原文链接:http://tecdat.cn/?p=23940
原文出处:拓端数据部落公众号
时间序列是以固定时间区间记录的观察序列。本指南带你完成在Python中分析一个给定的时间序列的特征的过程。
内容
- 什么是时间序列?
- 如何在 Python 中导入时间序列?
- 什么是面板数据?
- 时间序列的可视化
- 时间序列中的模式
- 加法和乘法的时间序列
- 如何将一个时间序列分解成其组成部分?
- *稳的和非*稳的时间序列
- 如何使一个时间序列成为*稳的?
- 如何测试*稳性?
- 白噪声和*稳序列之间的区别是什么?
- 如何使一个时间序列去趋势化?
- 如何使时间序列去季节化?
- 如何检验时间序列的季节性?
- 如何处理时间序列中的缺失值?
- 什么是自相关和部分自相关函数?
- 如何计算部分自相关函数?
- 滞后图
- 如何估计一个时间序列的可预测性?
- 为什么和如何使时间序列*滑化?
- 如何使用格兰杰因果检验来了解一个时间序列是否有助于预测另一个时间序列?
1. 什么是时间序列?
时间序列是以固定时间区间记录的观察序列。
根据观察的频率,一个时间序列通常可能是每小时、每天、每周、每月、每季度和每年。有时,你也可能有以秒为单位的时间序列,比如,每分钟的点击量和用户访问量等等。
为什么要分析一个时间序列?
因为这是你对该序列进行预测前的准备步骤。
此外,时间序列预测具有巨大的商业意义,因为对企业来说很重要的东西,如需求和销售,网站的访问量,股票价格等基本上都是时间序列数据。
那么,分析一个时间序列涉及什么呢?
时间序列分析涉及到对序列性质的各个方面的理解,这样你就能更好地了解创造有意义和准确的预测。
2. 如何在Python中导入时间序列?
那么,如何导入时间序列数据呢?
时间序列的数据通常存储在.csv文件或其他电子表格格式中,包含两列:日期和测量值。
我们使用pandas包中的read_csv()来读取时间序列数据集(一个关于药品销售的csv文件)作为pandas数据框。添加parse_dates=['date']参数将使日期列被解析为一个日期字段。
-
-
import pandas as pd
-
-
# 导入数据
-
df = pd.read_csv('10.csv
-
', parse_dates=['date'])
-
df.head()
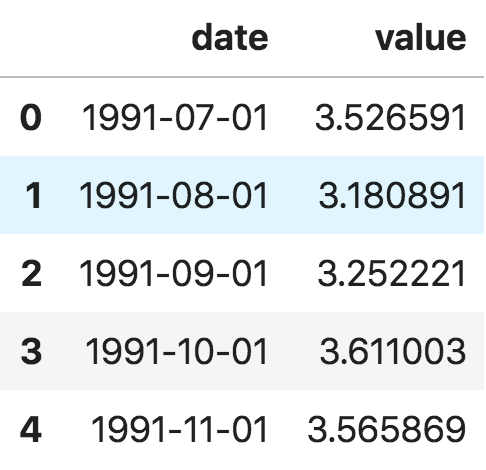
数据框架时间序列
另外,你也可以把它导入为一个以日期为索引的pandas序列。你只需要在pd.read_csv()中指定index_col参数就可以了。
pd.read_csv('10.csv', parse_dates=['date'], index_col='date')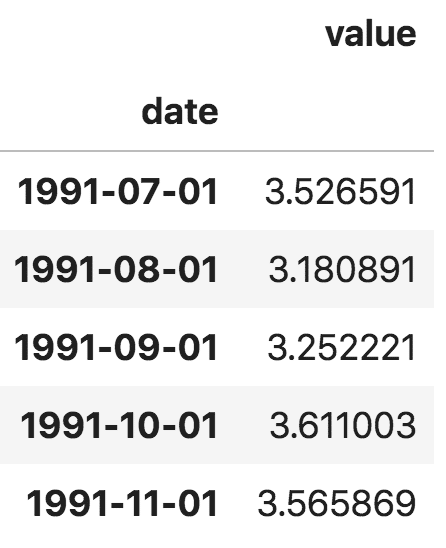
3. 什么是面板数据?
面板数据也是一种基于时间的数据集。
不同的是,除了时间序列之外,它还包含一个或多个在相同时间段内测量的相关变量。
通常情况下,面板数据中存在的列包含了有助于预测Y的解释变量,前提是这些列在未来的预测期是可用的。
下面是一个面板数据的例子。
df.head()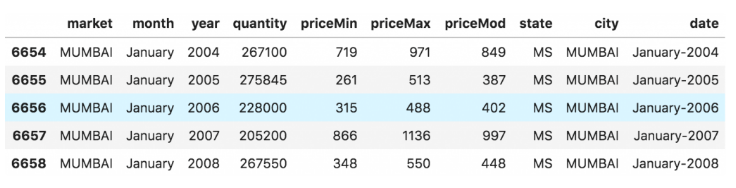
面板序列
4. 时间序列的可视化
让我们用matplotlib来可视化这个序列。
-
-
# 时间序列数据源:R中的fpp pacakge。
-
