在本文中,我们将看到如何创建语言翻译模型,这也是神经机器翻译的非常著名的应用。我们将使用seq2seq体系结构通过Python的Keras库创建我们的语言翻译模型。
假定您对循环神经网络(尤其是LSTM)有很好的了解。本文中的代码是使用Keras库用Python编写的。
库和配置设置
首先导入所需的库:
import os, sys
from keras.models import Model
from keras.layers import Input, LSTM, GRU, Dense, Embedding
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
执行以下脚本来设置不同参数的值:
BATCH_SIZE = 64
EPOCHS = 20
LSTM_NODES =256
NUM_SENTENCES = 20000
MAX_SENTENCE_LENGTH = 50
MAX_NUM_WORDS = 20000
EMBEDDING_SIZE = 100
数据集
我们将在本文中开发的语言翻译模型会将英语句子翻译成法语。要开发这样的模型,我们需要一个包含英语句子及其法语翻译的数据集。 在每一行上,文本文件包含一个英语句子及其法语翻译,并用制表符分隔。文件的前20行fra.txt如下所示:
Go. Va !
Hi. Salut !
Hi. Salut.
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
Fire! Au feu !
Help! À l'aide !
Jump. Saute.
Stop! Ça suffit !
Stop! Stop !
Stop! Arrête-toi !
Wait! Attends !
Wait! Attendez !
Go on. Poursuis.
Go on. Continuez.
Go on. Poursuivez.
Hello! Bonjour !
Hello! Salut !
该模型包含超过170,000条记录,但是我们将仅使用前20,000条记录来训练我们的模型。您可以根据需要使用更多记录。
数据预处理
神经机器翻译模型通常基于seq2seq架构。seq2seq体系结构是一种编码器-解码器体系结构,由两个LSTM网络组成:编码器LSTM和解码器LSTM。
在我们的数据集中,我们不需要处理输入,但是,我们需要生成翻译后的句子的两个副本:一个带有句子开始标记,另一个带有句子结束标记。这是执行此操作的脚本:
input_sentences = []
output_sentences = []
output_sentences_inputs = []
count = 0
for line in open(r'/content/drive/My Drive/datasets/fra.txt', encoding="utf-8"):
count += 1
if count > NUM_SENTENCES:
break
if ' ' not in line:
continue
input_sentence, output = line.rstrip().split(' ')
output_sentence = output + ' <eos>'
output_sentence_input = '<sos> ' + output
input_sentences.append(input_sentence)
output_sentences.append(output_sentence)
output_sentences_inputs.append(output_sentence_input)
print("num samples input:", len(input_sentences))
print("num samples output:", len(output_sentences))
print("num samples output input:", len(output_sentences_inputs))
注意:您可能需要更改fra.txt计算机上文件的文件路径,才能起作用。
最后,输出中将显示三个列表中的样本数量:
num samples input: 20000
num samples output: 20000
num samples output input: 20000
现在让我们来随机打印一个句子从input_sentences[],output_sentences[]和output_sentences_inputs[]列表:
print(input_sentences[172])
print(output_sentences[172])
print(output_sentences_inputs[172])
这是输出:
I'm ill.
Je suis malade. <eos>
<sos> Je suis malade.
