原文链接:http://tecdat.cn/?p=22945
原文出处:拓端数据部落公众号
动态时间规整(DTW,Dynamic time warping,动态时间归整/规整/弯曲)是一种衡量两个序列之间最佳排列的算法。线性序列数据如时间序列、音频、视频都可以用这种方法进行分析。DTW通过局部拉伸和压缩,找出两个数字序列数据的最佳匹配,同时也可以计算这些序列之间的距离。
DTW是干什么的?
动态时间规整算法,故名思议,就是把两个代表同一个类型的事物的不同长度序列进行时间上的“对齐”。比如DTW最常用的地方,语音识别中,同一个字母,由不同人发音,长短肯定不一样,把声音记录下来以后,它的信号肯定是很相似的,只是在时间上不太对整齐而已。所以我们需要用一个函数拉长或者缩短其中一个信号,使得它们之间的误差达到最小。
DTW怎么计算?
因此,动态时间规整要解决的问题就是:找到一条最优的规整路径 W = {varpi _1},{varpi _2}...{varpi _k} W=ϖ1,ϖ2...ϖk,其中 {w_k} = (i,j) wk=(i,j),即认为时间序列1的第i个点和时间序列2的第j个点是类似的。全部类似点的距离之和做为规整路径距离,用规整路径距离来衡量两个时间序列的类似性。规整路径距离越小,类似度越高。
下面我们来总结一下DTW动态时间规整算法的简单的步骤:
1. 首先肯定是已知两个或者多个序列,但是都是两个两个的比较,所以我们假设有两个序列A={a1,a2,a3,...,am} B={b1,b2,b3,....,bn},维度m>n
2. 然后用欧式距离计算出每序列的每两点之间的距离,D(ai,bj) 其中1≤i≤m,1≤j≤n
画出下表:
3. 接下来就是根据上图将最短路径找出来。从D(a1,a2)沿着某条路径到达D(am,bn)。找路径满足:假如当前节点是D(ai,bj),那么下一个节点必须是在D(i+1,j),D(i,j+1),D(i+1,j+1)之间选择,并且路径必须是最短的。计算的时候是按照动态规划的思想计算,也就是说在计算到达第(i,j)个节点的最短路径时候,考虑的是左上角也即第(i-1,j)、(i-1,j-1)、(i,j-1)这三个点到(i,j)的最短距离。