import matplotlib.pyplot as plt
-
-
# 绘制图表
-
def plot_df(df, x, y, title="", xlabel='日期', dpi=100):
-
-
plt.show()
-
-
-
-
-
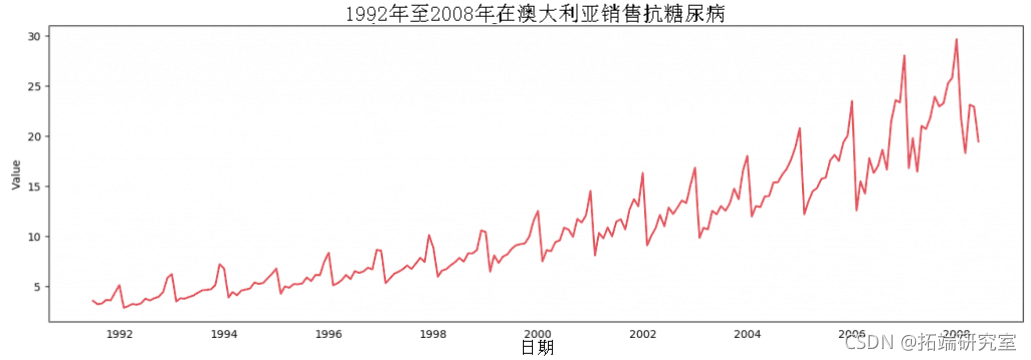
时间序列的可视化
由于所有的值都是正数,你可以在Y轴的两边显示,以强调增长。
-
-
# 导入数据
-
x = df['date'].values
-
-
# 绘图
-
fig, ax = plt.subplots(1, 1, figsize=(16,5), dpi= 120)
-
plt.fill(x, y1=y1, y2=-y1, alpha=0.5)
-
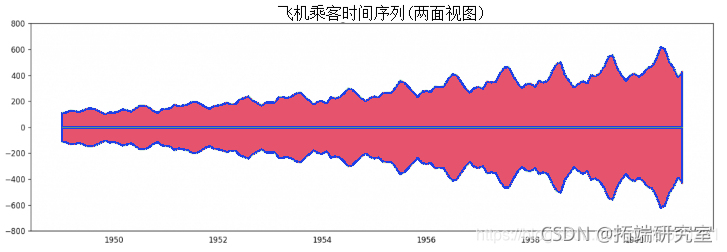
航空乘客数据--两面序列
由于它是一个月度的时间序列,并且每年都遵循一定的重复模式,你可以在同一张图中把每年的情况作为一个单独的线条来绘制。这让你可以并排比较每年的模式。
时间序列的季节图
-
-
# 导入数据
-
-
df.reset_index(inplace=True)
-
-
# 准备好数据
-
-
years = df['year'].unique()
-
-
# 预备颜色
-
-
np.random.choice(list(mpl.color), len(year),
-
-
# 绘制图表
-
-
plt.text(df.loc[df.year==y, :].shape[0]-.9]
-
-
-
plt.gca().set(xlim=(-0.3, 11)
-
-
plt.title("药品销售时间序列的季节图", fontsize=20)
-
-
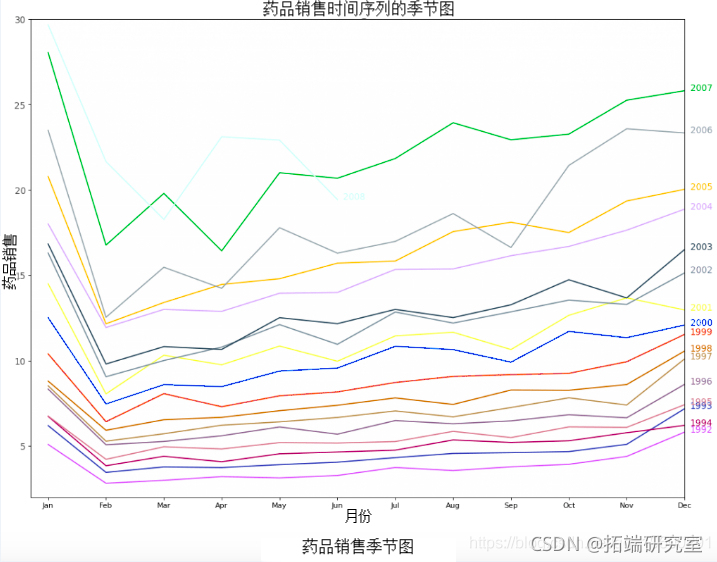
药品销售的季节性图谱
每年2月,药品销售量急剧下降,3月再次上升,4月再次下降,如此反复。显然,这种模式每年都会在某一年内重复出现。
然而,随着时间的推移,药品销售量总体上有所增加。你可以用一个漂亮的年度图表很好地展示这一趋势以及它每年的变化情况。同样地,你也可以做一个按月排列的boxplot来显示每月的分布情况。
逐月(季节性)和逐年(趋势)分布的箱线图
你可以按季节性对数据进行分组,看看数值在某年或某月是如何分布的,以及它在不同时期的对比情况。
-
-
# 导入数据
-
-
df.reset_index(inplace=True)
-
-
# 准备好数据
-
df['年'] = [d.year for d in df.date]
-
df['月'] = [d.strftime('%b') for d in df.date]
-
-
-
# 绘制图表
-
sns.boxplot(x='年', y='值', data=df, ax=axes[0])
-
sns.boxplot(x='月', y='值', data=df.loc[~df.year.isin([1991, 2008]), :] )
-
-
-
-
-
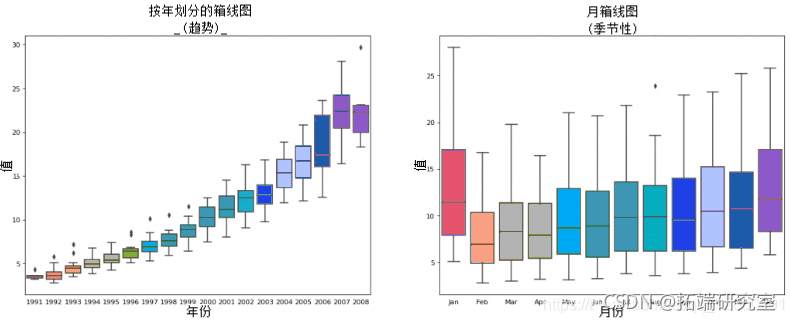
按年和按月排列的箱线图
箱线图使年度和月份的分布变得明显。另外,在按月排列的图表中,12月和1月的药品销售量明显较高,这可归因于假日折扣季节。
到目前为止,我们已经看到了识别模式的相似性。现在,如何找出与通常模式的任何偏差?