您可以看到原始句子,即I'm ill;在输出中对应的翻译,即Je suis malade. <eos>。
标记化和填充
下一步是标记原始句子和翻译后的句子,并对大于或小于特定长度的句子应用填充,在输入的情况下,这将是最长输入句子的长度。对于输出,这将是输出中最长句子的长度。
对于标记化,可以使用库中的Tokenizer类keras.preprocessing.text。本tokenizer类执行两个任务:
- 它将句子分为相应的单词列表
- 然后将单词转换为整数
这是非常重要的,因为深度学习和机器学习算法可以处理数字。以下脚本用于标记输入句子:
除了标记化和整数转换外,该类的word_index属性还Tokenizer返回一个单词索引字典,其中单词是键,而相应的整数是值。上面的脚本还输出字典中唯一词的数量和输入中最长句子的长度:
Total unique words in the input: 3523
Length of longest sentence in input: 6
同样,输出语句也可以用以下所示的相同方式进行标记:
这是输出:
Total unique words in the output: 9561
Length of longest sentence in the output: 13
通过比较输入和输出中唯一词的数量,可以得出结论,与翻译后的法语句子相比,英语句子通常较短,平均包含较少的单词。
接下来,我们需要填充输入。对输入和输出进行填充的原因是文本句子的长度可以变化,但是LSTM(我们将要训练模型的算法)期望输入实例具有相同的长度。因此,我们需要将句子转换为固定长度的向量。一种方法是通过填充。
在填充中,为句子定义了一定的长度。在我们的情况下,输入和输出中最长句子的长度将分别用于填充输入和输出句子。输入中最长的句子包含6个单词。对于少于6个单词的句子,将在空索引中添加零。以下脚本将填充应用于输入句子。
上面的脚本显示了填充的输入句子的形状。还打印了索引为172的句子的填充整数序列。这是输出:
encoder_input_sequences.shape: (20000, 6)
encoder_input_sequences[172]: [ 0 0 0 0 6 539]
由于输入中有20,000个句子,并且每个输入句子的长度为6,所以输入的形状现在为(20000,6)。如果查看输入句子索引172处句子的整数序列,可以看到存在三个零,后跟值为6和539。您可能还记得索引172处的原始句子是I'm ill。标记生成器分割的句子翻译成两个词I'm和ill,将它们转换为整数,然后通过在输入列表的索引172在用于句子对应的整数序列的开始添加三个零施加预填充。
要验证的整数值i'm和ill是6和539分别可以传递话到word2index_inputs词典,如下图所示:
print(word2idx_inputs["i'm"])
print(word2idx_inputs["ill"])
输出:
6
539
以相同的方式,解码器输出和解码器输入的填充如下:
print("decoder_input_sequences.shape:", decoder_input_sequences.shape)
print("decoder_input_sequences[172]:", decoder_input_sequences[172])
输出:
decoder_input_sequences.shape: (20000, 13)
decoder_input_sequences[172]: [ 2 3 6 188 0 0 0 0 0 0 0 0 0]
解码器输入的索引172处的句子为<sos> je suis malade.。如果从word2idx_outputs字典中打印相应的整数,则应该在控制台上看到2、3、6和188,如下所示:
print(word2idx_outputs["<sos>"])
print(word2idx_outputs["je"])
print(word2idx_outputs["suis"])
print(word2idx_outputs["malade."])
输出:
2
3
6
188
进一步重要的是要提到,在解码器的情况下,应用后填充,这意味着在句子的末尾添加了零。在编码器中,开始时填充零。这种方法背后的原因是,编码器输出基于句子末尾出现的单词,因此原始单词保留在句子末尾,并且在开头填充零。另一方面,在解码器的情况下,处理从句子的开头开始,因此对解码器的输入和输出执行后填充。
词嵌入
由于我们使用的是深度学习模型,并且深度学习模型使用数字,因此我们需要将单词转换为相应的数字矢量表示形式。但是我们已经将单词转换为整数。
在本文中,对于英文句子(即输入),我们将使用GloVe词嵌入。对于输出中的法语翻译句子,我们将使用自定义单词嵌入。
让我们首先为输入创建单词嵌入。为此,我们需要将GloVe字向量加载到内存中。然后,我们将创建一个字典,其中单词是键,而相应的向量是值,如下所示:
回想一下,我们在输入中包含3523个唯一词。我们将创建一个矩阵,其中行号将表示单词的整数值,而列将对应于单词的尺寸。此矩阵将包含输入句子中单词的单词嵌入。
num_words = min(MAX_NUM_WORDS, len(word2idx_inputs) + 1)
embedding_matrix = zeros((num_words, EMBEDDING_SIZE))
for word, index in word2idx_inputs.items():
embedding_vector = embeddings_dictionary.get(word)
if embedding_vector is not None:
embedding_matrix[index] = embedding_vector
首先,ill使用GloVe词嵌入词典为该词打印词嵌入。
print(embeddings_dictionary["ill"])
输出:
[ 0.12648 0.1366 0.22192 -0.025204 -0.7197 0.66147
0.48509 0.057223 0.13829 -0.26375 -0.23647 0.74349
0.46737 -0.462 0.20031 -0.26302 0.093948 -0.61756
-0.28213 0.1353 0.28213 0.21813 0.16418 0.22547
-0.98945 0.29624 -0.62476 -0.29535 0.21534 0.92274
0.38388 0.55744 -0.14628 -0.15674 -0.51941 0.25629
-0.0079678 0.12998 -0.029192 0.20868 -0.55127 0.075353
