什么是检验对?
检验对的形式 (x1,x2)(X1,X2) 出现在两种情况中:
- 对同一实体执行两次测量。例如,一项评估新型胰岛素疗效的临床研究将为每位患者测量两次血糖水平:之前(X1X1)服药后(X2X2)。
- 对不同的实体进行测量。但是,实体根据其特征进行匹配。例如,为了测试药物的功效,您可能希望根据体重,年龄或其他特征配对研究参与者,以控制这些混杂因素。
在第一种情况下,配对是数据生成过程的自然结果。在第二种情况下,配对由研究设计强制执行。
为什么依赖测量有用?
使用配对测量,可以控制影响测量结果的混杂因素。因此,匹配研究设计通常比涉及独立组的设计更强大。
睡眠数据集
让我们考虑睡眠数据集,举例说明:
<span style="color:#000000"><span style="color:#000000"><code>data(sleep)
print(sleep)</code></span></span>## extra group ID
## 1 0.7 1 1
## 2 -1.6 1 2
## 3 -0.2 1 3
## 4 -1.2 1 4
## 5 -0.1 1 5
## 6 3.4 1 6
## 7 3.7 1 7
## 8 0.8 1 8
## 9 0.0 1 9
## 10 2.0 1 10
## 11 1.9 2 1
## 12 0.8 2 2
## 13 1.1 2 3
## 14 0.1 2 4
## 15 -0.1 2 5
## 16 4.4 2 6
## 17 5.5 2 7
## 18 1.6 2 8
## 19 4.6 2 9
## 20 3.4 2 10extra表示与基线测量相比睡眠中的增加/减少(正/负值),组表示药物,ID表示患者ID。为了更清楚,我将组重命名为药物:
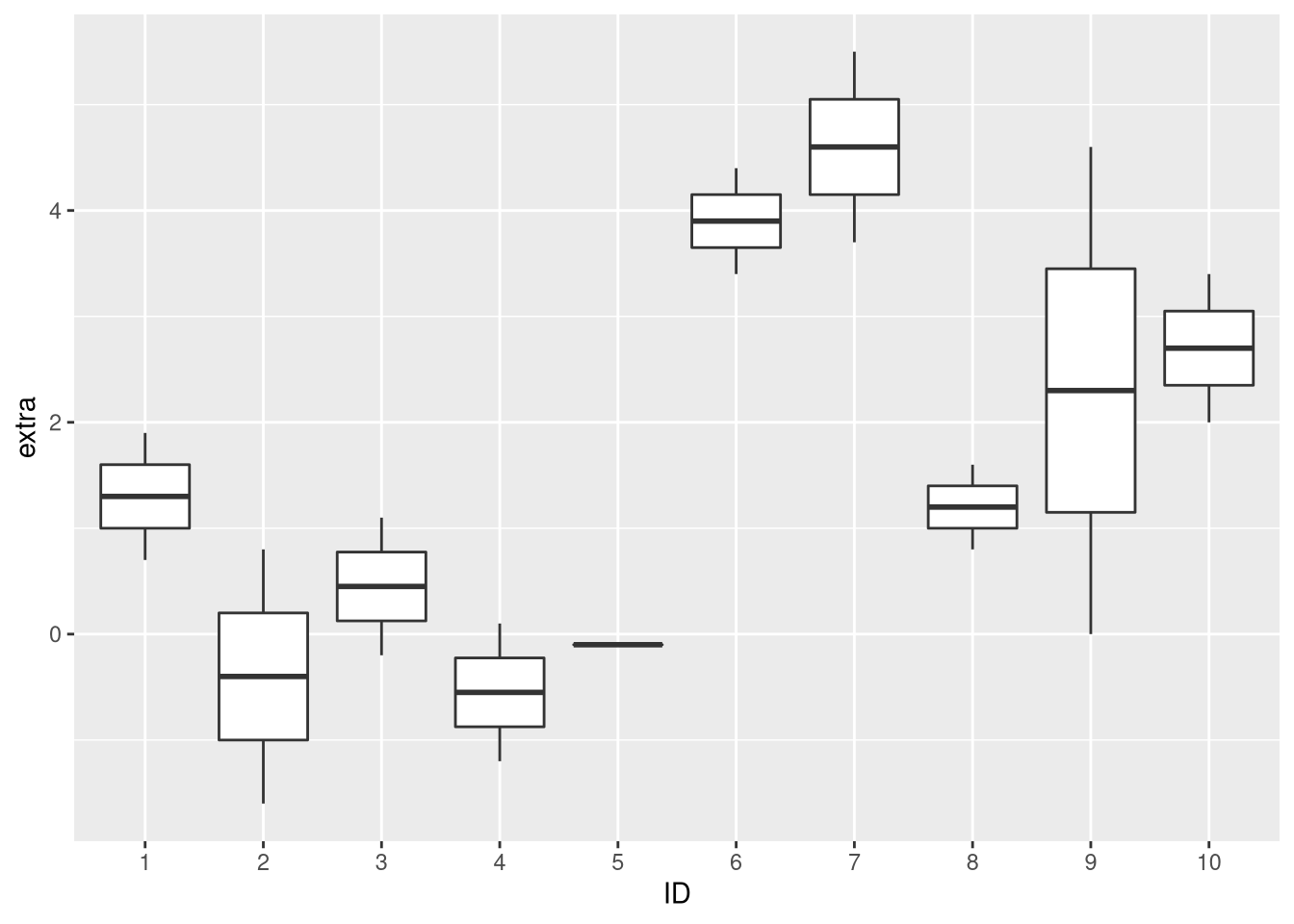
调查睡眠数据集
重要的是要注意每个人都是不同的。因此,相同药物的功效可能因人而异。让我们看看这个数据集中是否也是这种情况:
![]()
实际上,个体研究对象的额外睡眠时间分布似乎是双峰的。大约一半的受试者表现出两种药物的睡眠持续时间大幅增加,而另一半受试者几乎没有益处甚至患有药物。使用配对测试,可以校正这些患者间差异,而对于假设测量是独立的测试,这是不可能的。