5. 时间序列中的模式
任何时间序列都可以被分成以下几个部分。 基础水*+趋势+季节性+误差
当在时间序列中观察到有一个增加或减少的斜率时,就可以观察到趋势。而季节性是指由于季节性因素,在定期区间之间观察到明显的重复模式。这可能是由于一年中的哪个月,哪个月的哪一天,工作日或甚至一天中的哪个时间。
然而,并非所有时间序列都必须有趋势和/或季节性。一个时间序列可能没有一个明显的趋势,但有一个季节性。反之,也可以是真实的。
因此,一个时间序列可以被想象为趋势、季节性和误差项的组合。
-
-
fig, axes = plt.subplots(1,3, figsize=(20,4), dpi=100)
-
-
-
pd.read_csv.plot( legend=False, ax=axes[2])
-
-
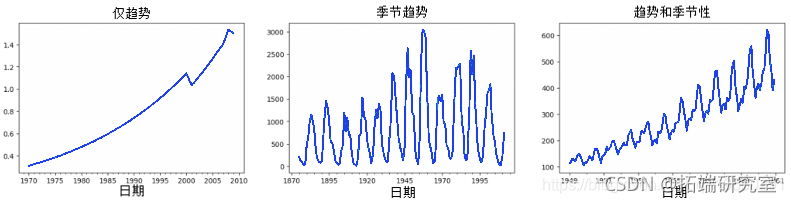
时间序列中的模式
另一个需要考虑的方面是周期性行为。当序列中的上升和下降模式不发生在固定的基于日历的时间区间内时,就会发生这种情况。应注意不要将 "周期性 "效应与 "季节性 "效应混淆。
那么,如何区分 "周期性 "和 "季节性 "模式?
如果这些模式不是基于固定的日历频率,那么它就是周期性的。因为,与季节性不同,周期性效应通常受到商业和其他社会经济因素的影响。
6. 加法和乘法的时间序列
根据趋势和季节性的性质,一个时间序列可以被建模为加法或乘法,其中,序列中的每个观测值可以表示为各组成部分的和或积。
加法时间序列:值=基础+趋势+季节性+误差
乘法时间序列:值=基础x趋势x季节性x误差
7. 如何将一个时间序列分解成其组成部分?
你可以对一个时间序列进行经典的分解,将该序列视为基数、趋势、季节性指数和残差的加法或乘法组合。
statsmodels中的 seasonal_decompose 可以方便地实现这一点。
-
-
-
-
# 乘法分解
-
decompose(df['value'], model='multiplicative')
-
-
# 加法分解
-
decompose(df['value'], model='additive')
-
-
# 绘图
-
result_mul.plot().suptitle( fontsize=22)
-
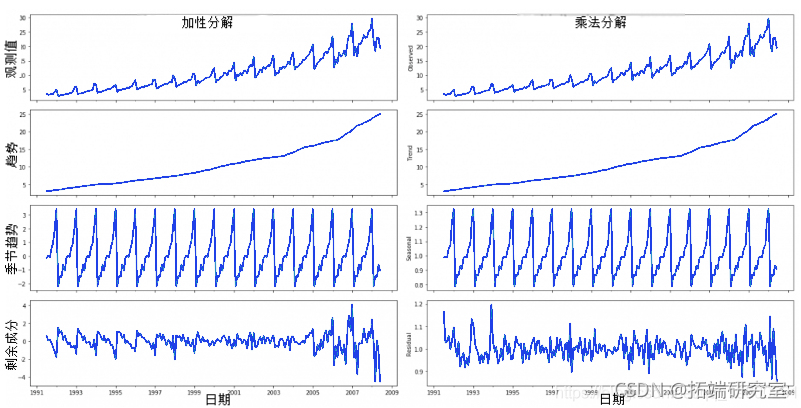
加法和乘法分解
设置extrapolate_trend='freq'可以看到序列开始时趋势和残差中的任何缺失值。
如果你仔细看一下加法分解的残差,它有一些模式残留。然而,乘法分解看起来相当随机。因此,理想情况下,对于这个特定的序列,乘法分解应该是首选。
趋势、季节性和残差成分的数字输出存储在result_mul输出本身。让我们把它们提取出来,放在一个数据框中。
-
-
# 提取成分----
-
# 实际值=(季节性*趋势*残差)的乘积
-
-
constructed.columns = ['seas', 'trendance', 'resid', 'actual_values'] 。
-
constructed.head()
-
如果你检查一下,seas、trend和resid列的乘积应该正好等于actual_values。
8. *稳和非*稳的时间序列
*稳性是时间序列的一个属性。一个*稳的序列是指该序列的值不是时间的函数。
也就是说,序列的统计属性,如*均数、方差和自相关,随着时间的推移是不变的。序列的自相关只不过是序列与它以前的值的相关性,更多的是关于这一点。
一个*稳的时间序列也没有季节性影响。
那么,如何识别一个序列是否是*稳的?让我们绘制一些例子来说明。
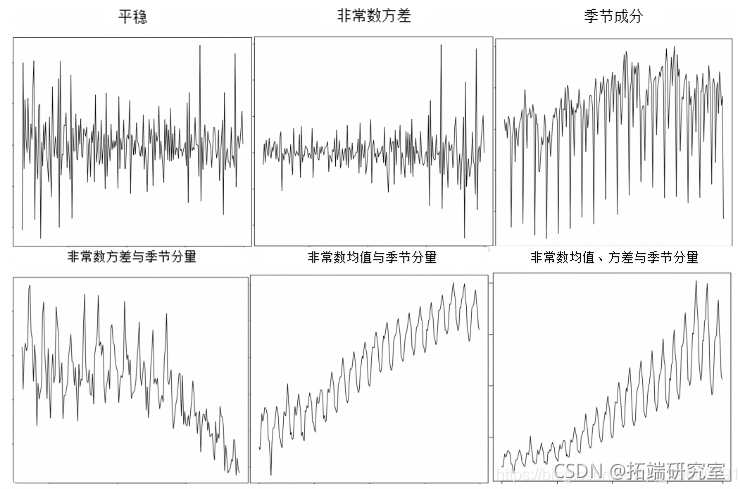
*稳和非*稳的时间序列
那么,为什么*稳的序列很重要呢?