0.44746 -0.71046 0.75562 0.010378 0.095229 0.16673
0.22073 -0.46562 -0.10199 -0.80386 0.45162 0.45183
0.19869 -1.6571 0.7584 -0.40298 0.82426 -0.386
0.0039546 0.61318 0.02701 -0.3308 -0.095652 -0.082164
0.7858 0.13394 -0.32715 -0.31371 -0.20247 -0.73001
-0.49343 0.56445 0.61038 0.36777 -0.070182 0.44859
-0.61774 -0.18849 0.65592 0.44797 -0.10469 0.62512
-1.9474 -0.60622 0.073874 0.50013 -1.1278 -0.42066
-0.37322 -0.50538 0.59171 0.46534 -0.42482 0.83265
0.081548 -0.44147 -0.084311 -1.2304 ]
在上一节中,我们看到了单词的整数表示形式为ill539。现在让我们检查单词嵌入矩阵的第539个索引。
print(embedding_matrix[539])
输出:
[ 0.12648 0.1366 0.22192 -0.025204 -0.7197 0.66147
0.48509 0.057223 0.13829 -0.26375 -0.23647 0.74349
0.46737 -0.462 0.20031 -0.26302 0.093948 -0.61756
-0.28213 0.1353 0.28213 0.21813 0.16418 0.22547
-0.98945 0.29624 -0.62476 -0.29535 0.21534 0.92274
0.38388 0.55744 -0.14628 -0.15674 -0.51941 0.25629
-0.0079678 0.12998 -0.029192 0.20868 -0.55127 0.075353
0.44746 -0.71046 0.75562 0.010378 0.095229 0.16673
0.22073 -0.46562 -0.10199 -0.80386 0.45162 0.45183
0.19869 -1.6571 0.7584 -0.40298 0.82426 -0.386
0.0039546 0.61318 0.02701 -0.3308 -0.095652 -0.082164
0.7858 0.13394 -0.32715 -0.31371 -0.20247 -0.73001
-0.49343 0.56445 0.61038 0.36777 -0.070182 0.44859
-0.61774 -0.18849 0.65592 0.44797 -0.10469 0.62512
-1.9474 -0.60622 0.073874 0.50013 -1.1278 -0.42066
-0.37322 -0.50538 0.59171 0.46534 -0.42482 0.83265
0.081548 -0.44147 -0.084311 -1.2304 ]
可以看到,嵌入矩阵中第539行的值类似于GloVe ill词典中单词的向量表示,这证实了嵌入矩阵中的行代表了GloVe单词嵌入词典中的相应单词嵌入。这个词嵌入矩阵将用于为我们的LSTM模型创建嵌入层。
以下脚本为输入创建嵌入层:
创建模型
现在是时候开发我们的模型了。我们需要做的第一件事是定义输出,因为我们知道输出将是一个单词序列。回想一下,输出中的唯一单词总数为9562。因此,输出中的每个单词可以是9562个单词中的任何一个。输出句子的长度为13。对于每个输入句子,我们需要一个对应的输出句子。因此,输出的最终形状将是:
以下脚本创建空的输出数组:decoder_targets_one_hot = np.zeros((
len(input_sentences),
max_out_len,
num_words_output
),
dtype='float32'
)
以下脚本打印解码器的形状:
decoder_targets_one_hot.shape
输出:
(20000, 13, 9562)
为了进行预测,模型的最后一层将是一个密集层,因此我们需要以一热编码矢量的形式进行输出,因为我们将在密集层使用softmax激活函数。要创建这样的单编码输出,下一步是将1分配给与该单词的整数表示形式对应的列号。例如,的整数表示形式<sos> je suis malade是[ 2 3 6 188 0 0 0 0 0 0 0 ]。在decoder_targets_one_hot输出数组的第一行的第二列中,将插入1。同样,在第二行的第三个索引处,将插入另一个1,依此类推。
看下面的脚本:
for i, d in enumerate(decoder_output_sequences):
for t, word in enumerate(d):
decoder_targets_one_hot[i, t, word] = 1
接下来,我们需要创建编码器和解码器。编码器的输入将是英文句子,输出将是LSTM的隐藏状态和单元状态。
以下脚本定义了编码器:
下一步是定义解码器。解码器将有两个输入:编码器和输入语句的隐藏状态和单元状态,它们实际上将是输出语句,<sos>并在开头添加了令牌。
以下脚本创建解码器LSTM:
最后,来自解码器LSTM的输出将通过密集层以预测解码器输出,如下所示:
decoder_dense = Dense(num_words_output, activation='softmax')
下一步是编译模型:model = Model([encoder_inputs_placeholder,
decoder_inputs_placeholder], decoder_outputs)
让我们绘制模型以查看:
plot_model(model, to_file='model_plot4a.png', show_shapes=True, show_layer_names=True)
输出:
![]()
从输出中,可以看到我们有两种输入。input_1是编码器的输入占位符,它被嵌入并通过lstm_1层,该层基本上是编码器LSTM。该lstm_1层有三个输出:输出,隐藏层和单元状态。但是,只有单元状态和隐藏状态才传递给解码器。
这里的lstm_2层是解码器LSTM。该input_2包含输出句子<sos>令牌在开始追加。在input_2还通过一个嵌入层传递,并且被用作输入到解码器LSTM, lstm_2。最后,来自解码器LSTM的输出将通过密集层进行预测。
下一步是使用以下fit()方法训练模型:
r = model.fit(
...
