原文链接:http://tecdat.cn/?p=23534
作者:ShiChao Wu
项目挑战
肝脏病在早期可能没有任何症状,不容易被察觉,或者症状是模糊的。肝脏病的症状和肝脏病的类型和程度高度相关,肝脏病的一般是通过肝功能测试诊断。在常见的肝功能测试诊断中,一般主要包含三大类指标:血清酶、胆红素和血清蛋白。其中,血清酶中的医学指标主要包括丙氨酸氨基转移酶、天冬氨酸氨基转移酶和碱性磷酸酶等,当肝脏细胞被破坏时,酶会被大量释放到血液中,引起指标上升。胆红素指标包括总胆红素、直接胆红素和间接胆红素等,它们反映了胆红素的代谢情况,当肝细胞变性坏死,胆红素代谢出现障碍时,胆红素指标会升高。血清蛋白指标反映了肝脏的合成功能,其包含白蛋白、球蛋白、总蛋白等,可用于检测慢性肝损伤、机体免疫等情况。早期的诊断可以提高肝脏病患者的存活率,而通过血液中酶、胆红素、血清蛋白的水平来诊断肝脏病是一个非常重要的手段。
解决方案
数据来源准备
实验数据集(Indian Liver Patient Datset,,ILPD)来自美国加州大学的一个统计学习网站UCI。ILPD由三个印度教授收集自印度安得拉邦的东北部,数据集包含416位肝病患者记录和167位非肝病患者记录,包含了441位男性患者记录和142位女性患者记录,任何年龄超过89岁的患者都被列为90岁。
描述性统计分析
基于患者的生理指标和医疗检测指标来对患者的情况进行描述性分析(以下的图中1均代表患病,2均代表不患病):
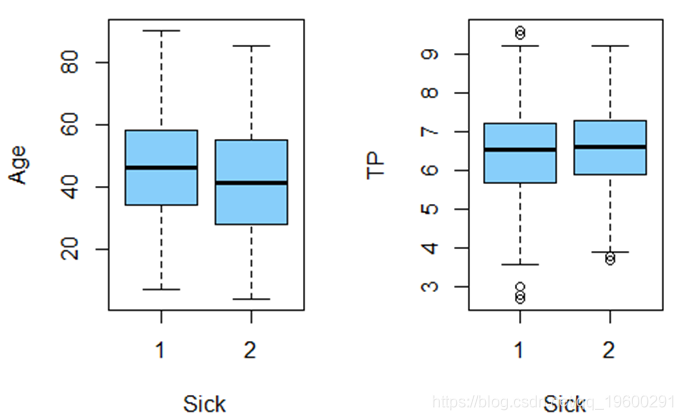
从图1中可以看出患有肝脏病的人群年龄的平均水平(中位数)要比不患肝脏病的大,可能由于年龄大的人群的生活、工作压力较大,就容易患肝脏病。患有肝脏病的人群血液中的总蛋白含量与不患肝脏病的人群血液中总蛋白含量平均水平(中位数)差异并不明显,可能在判断某人是否患有心脏病时血液中总蛋白这个指标占的比重较小。