我稍后会说到这个问题,但要知道,通过应用适当的转换,几乎可以使任何时间序列成为*稳的。大多数统计预测方法都被设计为在*稳的时间序列上工作。预测过程的第一步通常是做一些转换,把非*稳序列转换成*稳的。
9. 如何使一个时间序列*稳?
你可以通过以下方式使序列*稳
- 对序列进行差分(一次或多次
- 取序列的对数
- 取序列的第n次根
- 上述方法的组合
使序列*稳的最常见和最方便的方法是对数列至少进行一次差分,直到它成为*似*稳的。
那么,什么是差分?
如果Y_t是时间't'的值,那么Y的第一个差值=Yt-Yt-1。更简单地说,序列只不过是用当前值减去下一个值。
如果第一次差分不能使一个序列*稳,你可以进行第二次差分。以此类推。
例如,考虑以下序列。[1, 5, 2, 12, 20]
第一次差分可以得到。[5-1, 2-5, 12-2, 20-12] = [4, -3, 10, 8]
二次差分得出。[-3-4, -10-3, 8-10] = [-7, -13, -2]
9. 为什么在预测前要使非稳态序列成为稳态?
预测一个*稳的序列是相对容易的,而且预测结果也更可靠。
一个重要的原因是,自回归预测模型本质上是线性回归模型,利用序列本身的滞后期作为预测因子。
我们知道,如果预测因子(X变量)不相互关联,线性回归效果最好。因此,序列的*稳化解决了这个问题,因为它消除了任何持续的自相关,从而使预测模型中的预测因子(序列的滞后)几乎是独立的。
现在我们已经确定了序列*稳化的重要性,那么你如何检查一个给定的序列是否是*稳的?
10. 如何检验*稳性?
一个序列的*稳性可以通过观察序列的图表来确定,就像我们之前做的那样。
另一种方法是将序列分成2个或更多的连续部分,并计算*均数、方差和自相关等汇总统计数据。如果统计数字有很大差异,那么这个序列就不可能是*稳的。
然而,你需要一种方法来定量地确定一个给定的序列是否是*稳的。这可以通过称为 "单位根测试 "的统计测试来完成。这方面有多种变化,测试检查一个时间序列是否是非稳态的并拥有单位根。
单位根测试有多种实现方式,例如。
- Augmented Dickey Fuller 检验(ADH Test)
- Kwiatkowski-Phillips-Schmidt-Shin – KPSS 检验(趋势*稳)
- Philips Perron 检验(PP 检验)
最常用的是ADF检验,无效假设是时间序列拥有单位根,并且是非*稳的。所以,如果ADH检验中的P值小于显著性水*(0.05),你就拒绝无效假设。
另一方面,KPSS检验是用来检验趋势*稳性的。空假设和P值的解释与ADH检验正好相反。下面的代码使用python中的statsmodels包来实现这两个检验。
-
-
-
# ADF测试
-
result = adfuller(df.value.values, autolag='AIC')
-
-
# KPSS测试
-
result = kpss(df.value.values, regression='c')
