原文链接:http://tecdat.cn/?p=23242
原文出处:拓端数据部落公众号
简介
标准化发病率(SIR)或死亡率(SMR)是观察病例和期望病例的比率。观察到的病例是队列中病例的绝对数量。期望病例是通过将队列中的人-年数与参考人口比率相乘得出的。该比率应按混杂因素进行分层或调整。通常这些因素是年龄组、性别、日历期和可能的癌症类型或其他混杂变量。也可以使用社会经济地位或地区变量。
在参考人口中,第j层的期望比率是λj=dj/nj,其中dj是观察到的病例,nj是观察到的人年。现在SIR可以写成一个比率
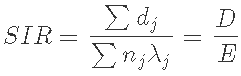
标化发病比(SIR)=实际观察发病人数/期望发病人数
或 标化死亡比(SMR)=实际观察死亡人数/期望死亡人数
其中D是队列人群中的观察病例,E是期望数。单变量置信区间是基于泊松分布的精确值,P值的公式为
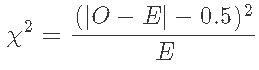
建模的SIR是一个泊松回归模型,有对数连接和队列人-年作为偏移。
在泊松模型的SIR中可以用似然比检验来检验SIR的同质性。
同样的工作流程适用于标准化的死亡率。
样条曲线
可以为时间变量(如年龄组)拟合一个连续的样条函数。曲线的想法是平滑SMR估计值,并从曲线图中进行推断。这需要预定义的结点/节点,用于拟合样条曲线。选择结的数量和结的位置是一个非常主观的问题,有三个选项可以将样条曲线结传递给函数。
