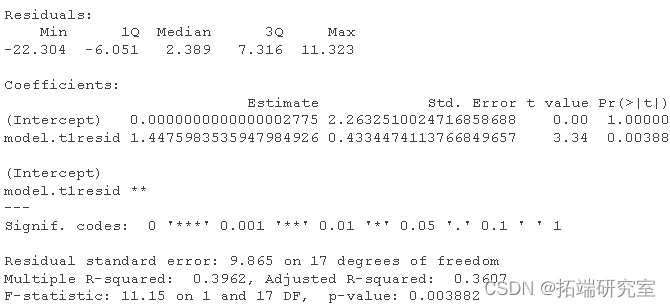
请注意,该回归系数与先前的两个预测器回归中的系数相同。接下来,我们将运行另一个以案例为DV的回归。我们将创建一个新的图表,以显示杠杆率只取决于预测因素而不是因变量。
-
anova(modeage)
-
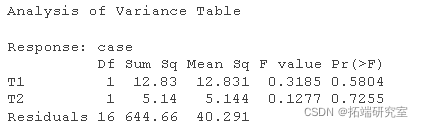
summary(modage)
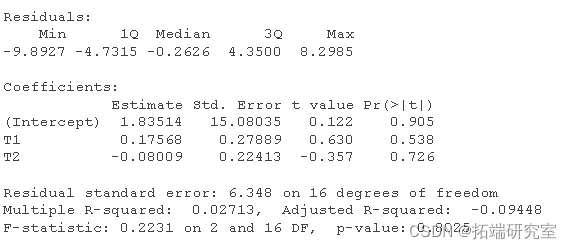
plot(lev ~ cae, data = grb)