-
print('\nKPSS Statistic: %f' % result[0])

11. 白噪声和*稳数列之间有什么区别?
与*稳序列一样,白噪声也不是时间的函数,即它的*均值和方差不随时间变化。但不同的是,白噪声是完全随机的,*均值为0。
在白噪声中,没有任何模式。如果你把调频收音机中的声音信号看作是一个时间序列,你在各频道之间听到的空白声音就是白噪声。
在数学上,一个*均数为0的完全随机的数字序列就是白噪声。
np.random.randn(1000)
随机白噪声
12. 如何对时间序列进行去趋势处理?
去时间序列的趋势是指从一个时间序列中去除趋势成分。但如何提取趋势呢?有多种方法。
- 从时间序列中去除最佳拟合线。最佳拟合线可以从以时间步骤为预测因素的线性回归模型中获得。对于更复杂的趋势,你可能想在模型中使用二次项(x^2)。
-
去除我们前面看到的从时间序列分解中得到的趋势成分。
-
去除*均数
-
应用像Baxter-King滤波器或Hodrick-Prescott滤波器这样的滤波器来去除移动*均趋势线或周期成分。
让我们来实现前两种方法。
-
-
# 使用scipy。减去最佳拟合线
-
signal.detrend(df.value.values)
-
plt.plot(detrended)
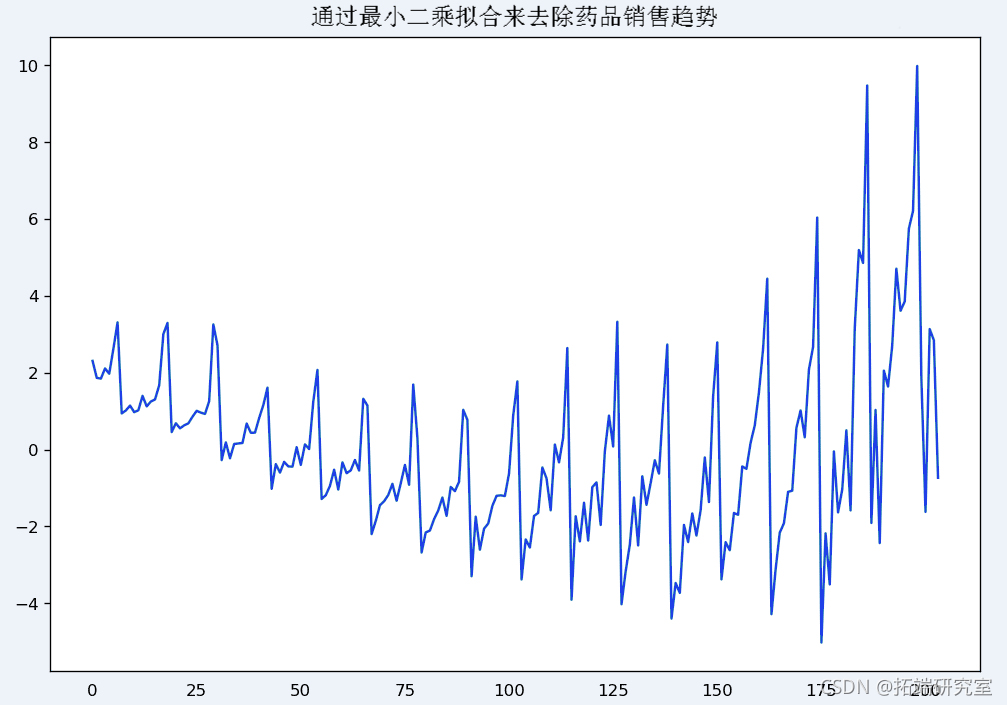
通过减去最小二乘法来解读时间序列的趋势
-
-
# 使用statmodels。减去趋势成分。
-
decompose(df['value'], model='multiplicative',
-
detrended = df.value.value - trend
-
plt.plot(detrended)
-
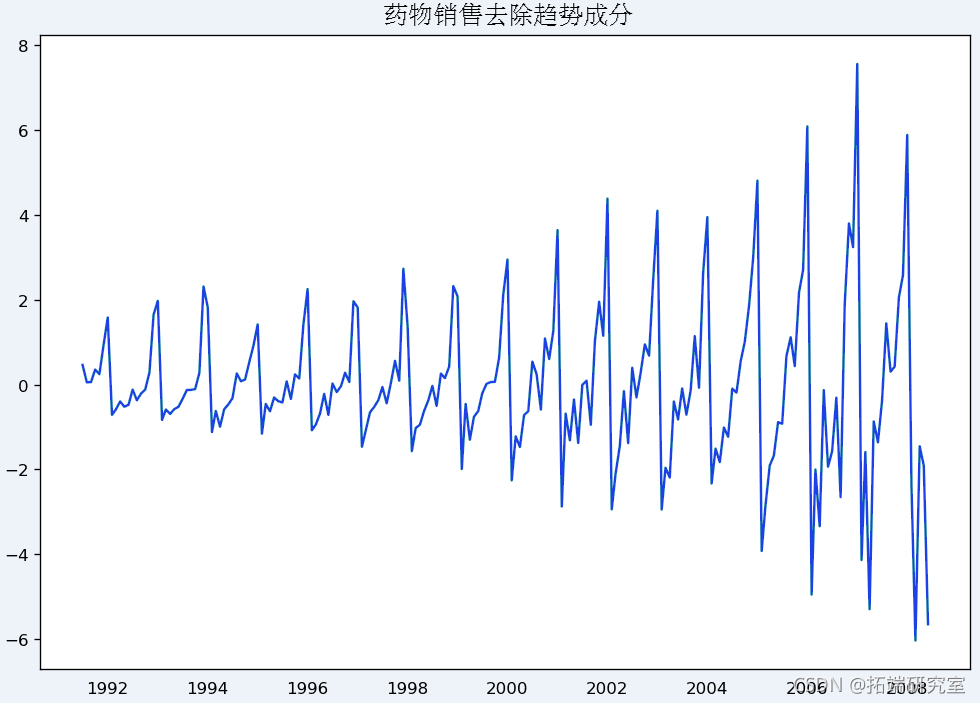
通过减去趋势成分进行去势
13. 如何对一个时间序列进行去季节化?
有多种方法可以使时间序列去季候性化。下面是几个例子。
-
-
- 1.取一个以季节性窗口为长度的移动*均线。这将在这个过程中使序列变得*滑。
-
-
- 2.序列的季节性差异(用当前值减去前一季的值)。
-
-
- 3.用从STL分解得到的季节性指数除以该序列。
-
如果除以季节性指数效果不好,可以尝试取序列的对数,然后进行去季节性处理。之后你可以通过取指数来恢复到原来的规模。
-
-
# 时间序列分解
-
seasonal_decompose(df['value'], model='multiplicative'')
-
# 去季节化
-
df. value.values / result_mul.seasonal
-
# 绘图
-
plt.plot(deseason)
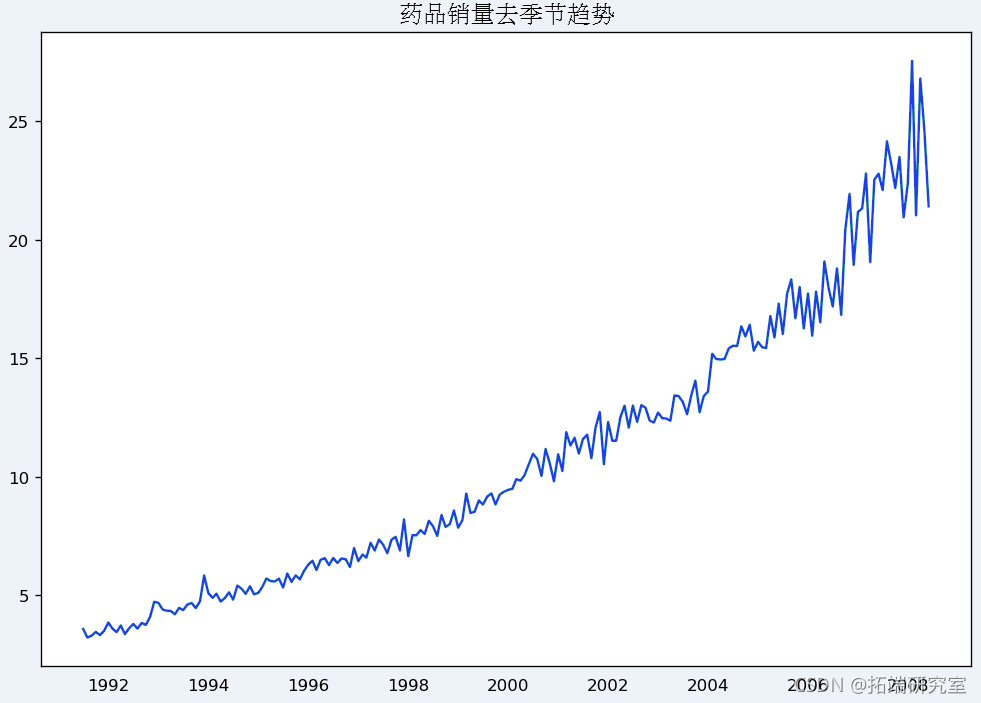
对时间序列进行反季节处理
14. 如何测试一个时间序列的季节性?