)
该模型经过18,000条记录的训练,并针对其余2,000条记录进行了测试。 经过20个时间段后,我得到了90.99%的训练精度和79.11%的验证精度,这表明该模型是过度拟合的。
修改预测模型
在训练时,我们知道序列中所有输出字的实际输入解码器。训练期间发生的情况的示例如下。假设我们有一句话i'm ill。句子翻译如下:
// Inputs on the left of Encoder/Decoder, outputs on the right.
Step 1:
I'm ill -> Encoder -> enc(h1,c1)
enc(h1,c1) + <sos> -> Decoder -> je + dec(h1,c1)
step 2:
enc(h1,c1) + je -> Decoder -> suis + dec(h2,c2)
step 3:
enc(h2,c2) + suis -> Decoder -> malade. + dec(h3,c3)
step 3:
enc(h3,c3) + malade. -> Decoder -> <eos> + dec(h4,c4)
您可以看到解码器的输入和解码器的输出是已知的,并且基于这些输入和输出对模型进行了训练。
但是,在预测期间,将根据前一个单词预测下一个单词,而该单词又会在前一个时间步长中进行预测。现在,您将了解<sos>和<eos>令牌的用途。在进行实际预测时,无法获得完整的输出序列,实际上这是我们必须预测的。在预测期间,<sos>由于所有输出句子均以开头,因此唯一可用的单词是<sos>。
预测期间发生的情况的示例如下。我们将再次翻译句子i'm ill:
// Inputs on the left of Encoder/Decoder, outputs on the right.
Step 1:
I'm ill -> Encoder -> enc(h1,c1)
enc(h1,c1) + <sos> -> Decoder -> y1(je) + dec(h1,c1)
step 2:
enc(h1,c1) + y1 -> Decoder -> y2(suis) + dec(h2,c2)
step 3:
enc(h2,c2) + y2 -> Decoder -> y3(malade.) + dec(h3,c3)
step 3:
enc(h3,c3) + y3 -> Decoder -> y4(<eos>) + dec(h4,c4)
可以看到编码器的功能保持不变。原始语言的句子通过编码器和隐藏状态传递,而单元格状态是编码器的输出。
在步骤1中,将编码器的隐藏状态和单元状态以及<sos>用作解码器的输入。解码器预测一个单词y1可能为真或不为真。但是,根据我们的模型,正确预测的概率为0.7911。在步骤2,将来自步骤1的解码器隐藏状态和单元状态与一起y1用作预测的解码器的输入y2。该过程一直持续到<eos>遇到令牌为止。然后,将来自解码器的所有预测输出进行级联以形成最终输出语句。让我们修改模型以实现此逻辑。
编码器型号保持不变:
encoder_model = Model(encoder_inputs_placeholder, encoder_states)
因为现在在每一步我们都需要解码器的隐藏状态和单元状态,所以我们将修改模型以接受隐藏状态和单元状态,如下所示:
decoder_state_input_h = Input(shape=(LSTM_NODES,))
...
现在,在每个时间步长,解码器输入中只有一个字,我们需要按如下所示修改解码器嵌入层:
decoder_inputs_single = Input(shape=(1,))...
接下来,我们需要为解码器输出创建占位符:
decoder_outputs, h, c = decoder_lstm(...)
为了进行预测,解码器的输出将通过密集层:
decoder_states = [h, c]
decoder_outputs = decoder_dense(decoder_outputs)
最后一步是定义更新的解码器模型,如下所示:
decoder_model = Model(
...
