原文链接:http://tecdat.cn/?p=6274
在这篇文章中,我们将看看如何在实践中使用R 。为了说明,我们首先从线性回归模型中模拟一些简单数据,其中残差方差随着协变量的增加而急剧增加:
n < - 100
x < - rnorm(n)
residual_sd < - exp(x)
y < - 2 * x + residual_sd * rnorm(n)该代码从给定X的线性回归模型生成Y,具有真正的截距0和真实斜率2.然而,残差标准差已经生成为exp(x),使得残差方差随着X的增加而增加。可以直观地看到这个效果:
这使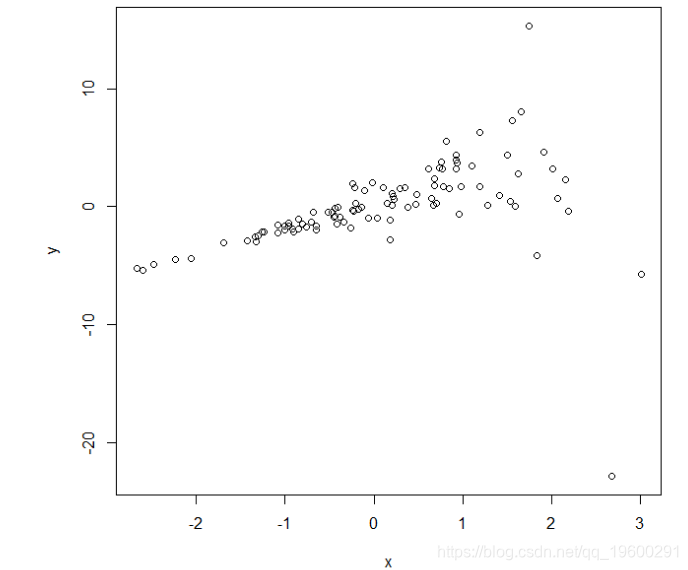
![]()
模拟Y对X数据的图,其中残差方差随着X的增加而增加
在这个简单的情况下,视觉上清楚的是,对于较大的X值,残差方差要大得多,因此违反了“基于模型”的标准误差所需的关键假设之一。无论如何,如果我们像往常一样拟合线性回归模型,让我们看看结果是什么:
> summary(mod)
lm(formula = y~x)
最小1Q中位数3Q最大值
-25.9503 -0.8574 -0.1751 0.9809 13.4015
系数:
估计标准。误差t值Pr(> | t |)
(截距)-0.08757 0.36229 -0.242 0.809508
x 1.18069 0.31071 3.800 0.000251 ***
---
Signif。代码:0'***'0.001'**'0.01'*'0.05'。' 0.1 '' 1
残余标准误差:3.605 98上的自由度的
多R平方:0.1284,调整R平方:0.1195
F统计:14.44 1和98 DF,p值:0.0002512
这表明我们有强有力的证据反对Y和X独立的零假设。为了便于比较,我们注意到X效果的标准误差是0.311。
接下来,我 然后将先前安装的lm对象传递给包中的函数,该函数计算 方差估计值:
> vcovHC(mod,type =“HC”)
(
截距)x (截距)0.08824454 0.1465642
x 0.14656421 0.3414185
得到的矩阵是两个模型参数的估计方差协方差矩阵。因此,对角线元素是估计的方差(平方标准误差)。因此,我们可以通过采用这些对角元素和平方根来计算夹心标准误差:
> sandwich_se
(Intercept)x
0.2970598 0.5843103因此,X系数的 标准误差为0.584。这与先前基于模型的标准误差0.311形成对比。因为此处残差方差不是恒定的,所以基于模型的标准误差低估了估计的可变性,并且夹心标准误差对此进行了校正。让我们看看它对置信区间和p值有何影响。为此,我们使用估计量渐近(在大样本中)正态分布的结果。首先,要获得置信区间限制,我们可以使用:
> coef(mod)-1.96 * sandwich_se
(
截距)x -0.66980780 0.03544496
> coef(mod)+ 1.96 * sandwich_se
(
截距)x 0.4946667 2.3259412因此,X系数的95%置信区间限制为(0.035,2.326)。为了找到p值,我们可以首先计算z-统计量(系数除以它们相应的标准误差),并将平方z-统计量与一个自由度上的卡方分布进行比较:
> p_values < - pchisq(z_stat ^ 2,1,lower.tail = FALSE)
> p_values
(
截距)x 0.76815365 0.04331485我们现在有一个p值表示Y对X的依赖性为0.043,而早期从lm为0.00025得到的p值。