常见的方法是绘制序列图,检查*稳时间区间内的可重复模式。所以,季节性的类型是由时钟或日历决定的。
- 一天中的小时
- 月的一天
- 每周
- 月度
- 年
然而,如果你想对季节性有一个更明确的检查,可以使用自相关函数(ACF)图。更多关于ACF的内容将在接下来的章节中介绍。但是,当有强烈的季节性模式时,ACF图通常会显示出在季节性窗口的倍数上有明确的重复峰值。
例如,药品销售时间序列是一个月度序列,每年都有重复的模式。因此,你可以看到在第12、24、36......行的尖峰。
在真实的数据集中,这种强烈的模式很难被注意到,并可能被任何噪音所扭曲,所以你需要仔细观察。
-
-
# 画图
-
correlation_plot(df.value.tolist())
-
-
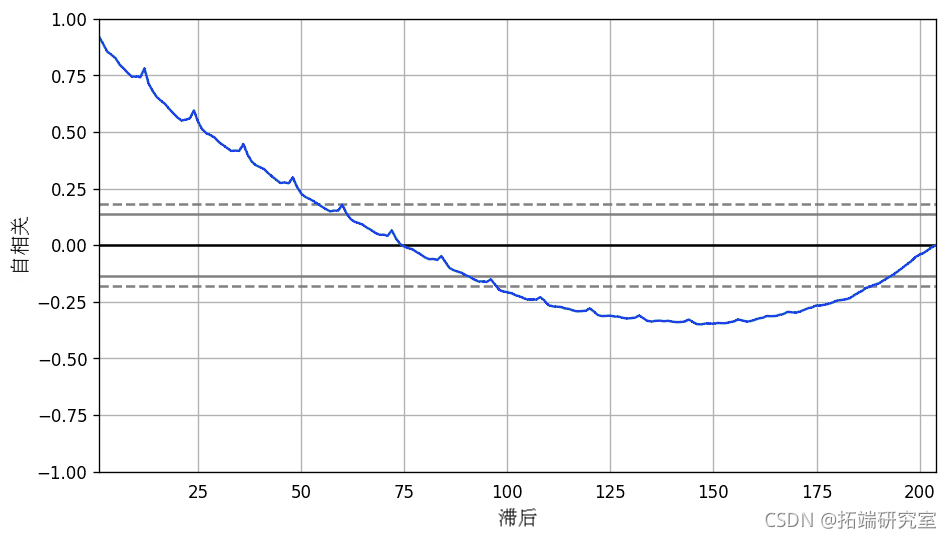
自相关图
另外,如果你想进行统计测试,CHTest可以确定是否需要进行季节性差分以使序列*稳化。
15. 如何处理时间序列中的缺失值?
有时,你的时间序列会有缺失的日期/时间。这意味着,这些时期的数据没有被捕获或无法获得。在这种情况下,你可以用零来填补这些时期。
其次,当涉及到时间序列时,你通常不应该用序列的*均值来替换缺失值,特别是在序列不是*稳的情况下。你可以做的是是向前填充前一个值。
然而,根据序列的性质,你要在得出结论之前尝试多种方法。一些有效的替代归因法的方法是。
- 后向填充
- 线性插值
- 二次插值
- 最*邻*均
- 季节性差值*均
为了衡量归因性能,我手动引入时间序列的缺失值,用上述方法进行归因,然后衡量归因与实际值的*均*方误差。
-
# 生成数据集
-
-
prcPupdate({'xtick.bottom' : False})
-
-
## 1. Actual -------------------------------
-
df_or.plot(style=".-")
-
-
-
## 2. 正向填充--------------------------
-
df_ffill = df.ffill()
-
-
-
## 3. 后向填充-------------------------
-
df_bfill = df.bfill()
-
-
## 4. 线性插值 ------------------
-
df['rownum'] = np.arange(df.shape[0])
-
-
## 5. 立体插值--------------------
-
f2 = interp1d(df_um'], df_nona['v kind='cubic')
-
-
# 内插法参考。
-
-
-
## 6. n "过去最*的邻居的*均值 ------
-
-
knnmean(df.value.values, 8)
-
np.round(meansquarerr('), 2)
-
-
## 7. 季节性*均值 ----------------------------
-
"""
-
计算相应季节性时期的*均值
-
ts: 时间序列的一维数组式
-
n: 时间序列的季节性窗口长度
-
"""
-
out = np.cpy(ts)
-