)
现在,让我们绘制经过修改的解码器LSTM来进行预测:
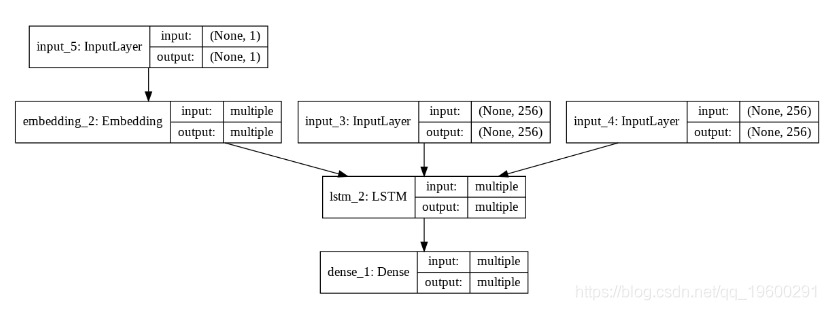
plot_model(decoder_model, to_file='model_plot_dec.png', show_shapes=True, show_layer_names=True)
输出:
![]()
上图中lstm_2是修改后的解码器LSTM。您会看到它接受带有一个单词的句子(如所示)input_5,以及上一个输出(input_3和input_4)的隐藏状态和单元格状态。您可以看到输入句子的形状现在是这样的,(none,1)因为在解码器输入中将只有一个单词。相反,在训练期间,输入句子的形状是(None,6)因为输入包含完整的句子,最大长度为6。
做出预测
在这一步中,您将看到如何使用英语句子作为输入进行预测。
在标记化步骤中,我们将单词转换为整数。解码器的输出也将是整数。但是,我们希望输出是法语中的单词序列。为此,我们需要将整数转换回单词。我们将为输入和输出创建新的字典,其中的键将是整数,而相应的值将是单词。
idx2word_input = {v:k for k, v in word2idx_inputs.items()}
idx2word_target = {v:k for k, v in word2idx_outputs.items()}
接下来,我们将创建一个方法,即translate_sentence()。该方法将接受带有输入填充序列的英语句子(以整数形式),并将返回翻译后的法语句子。看一下translate_sentence()方法:
def translate_sentence(input_seq):
states_value = encoder_model.predict(input_seq)
target_seq = np.zeros((1, 1))
target_seq[0, 0] = word2idx_outputs['<sos>']
eos = word2idx_outputs['<eos>']
output_sentence = []
for _ in range(max_out_len):
...
return ' '.join(output_sentence)
在上面的脚本中,我们将输入序列传递给encoder_model,以预测隐藏状态和单元格状态,这些状态存储在states_value变量中。
接下来,我们定义一个变量target_seq,它是一个1 x 1全零的矩阵。的target_seq变量包含所述第一字给解码器模型,这是<sos>。
之后,将eos初始化变量,该变量存储<eos>令牌的整数值。在下一行中,将output_sentence定义列表,其中将包含预测的翻译。
接下来,我们执行一个for循环。循环的执行周期数for等于输出中最长句子的长度。在循环内部,在第一次迭代中,decoder_model预测器使用编码器的隐藏状态和单元格状态以及输入令牌(即)来预测输出状态,隐藏状态和单元格状态<sos>。预测单词的索引存储在idx变量中。如果预测索引的值等于<eos>令牌,则循环终止。否则,如果预测的索引大于零,则从idx2word词典中检索相应的单词并将其存储在word变量中,然后将其附加到output_sentence列表中。的states_value使用解码器的新隐藏状态和单元状态更新变量,并将预测字的索引存储在target_seq变量中。在下一个循环周期中,更新的隐藏状态和单元状态以及先前预测的单词的索引将用于进行新的预测。循环继续进行,直到达到最大输出序列长度或<eos>遇到令牌为止。
最后,output_sentence使用空格将列表中的单词连接起来,并将结果字符串返回给调用函数。
测试模型
为了测试代码,我们将从input_sentences列表中随机选择一个句子,检索该句子的相应填充序列,并将其传递给该translate_sentence()方法。该方法将返回翻译后的句子,如下所示。
这是测试模型功能的脚本:
print('-')
print('Input:', input_sentences[i])
print('Response:', translation)
这是输出:
-
Input: You're not fired.
Response: vous n'êtes pas viré.
再次执行上述脚本,以查看其他一些翻译成法语的英语句子。我得到以下结果:
-
Input: I'm not a lawyer.
Response: je ne suis pas avocat.
该模型已成功将另一个英语句子翻译为法语。
结论与展望
神经机器翻译是自然语言处理的相当先进的应用,涉及非常复杂的体系结构。
本文介绍了如何通过seq2seq体系结构执行神经机器翻译,该体系结构又基于编码器-解码器模型。编码器是一种LSTM,用于对输入语句进行编码,而解码器则对输入进行解码并生成相应的输出。本文中介绍的技术可以用于创建任何机器翻译模型,只要数据集的格式类似于本文中使用的格式即可。