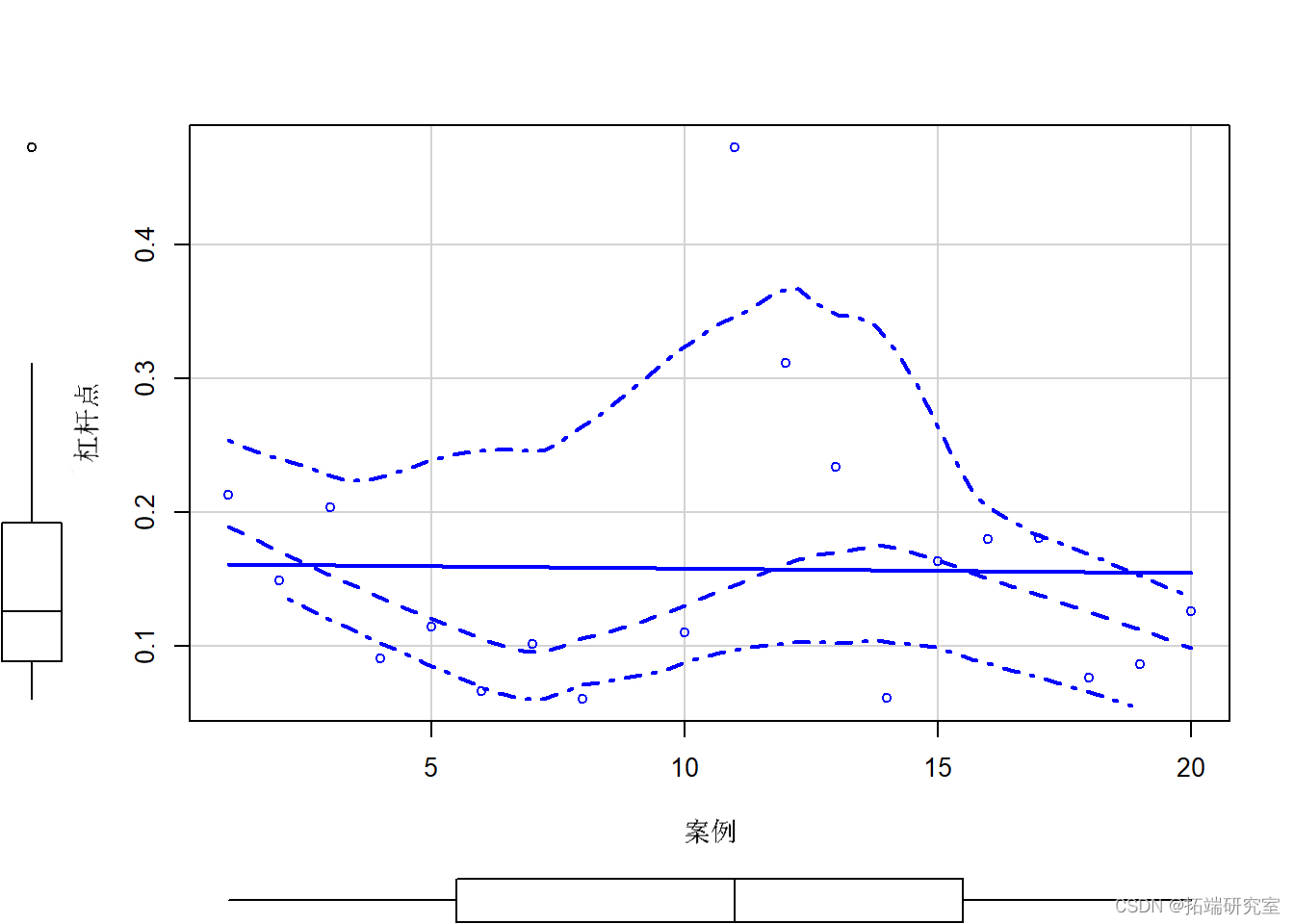
请注意,在SEM中,没有简单的距离或杠杆措施,但我们可以得到杠杆,因为它与DV是分开的。如果我们能找出一个极端的案例,我们在有和没有这个案例的情况下进行分析,以确定其影响。输出的变化将是对杠杆的测试。
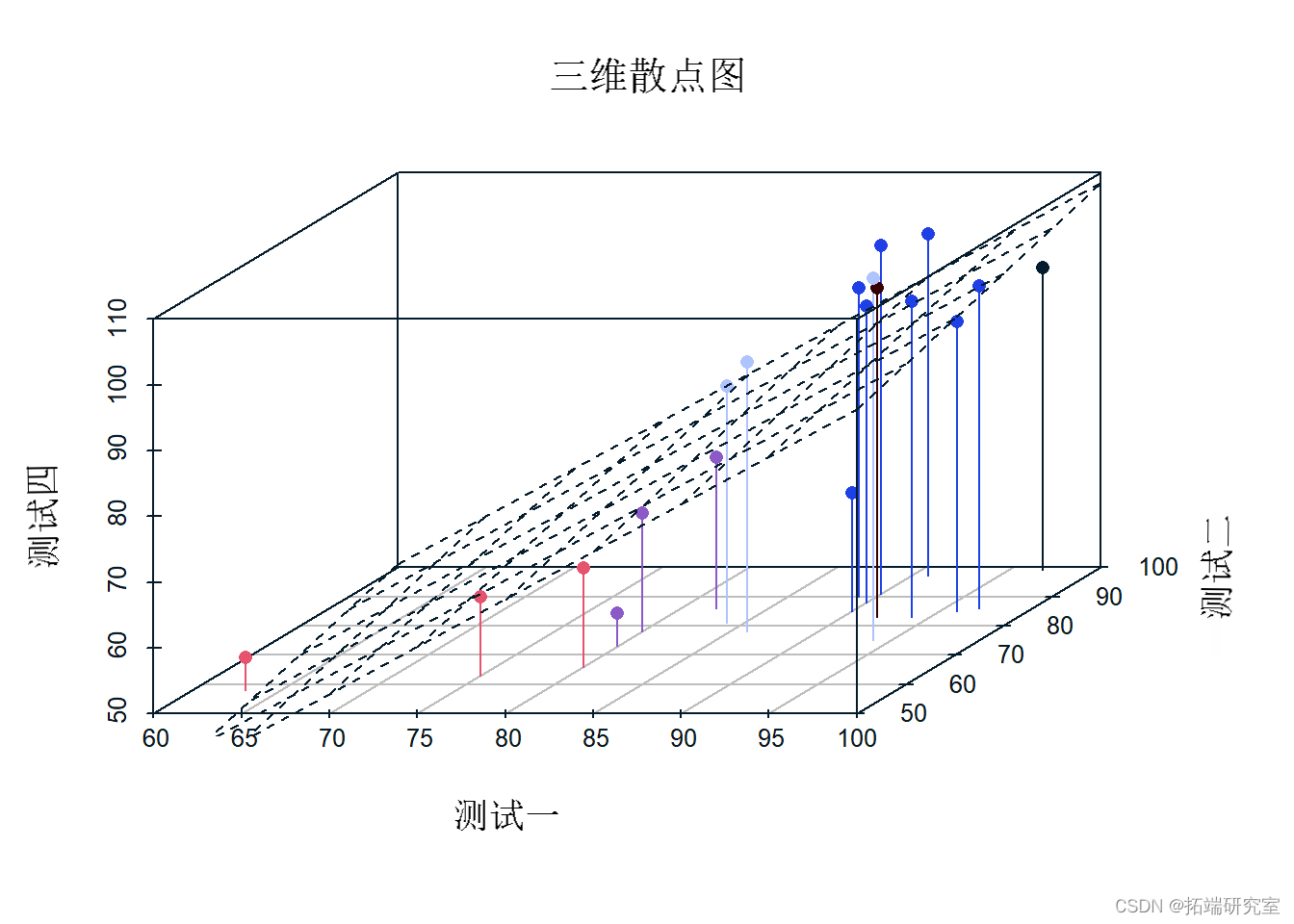
现在我们制作测试之间关系的 3d 散点图。
-
plot(T1,T2, T4,
-
3d(model) #使用我们先前的模型来绘制一个回归平面
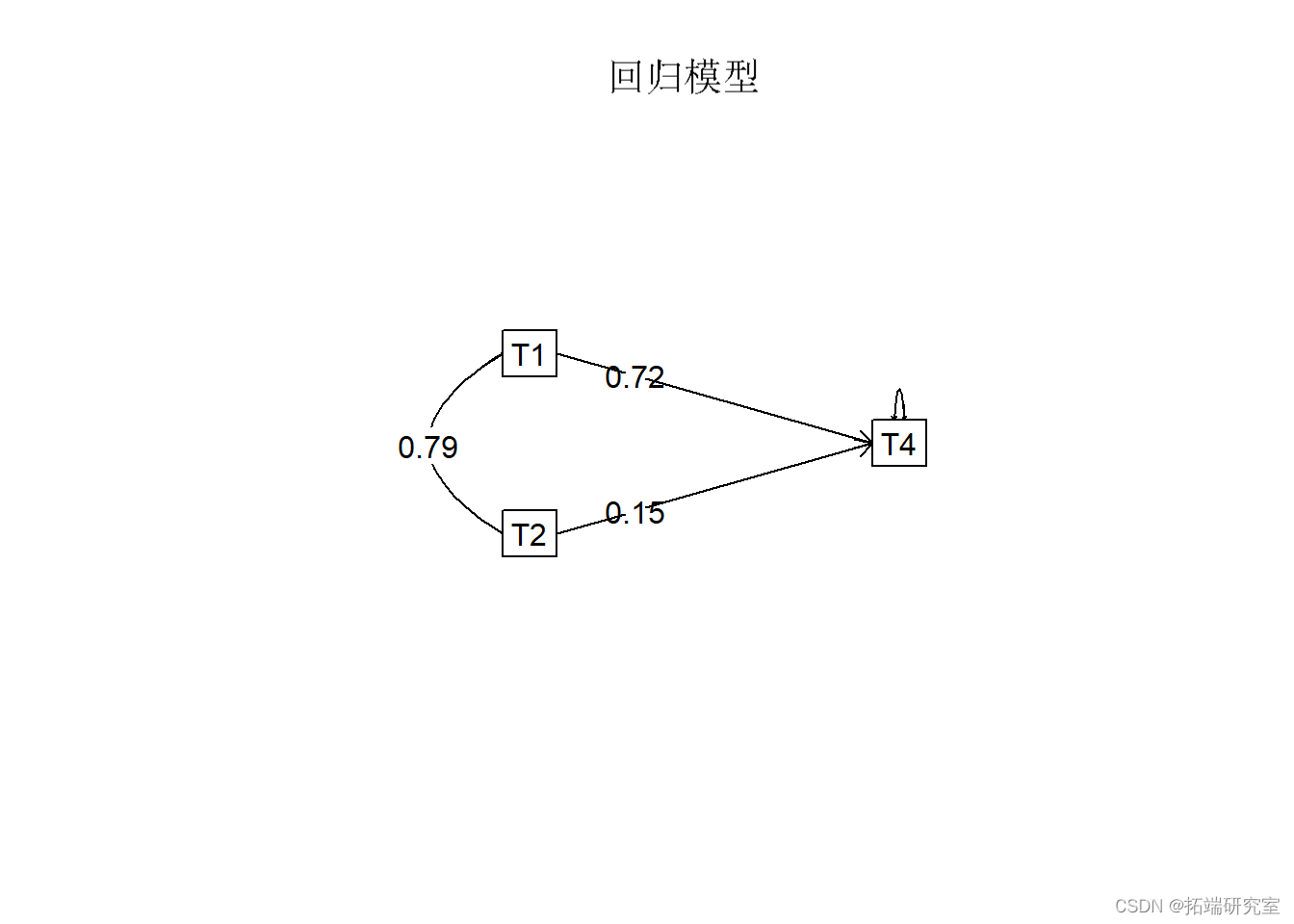
使用相关矩阵的多元回归
现在我们将展示如何仅使用相关矩阵进行回归。如果你想对提供相关和/或协方差矩阵的现有论文做额外的分析,但你无法获得这些论文的原始数据,那么这就非常有用。
-
-
#从你电脑上的文件中调入相关矩阵。
-
read.csv("cor.csv")
-
data.matrix(oaw) #从数据框架到矩阵的变化
-
-
#用相关矩阵做回归,没有原始数据
-
mdeor
-


最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现