for i, val in merate(ts):
-
if np.isnan(val):
-
ts_seas = ts[i-1::-n] # 只有以前的季节
-
如果np.isan(np.naean(ts_seas))。
-
ts_seas = np.concenate([ts[i-1::-n], ts[i::n]]) # 以前和以后的
-
out[i] = np.nanan(ts_seas) * lr
-
-
seasonal_mean(df.value, n=12, lr=1.25)
-
-
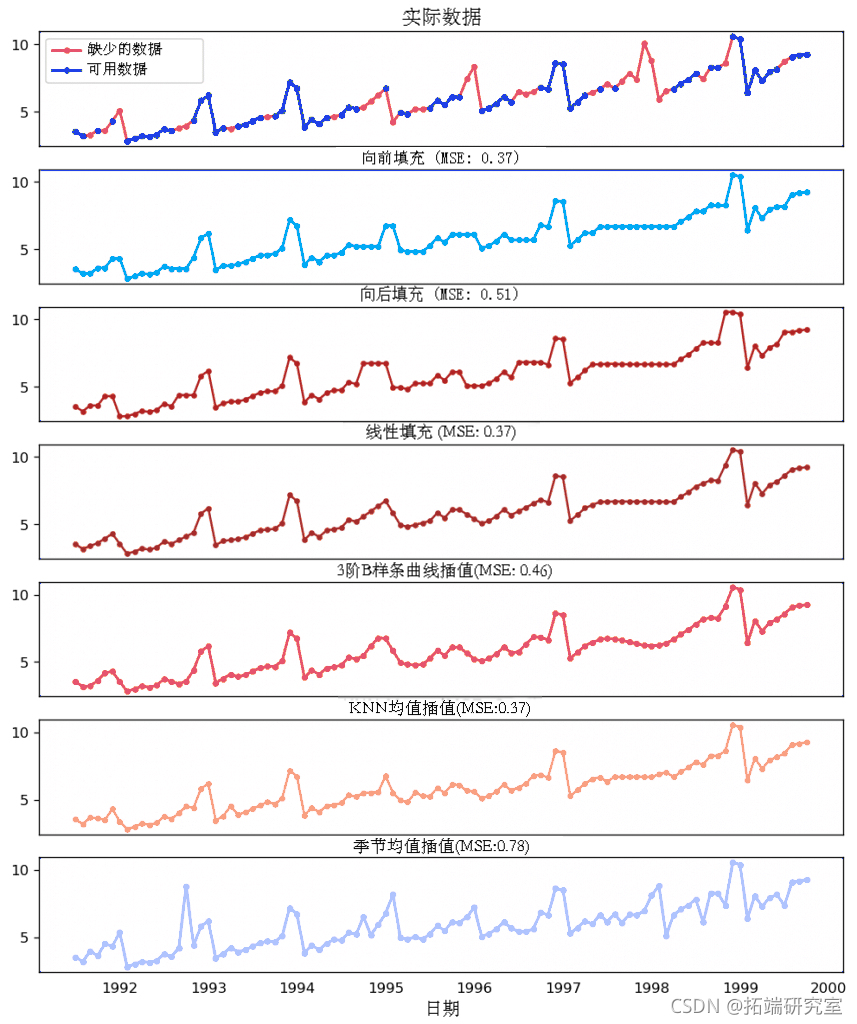
缺失值处理方法
你也可以考虑以下方法,这取决于你希望推断的准确程度。
- 如果你有解释变量,使用预测模型,如随机森林或k-Nearest Neighbors来预测。
- 如果你有足够的过去观测值,就预测缺失的值。
- 如果你有足够的未来观测值,就对缺失值进行反向预测
- 预测以前周期的对应值。
16. 什么是自相关和偏自相关函数?
自相关只是一个序列与它自己的滞后期的相关关系。如果一个序列是显著的自相关,那就意味着,该序列以前的值(滞后)可能有助于预测当前的值。
偏自相关也传达了类似的信息,但它传达的是一个序列与其滞后期的纯相关,排除了中间滞后期的相关贡献。
-
-
-
# 计算ACF和PACF直到50个滞后期
-
acf_50 = acf(value, nlags=50)
-
pacf_50 = pacf(value, nlags=50)
-
-
# 绘制图表
-
fig, axes = plt.subplots(1,2,figsize=(16,3))
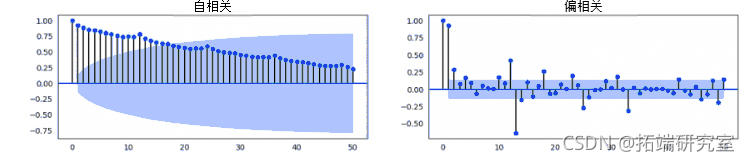
ACF和PACF
17. 如何计算偏自相关函数?
那么,如何计算偏自相关?
一个序列的滞后期(k)的偏自相关是该滞后期在Y的自回归方程中的系数。Y的自回归方程只不过是以其自身的滞后期为预测因素的Y的线性回归。
例如,如果Y_t是当前序列,Y_t-1是Y的滞后1,那么滞后3的偏自相关(Y_t-3)是Y_t-3的系数$alpha_3$,在以下方程中。
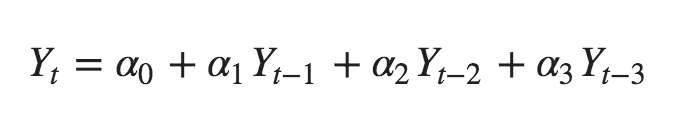
自回归方程
18. 滞后图
滞后图是一个时间序列与自身滞后的散点图。它通常是用来检查自相关的。如果在序列中存在任何像你下面看到的模式,该序列是自相关的。如果没有这样的模式,该序列可能是随机白噪声。
在下面关于太阳黑子区域时间序列的例子中,随着n_lag的增加,图变得越来越分散。
-
-
# #导入
-
-
a10 = pd.read_csv('10.csv')
-
-
# 绘图
-
for i, ax in enumerate(axes.flatten()[:4]):
-
-
-
fig.suptitle('药物销售的滞后图', y=1.05)
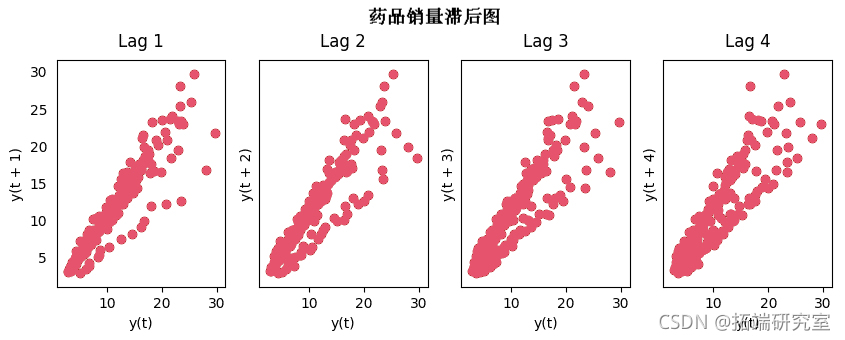
药物销售滞后曲线图
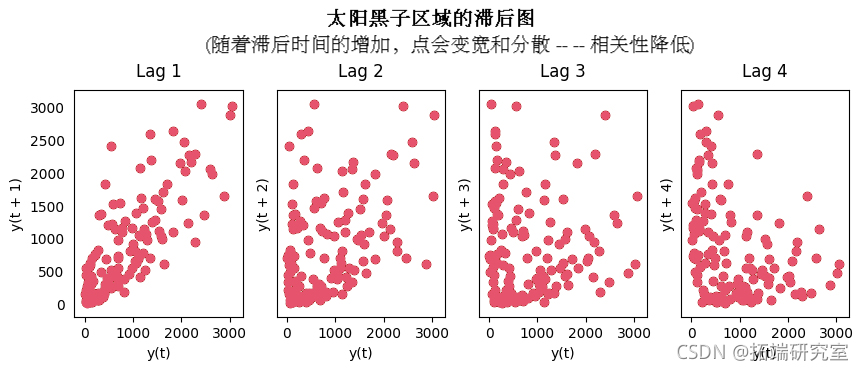
滞后图 太阳黑子
19. 如何估计一个时间序列的可预测性?
