问题:请讲下java中垃圾回收器有哪些?
分析:该问题主要考察hotspot虚拟机下实现的垃圾回收器
回答要点:
主要从以下几点去考虑,
1、垃圾回收器的种类
2、每种垃圾回收器的着重点是什么
前边的文章中分享了“如何设计一个垃圾回收器”、“垃圾回收算法”、“垃圾回收中的并行并发”等,今天打算分享下hotspot虚拟机中的垃圾回收器。
先看下垃圾回收器的分类,分类标准有按照垃圾回收线程和用户线程的关系、工作的内存区域
垃圾回收线程和用户线程的关系
串行
serial、serial old
并行
parNew、parallel Scavenge、parallel old
并发
CMS、G1
工作的内存区域
年轻代
serial、parNew、parallel Scavenge
年老代
serial old、parallel old、CMS
年轻代、年老代
G1
有了上面的分类,对hotspot虚拟机下的垃圾回收器大致有了了解,下面重点介绍。
serial
serial使用复制算法,作用在年轻代。同时垃圾回收线程是单线程的,也就是串行回收。以减少系统的停顿时间为目的。
serial old
serial old使用标记-整理算法,作用在年老代。垃圾回收线程是单线程,是串行回收。它是serial的年老代版本。以减少系统的停顿时间为目的
parNew
parNew使用复制算法,作用在年轻代。垃圾回收线程是多线程的,是并行回收。它可以相当于serial的多线程版本。以减少系统的停顿时间为目的
parallel Scavenge
parallel Scavenge使用复制算法,作用在年轻代。垃圾回收线程是多线程的,是并行回收。以控制系统的吞吐量为目的,适合后台计算型的任务。
parallel old
parallel Old使用标记-整理算法,作用在年老代。垃圾回收线程是多线程的,是并行回收的,是parallel Scavenge的年老代版本。
CMS
CMS使用标记-清除算法,作用在年老代。垃圾回收是多线程的,且和用户线程是并发执行的。以获取最少的系统停顿时间为目的。收集的过程如下,
- 初始标记
- 并发标记
- 重新标记
- 并发清除
示意图如下,
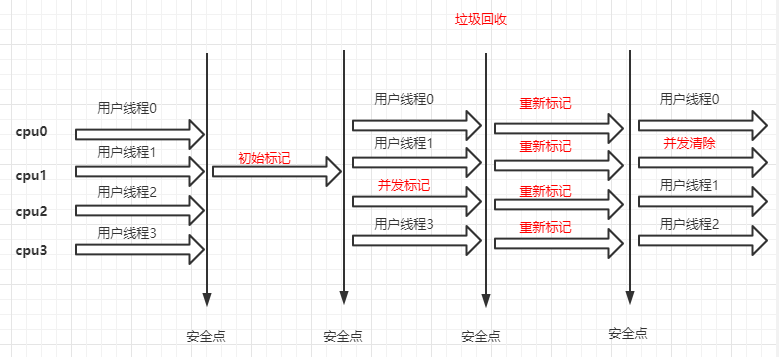
在上面的4个阶段中,初始标记和重新标记都存在stop the world的现象,前者是单线程串行,后者是多线程并行,在并发标记和并发清除阶段则属于并发执行。由于使用的是标记-清除算法,所以在垃圾回收后会存在垃圾碎片的情况;由于是在并发清除阶段用户线程还在运行中,所以会存在浮动垃圾无法回收的情况,
G1
G1作为一款主流的垃圾回收器,从整体上而言使用的是标记-整理算法,具体到每两个region使用的是复制算法,具有以下的特点,
- 充分利用并行与并发的优势
- 分代收集,在G1中仍然保持着分代收集的概念,但是不需要搭配其他收集器,它自己就可以管理整个堆,而且年轻代和年老代不再是物理隔离的,取而代之的是把整个堆分为很多大小相等的独立区域,称为region,年轻代就是一组region的集合。
- 空间整合,由于从整体上看使用标记-整理算法,从每两个region上看使用复制算法,所以使用G1不会产生垃圾碎片。
- 可预测的停顿时间,G1和CMS都是以减少停顿时间为目的,和CMS不同的是G1建立了一套可预测的停顿时间模型。
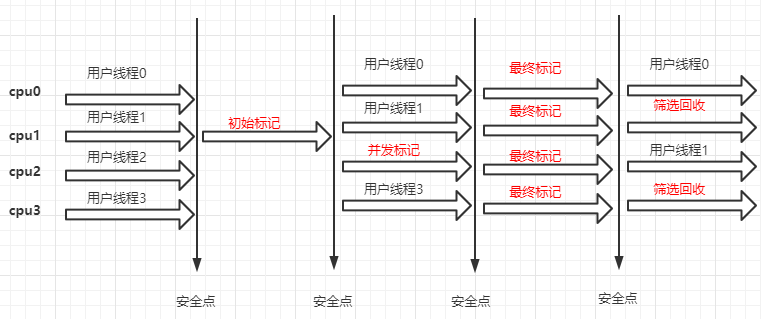
G1分为以下几个阶段
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
示意图如下,
除了上面介绍的7款垃圾回收器外,现在还有一个ZGC,是比较新的垃圾回收器,这个计划后续再研究。
衡量一款垃圾回收器的好坏,主要看两个关键指标:停顿时间、吞吐量。针对这两个指标的解释,可以参见《java面试一日一题:如何设计一款垃圾回收器》。
停顿时间重点关注用户线程的停顿时长,主要影响的是和用户的交互上,反应在系统的响应速度;吞吐量则关注的是高效利用CPU时间,完成后台的计算任务。综上,如果是和用户交互的系统,请选择以减少停顿时间为目的的垃圾回收器,如果是后台的定时任务等耗时的计算任务,请选择以提升吞吐量为目的的垃圾回收器。
推荐阅读
《java面试一日一题:再谈垃圾回收器中的串行、并行、并发》
