原文链接:http://tecdat.cn/?p=6322
当我们在回归模型中包含连续变量作为协变量时,重要的是我们使用正确的(或近似正确的)函数形式。例如,对于连续结果Y和连续协变量X,可能是Y的期望值是X和X ^ 2的线性函数,而不是X的线性函数。一种简单但通常有效的方法是简单地查看Y对X的散点图,以直观地评估。
对于我们通常使用逻辑回归建模的二元结果,事情并不那么容易(至少在尝试使用图形方法时)。首先,Y对X的散点图现在完全没有关于Y和X之间关联的形状的信息,因此在逻辑回归模型中应该如何包含X. 为了说明,使用R let模拟一些(X,Y)数据,其中Y遵循逻辑回归,其中X在模型中线性进入:
set.seed(1234)
n < - 1000
x < - rnorm(n)
xb < - -2 + x
pr < - exp(xb)/(1 + exp(xb))
y < - 1 *(runif(n)<pr)现在,如果我们将Y映射到X,我们得到以下结果


由于Y的二元性质,这完全没有关于Y如何依赖X的信息。
LOWESS技术图
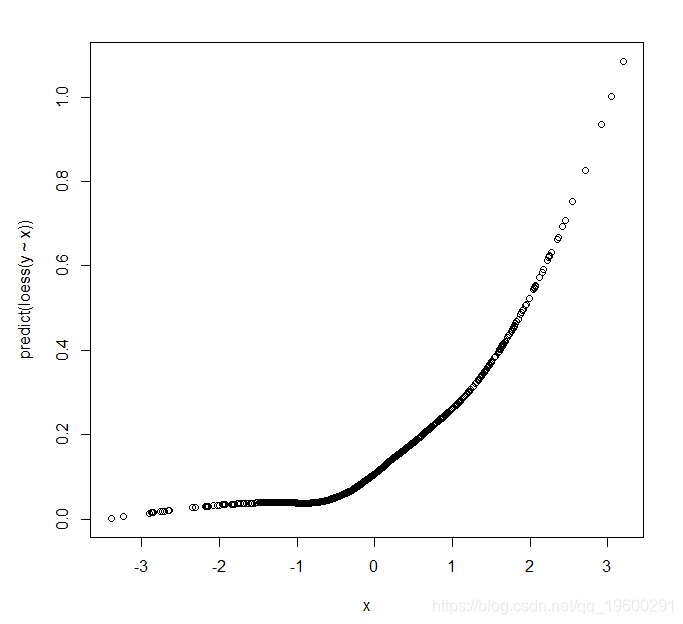
解决这个问题的一种方法是绘制单个(Y,X)值,而不是绘制Y的平均值随X变化的平滑线。最简单的平滑类型是运行平均值,其中在给定值X = x的情况下,该线等于Y值的平均值(可能以某种方式加权)。然后将每个X值的平均值连接起来以得到平滑的线。
所述LOWESS技术是稍微更复杂的版本,其中,代替在X = x的邻域计算Y值的一个(可能加权的)平均值,我们拟合回归线(例如,线性)到数据围绕X = X 。通过这样做,我们假设局部YX关联是线性的,但不假设它是全局线性的。这个优于简单均值的一个优点是我们需要更少的数据来获得Y依赖于X的良好估计。
检查逻辑回归的函数形式
这给出了 该图表明Y的平均值在X中不是线性的,但可能是二次的。我们如何将这与我们从X线性进入的模型生成数据的事实相协调?解释是在逻辑回归中,我们将Y = 1的概率的logit建模为预测变量的函数,而不是概率本身。对于不接近零或一的概率,logit函数实际上非常接近线性,而在概率不接近零或一的数据集中,这不是问题。