在不同的结点设置之间进行尝试是很好的做法,以获得真实的样条曲线估计。过度拟合可能会在估计中造成假象,欠拟合可能会使模式变得平滑。
样条曲线变量应该是尽可能连续的,例如从18到100个时间点。但是,当把时间分割成太窄的区间时,在期望或人口比率值中可能会出现随机的变化。因此,也可以为年龄或时期做两个变量:第一个是用于标准化的较宽区间,第二个是用于拼接的窄区间。
结点
有三个选项可用于为样条曲线指定结点。
-
每个样条曲线变量的结数的向量。节点数量包括边界节点,因此最小的节点数量是2,这是一个对数线性关联。节点是利用观察到的样例的量纲自动放置的。
-
预定义结点的向量列表。矢量的数量需要与样条曲线变量的长度相匹配。每个向量至少要有边界结点的最小值和最大值。
-
NULL将根据AIC自动找到最佳结点数量。节点是根据观察到的案例的数量级来放置的。这通常是一个开始拟合过程的合理初始值。
结的数量和结的位置可以在输出中找到。
SMR
死亡率、外部队列和数据
估计一个女性直肠癌患者队列的SMR。每个年龄段、时期和性别的死亡率都可以在数据集中找到。
-
-
SMR( status, birthdate, exitdate, entrydate , rate = 'haz', print ='fot')

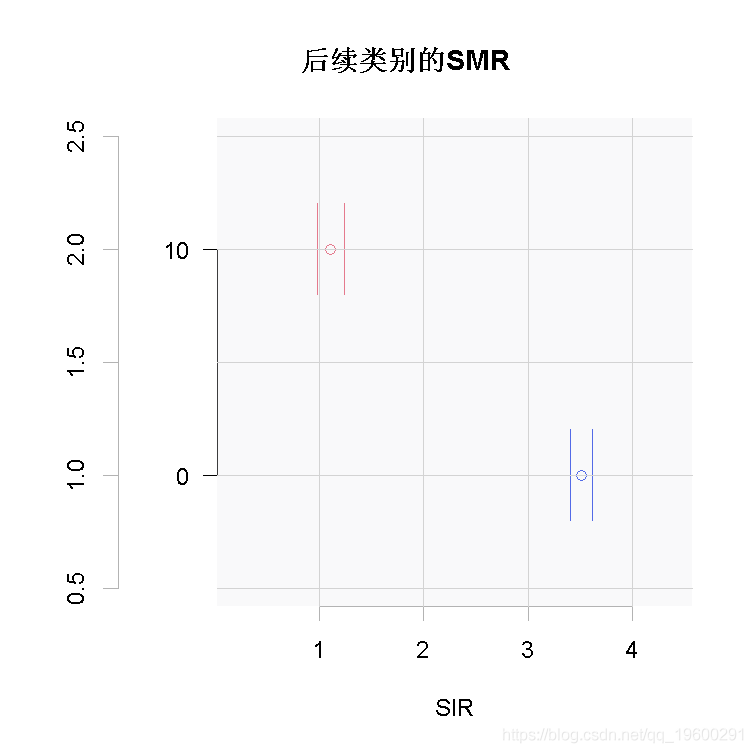
其他原因的SMR在两个随访区间都是1。此外,P值表明SMR估计值之间没有异质性(P=0.735)。