比较不成对和配对测试
现在让我们比较不成对测试和配对测试对睡眠数据集的执行情况。
Wilcoxon秩和检验
如果我们在测量中使用未配对的Wilcoxon秩和检验(Mann-Whitney U检验),则该检验将产生以下药物顺序以确定显着性:
## [1] 1 1 1 1 2 1 2 1 1 2 2 2 2 1 1 2 1 2 2 2
## Levels: 1 2我们可以看到,虽然代表性不足,但药物1在最高级别中出现了好几次。这是因为,对于两种药物反应良好的患者,药物1也运作良好。由于依赖药物的额外睡眠时间没有明显的分离,因此测试在5%的水平上不会显着:
## [1] 0.06932758威尔科克森签下了排名测试
考虑成对的测量值更有意义,因为测试结果不受个体受试者的药物敏感性的影响。我们可以看到,当我们计算患者内额外睡眠差异时,用于未配对Wilcoxon签名等级测试的度量:
## [1] -1.2 -2.4 -1.3 -1.3 0.0 -1.0 -1.8 -0.8 -4.6 -1.4非阳性差异清楚地表明药物1在所有研究受试者中都不如药物2。由于Wilcoxon签名等级测试基于这些差异,因此发现两种药物在显着性水平为5%时存在显着差异:
<span style="color:#000000"><span style="color:#000000"><code><span style="color:#888888"># use a paired test:</span>
w.unpaired <- wilcox.test(x, y, paired = <span style="color:#78a960">TRUE</span>)
print(w.unpaired$p.value)</code></span></span>## [1] 0.009090698结论
这个例子说明了为什么分组研究设计优于测量独立的研究设计。当然,仅在使用考虑配对检验的测试来评估数据的情况下才是这种情况。否则,统计功率会丢失,并且实际上重要的结果可能被错误地视为无关紧要。