![]()
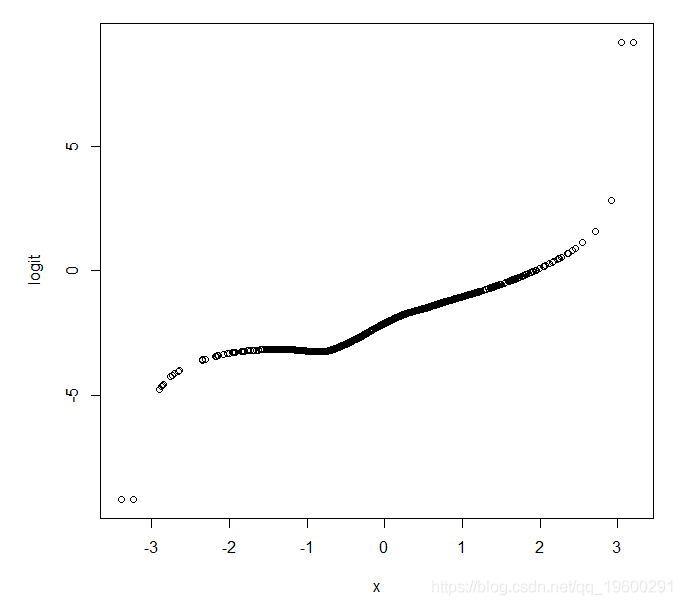
我们可以通过绘制为我们计算的估计概率(Y的平均值)的logit来克服这个问题。在Stata中,lowess命令有一个logit选项,它给出了一个平滑的logit对X的图。在R中我们可以写一个简短的函数来做同样的事情:
logitloess < - function(x,y,s){
logit < - function(pr){
}
if(missing(s)){
locspan < - 0.7
} else {
locspan < - s
}
pi < - pmax(pmin(loessfit,0.9999),0.0001)
logitfitted < - logit(pi)
plot(x,logitfitted,ylab =“logit”)
}为了生成平滑的logit图,我们现在只需用X和Y调用我们的函数:
logitloess(X,Y)
![]()
还需要注意的是,在X值很少的区域,估计的logit会更加不精确。这里我们从正态分布生成X,我们可以从图中看到只有少数X值小于-2或大于+2(正如我们所期望的那样!)。因此,我们不应过分关注X空间的这些区域中的估计logit值。
测试具有二次X效应的情况
作为另一个例子,我们现在重新模拟我们的数据,但是这次指定Y = 1的概率的logit是协变量X的二次函数,而不是线性的:
set.seed(12345)
n < - 1000
x < - rnorm(n)
xb < - -2 + x ^ 2
pr < - exp(xb)/(1 + exp(xb))
y < - 1 *(runif(n)<pr)
logitloess(X,Y)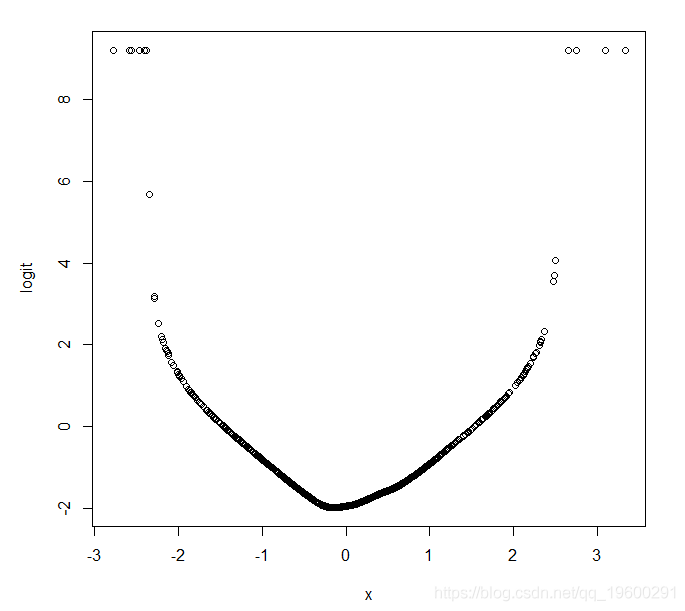
![]()
注意事项
我们在这里看到的方法显然并不完美,在不同情况下或多或少会有用。对于小数据集(例如n = 50),实际上没有足够的数据来非参数地估计Y的平均值如何依赖于X,因此并不是真正有用。即使有大型数据集,黄土图中建议的功能形式也可能看起来很奇怪,纯粹是因为不精确,因为X空间/分布的某些部分没有太多数据。