从图2可以看出患有肝脏病的人群血液中白蛋白含量的平均水平(中位数)明显低于不患肝脏病的人群血液中白蛋白含量,血液中白蛋白的含量偏低可能对肝脏病的影响较大。血液中白蛋白与球蛋白的的比率表明含有肝脏病的人群的平均水平(中位数)明显低于不患肝脏病的人群,可能在判断某人是否患有肝脏病白蛋白与球蛋白这个指标比较重要。
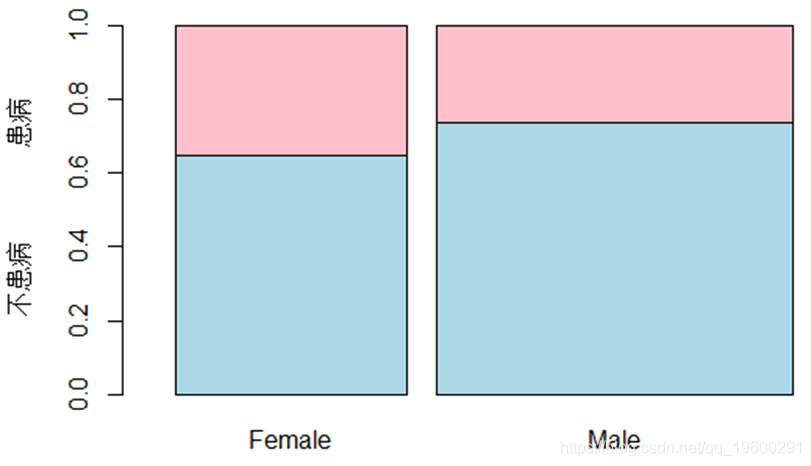
从图3可以看出,患病人群的男性人数约为女性人数的三倍,这与现实中患有肝脏病人群的分布稍有差异,出现这种现象的原因是采集数据时男性数据占有多部分,女性采集的数据较少;其中男性中患有肝脏病与未患有肝脏病的比率约为3:7,女性中患肝病人数与未患肝病人数的比例约为4:6。性别对患病可能会有一定的影响。
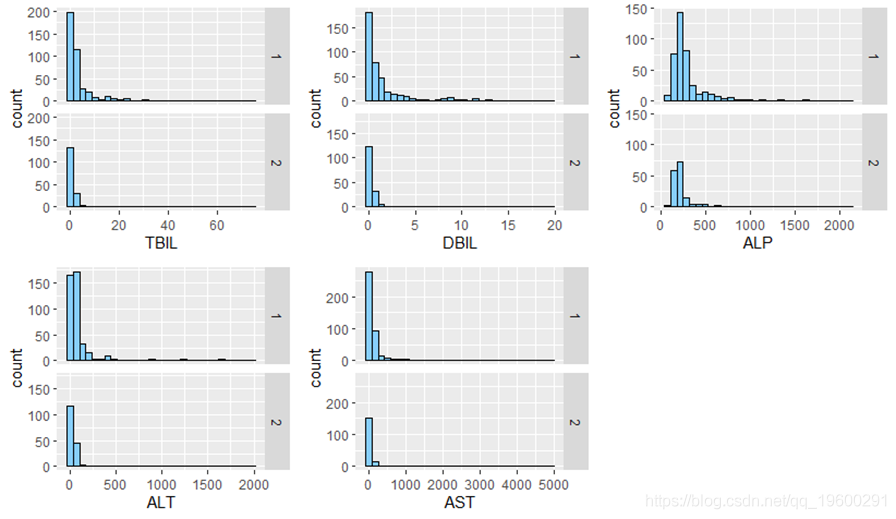
从图4观察到患病人群的总胆红素(TBIL),直接胆红素(DBIL),碱性磷酸酶(ALP),谷丙转氨酶(ALT),天冬氨酸氨基转移酶(AST)5个特征呈现明显的右偏分布,可能是由于患有肝脏病的人群的医疗指标会高于常人。
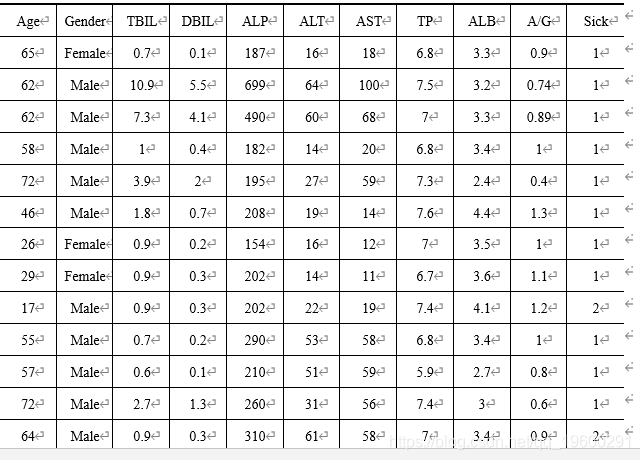
部分实验数据
R语言建模
逻辑回归
二项逻辑回归模型(binomial logistic regression model)是一种基于逻辑斯谛分布(logistic distribution)的二分类模型,是一种有监督的机器学习方法。基本思想是比较条件概率![]() 的大小,概率值大于0.5的属于正类,概率值小于0.5的属于负类。
的大小,概率值大于0.5的属于正类,概率值小于0.5的属于负类。
随机森林
用随机的方式建立一个森林,森林由很多决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
决策树
决策树(decision tree)是可以用于分类和回归的一种有监督机器学习方法,决策树的模型以树形结构分布,可以在分类过程中对实例进行特征选择实现分类。分类决策树模型描述的是对实例进行分类的树状结构模型,决策树的结构为节点(node)和有向边(directed edge),节点又可分为叶节点(leaf node)和内部节点(internal node)。叶节点表示类,内部节点表示特征。
支持向量回归(SVR)
支持向量机(support vector machines,SVM)是Vapink在1979年发现的,1995年Vapink建议用支持向量机来进行回归和分类。支持向量机是一种有监督的机器学习算法,它的目的是找到一个最优的超平面,然后将数据划分为不同的类别。
项目结果
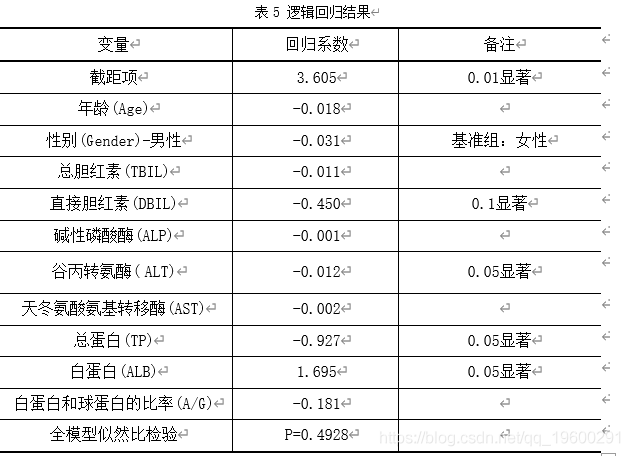

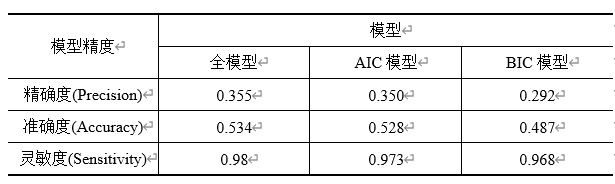
从模型结果可以看到,全模型似然比为0.4928,很多指标并不显著,所以考虑利用AIC和BIC做子集选择,使得到的模型更加准确,更有说服力。

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
7.R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
9.R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
关于作者
ShiChao Wu 是拓端研究室(TRL)的研究员。
他作为一名211学校统计系硕士,十分明白数据分析在现代化的生产和运维中的重要性。在大数据的时代,高新技术企业的技术骨干越来越年轻化,数据分析师的地位也越来越重要。