总死亡率可以通过修改状态参数来估计。现在我们要计算所有的死亡,即状态为1或2。
smr( status = status %in% 1:2)
现在随访区间的估计值似乎有很大的不同,P=0。绘制SMR。
plot(se)
样条曲线
让我们用两个不同的选项来拟合后续时间和年龄组的样条:样条在不同的模型和同一模型中被拟合,splines。
-
smrspline(data, rate = 'haz',
-
spline )
-
-
plot(sf)
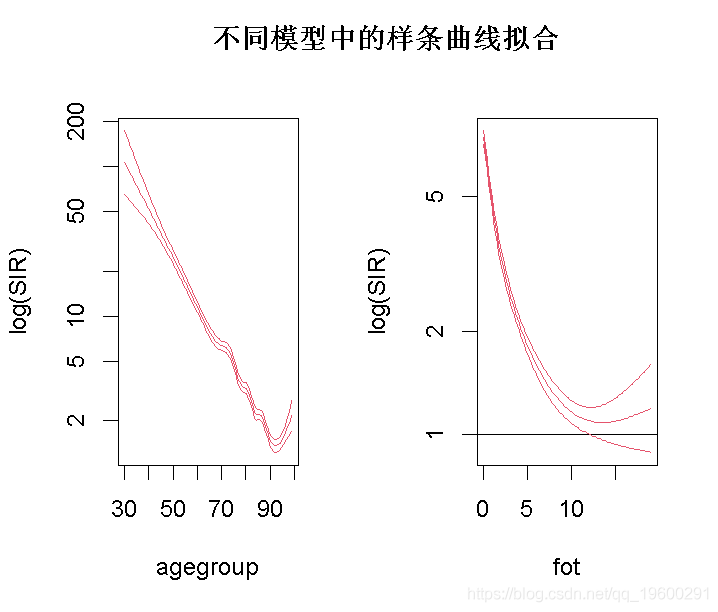
plot(st, col=4, log=TRUE)
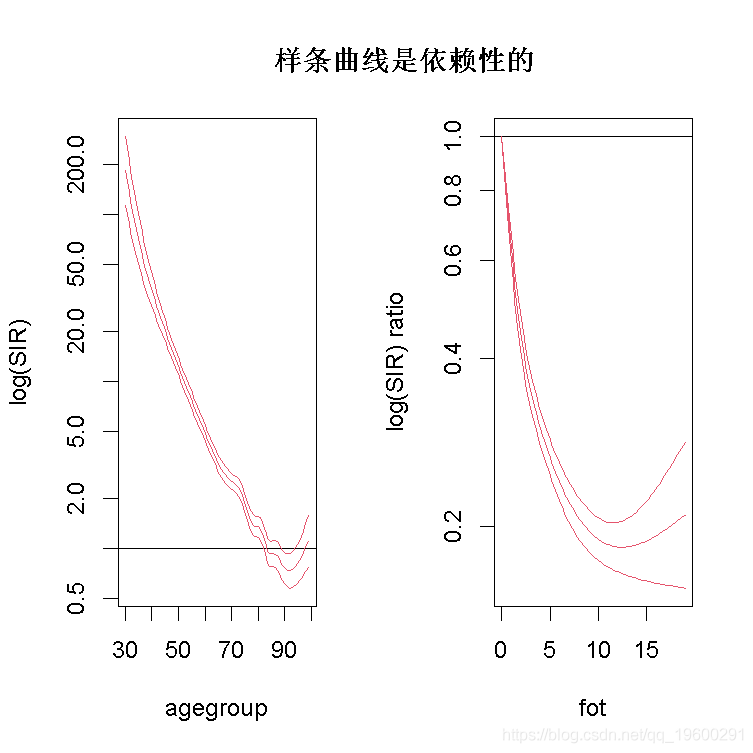
在从属样条曲线中,fot是以零时间为参考点的比率。参考点可以被改变。这里假设每个随访时间的年龄组情况是相同的。从0到10年的随访,SMR是0.2倍。
也可以对样条曲线进行分层。例如,我们把死亡时间分成两个时间段,并测试年龄组的样条是否相等。
year. <- ifelse(year < 2002, 1, 2)
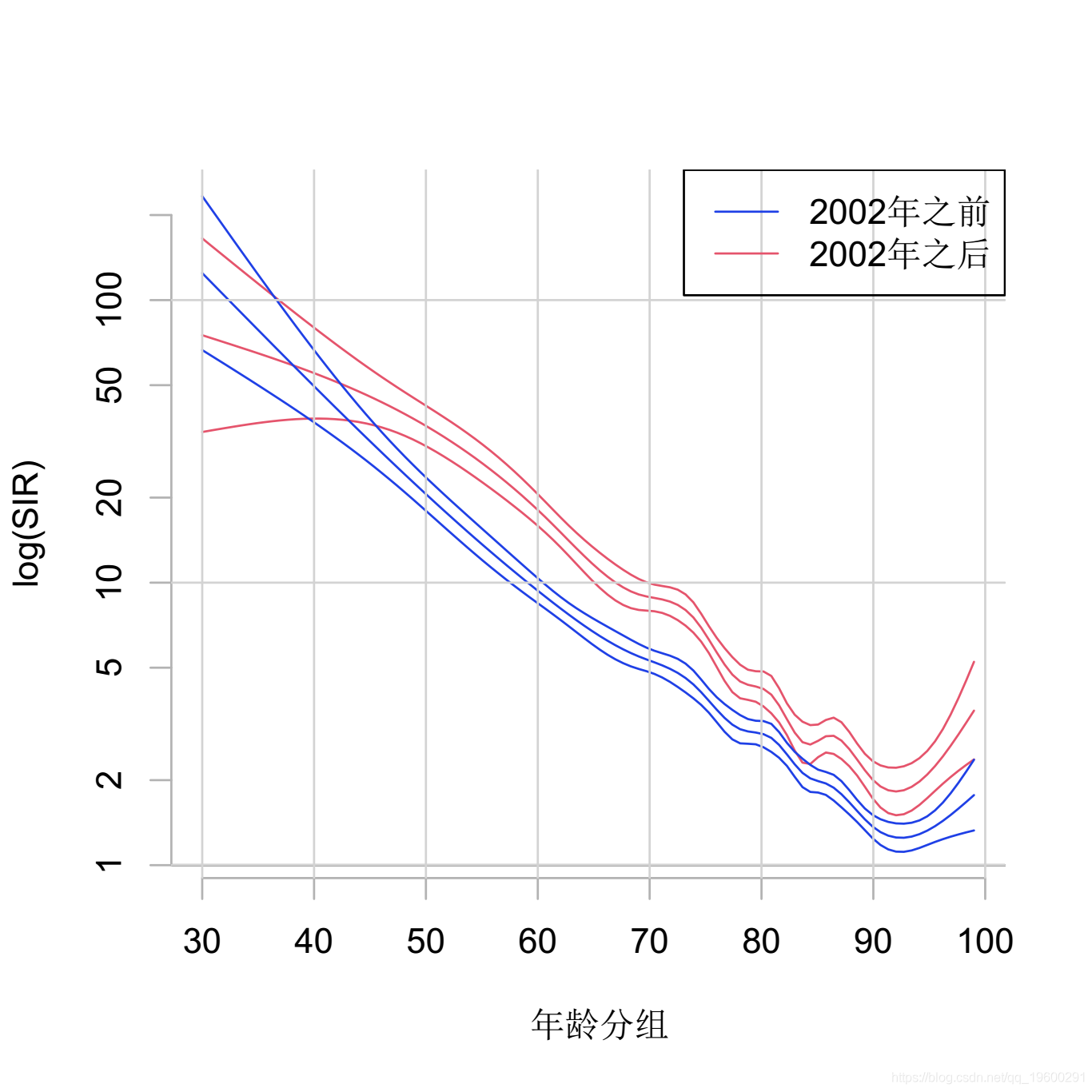
对于2002年以前的类别,50岁以后的SMR似乎更高。另外,P值(<0.0001)表明,2002年之前和之后的年龄组趋势存在差异。

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现