4. 接下来从最终的最短距离往回找到那条最佳的输出路径, 从D(a1,b1)到D(am,bn)。他们的总和就是就是所需要的DTW距离
【注】如果不回溯路径,直接在第3步的时候将左上角三个节点到下一个节点最短的点作为最优路径节点,就是贪婪算法了。DTW是先计算起点到终点的最小值,然后从这个最小值回溯回去看看这个最小值都经过了哪些节点。
R语言实现
在这篇文章中,我们将学习如何找到两个数字序列数据的排列。
创建序列数据
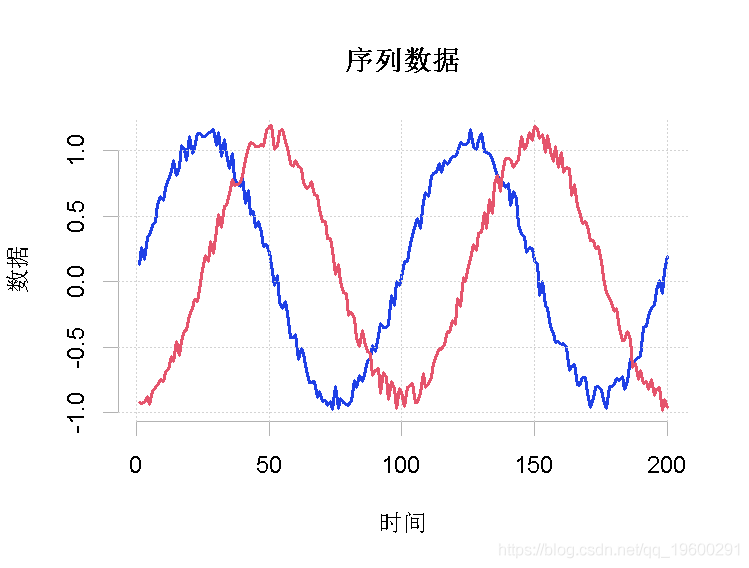
首先,我们生成序列数据,并在一个图中将其可视化。
-
-
plot(a, type = "l")
-
lines(b, col = "blue")
计算规整方式
dtw()函数计算出一个最佳规整方式。
align(a, b)
返回以下项目。你可以参考str()函数来了解更多信息。
现在,我们可以绘制组合。
用双向的方法作图
动态时间规整结果的绘图:点比较
显示查询和参考时间序列以及它们的排列方式,进行可视化检查。
Plot(align)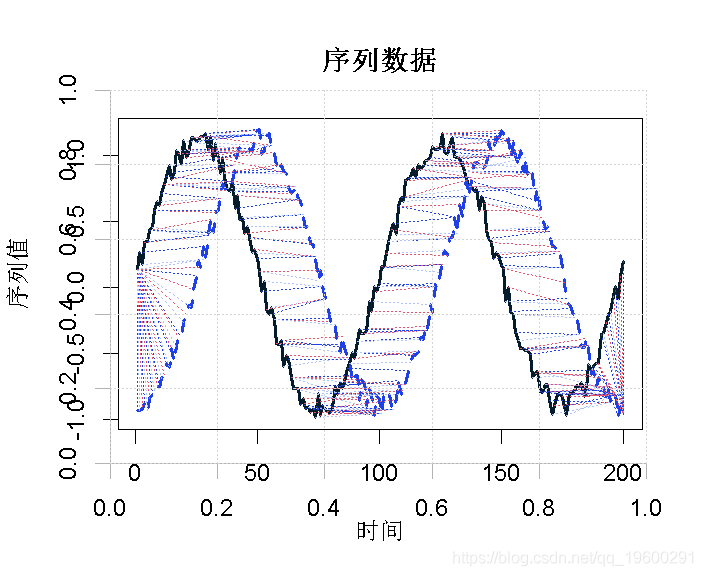
用密度作图
显示叠加了规整路径的累积成本密度 。
该图是基于累积成本矩阵的。它将最优路径显示为全局成本密度图中的 "山脊"。
PlotDensity(align)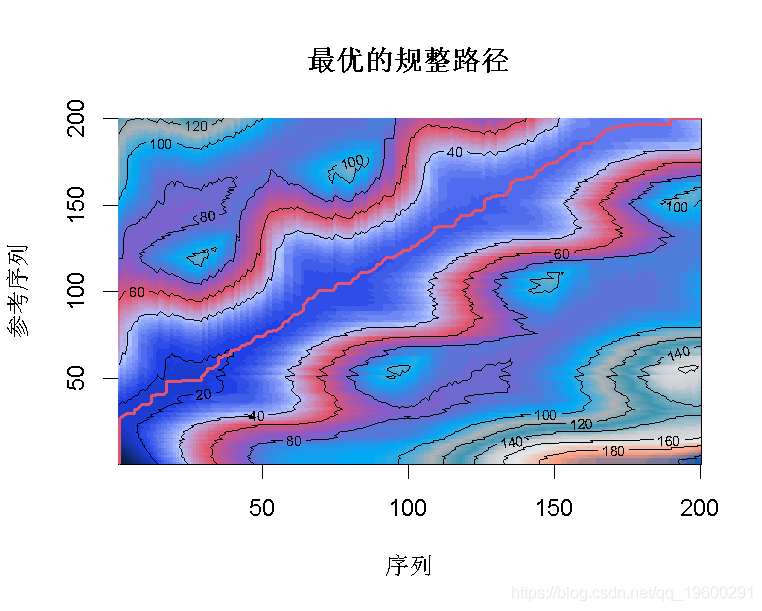
小结
总而言之, DTW是一种非常有用的计算序列最小距离的方法, 不论是在语音序列匹配, 股市交易曲线匹配, 还是DNA碱基序列匹配等等场景, 都有其大展身手的地方. 它的最大特点是在匹配时允许时间上的伸缩, 因此可以更好的在一堆序列集合中找到最佳匹配的序列.
- Eamonn Keogh, Chotirat Ann Ratanamahatana, Exact indexing of dynamic time warping, Knowledge and Information Systems, 2005.

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析