一个时间序列的规律性和可重复性越强,就越容易进行预测。*似熵 "可以用来量化一个时间序列中波动的规律性和不可预测性。
*似熵越高,预测就越困难。
另一个更好的替代方法是 "样本熵"。
样本熵与*似熵相似,但在估计复杂性方面更加一致,即使是较小的时间序列。例如,一个数据点较少的随机时间序列的 "*似熵 "可能比一个较 "规则 "的时间序列低,而一个较长的随机时间序列的 "*似熵 "会更高。
样本熵很好地处理了这个问题。请看下面的演示。
-
-
-
def AEn(U, m, r):
-
""计算Aproximate entropy""
-
def _maxdit(x_i, x_j):
-
returnmax([abs(u- va) for ua, va in zp(x_i, x_j)])
-
-
def _phi(m):
-
x = [[U[j]for in range(i, i ] for i in range(N - m + 1)]
-
C = [len([1 for x_jn x if _maist(x_i, x_j) <= r]) / (N - m + 1.0) for xi in x] 。
-
返回 (N - m +.0)**(-1) * sump.log(C))
-
-
N = len(U)

-
def Samp:
-
""计算样本熵"""
-
maxstx_i, x_j):
-
retur max([abs(ua - va) fo ua, vain zip(_i x_j)])
-
phi(m)
-
x = [[j]or j i ane(i, i m - 1 + 1] for iin age(N - m + 1)]
-
C= [len([1 for j in rane(len(x)) if i != j and _mist(x[i, xj]) <= r]) for i in rane(ln(x)) ]
-
= en()
-

20. 为什么和如何对时间序列进行*滑处理?
对一个时间序列进行*滑处理可能在以下方面有用。
- 减少信号中噪声的影响,得到一个经过噪声过滤的序列的*似值。
- *滑化后的序列可以作为解释原始序列本身的一个特征。
- 更好地观察基本趋势
那么,如何对一个序列进行*滑处理?让我们讨论一下以下方法。
- 取一个移动*均线
- 做一个 LOESS *滑(局部回归)。
- 做一个LOWESS*滑(局部加权回归)。
移动*均数只不过是定义宽度的滚动窗口的*均值。但你必须合理地选择窗口宽度,因为大的窗口尺寸会使序列过度*滑。例如,窗口尺寸等于季节性持续时间(例如:12个月的序列),将有效地消除季节性效应。
LOESS是 "LOcalized regrESSion "的简称,它在每个点的局部附*进行多次回归。它是在statsmodels软件包中实现的,你可以用frac参数来控制*滑的程度,该参数指定了附*的数据点的百分比,应该被视为适合回归模型。
-
-
# 导入
-
pd.read_csv('ele.csv', parse_dates=['date'], index_col='date')
-
-
# 1. 移动*均数
-
dma = df_rg.vale.r.man()
-
-
# 2. *滑(5%和15%)
-
pd.DtaFame(lowess(dfoig.alu, np.ane(len(d_origale)), fac=0.05)
-
-
# 绘图
-
fig, axes = plt.ubplos(4,1, figsiz=(7, 7, sharex=rue, dp=120)
-
df_ori['aue'].pot(ax=axes0], color='k')
-
-
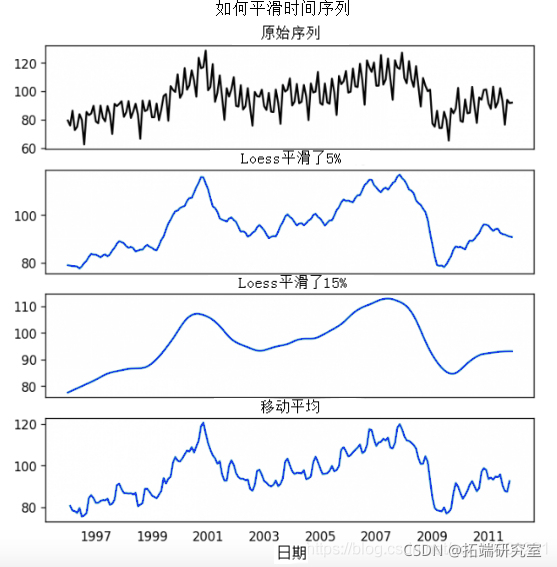
*滑化时间序列
如何使用格兰杰因果测试来了解一个时间序列是否有助于预测另一个时间序列?
格兰杰因果检验是用来确定一个时间序列是否有助于预测另一个时间序列的。
格兰杰因果关系测试是如何工作的?
它是基于这样的想法:如果X导致Y,那么基于Y的前值和X的前值对Y的预测应该优于仅基于Y的前值的预测。
因此,理解格兰杰因果关系不应该被用来测试Y的滞后期是否导致Y。
无效假设是:第二列中的序列不会导致第一列中的序列的格兰杰。如果P值小于显著性水*(0.05),那么你就拒绝无效假设,并得出结论:上述X的滞后期确实是有用的。
第二个参数maxlag说的是在测试中应该包括多少个Y的滞后期。
-
df = pd.rea_csv('a10.csv', parse_dates=['date'])
-
df['moth'] = df.date.dt.nth
-
gragecaslitess(df[['alue', 'moh']], maxag2)

在上述情况下,所有检验的P值都是零。因此,"月 "数据确实可以用来预测航空乘客。

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析