http协议
http协议介绍
# 什么叫做http
HTTP 全称:Hyper Text Transfer Protocol 中文名:超文本传输协议
# http之 [超文本传输协议]
是一种按照URL指示,将超文本文档从一台主机(Web服务器)传输到另一台主机(浏览器)的应用层协议,以实现超链接的功能。
怎讲?可以这么理解:通过一个超链接,打开一个文本,当我们打开浏览器访问百度:https://www.baidu.com,浏览器在帮你,去百度的服务器上下载一个文本(index.html)
# 什么是URL
统一资源定位符(唯一标识)
# URL组成部分
http://www.biadu.com:90/epel/1.txt
协议: http://
主机:端口 www.biadu.com:90
文件名和路径 服务器站点目录下的,目录和文件
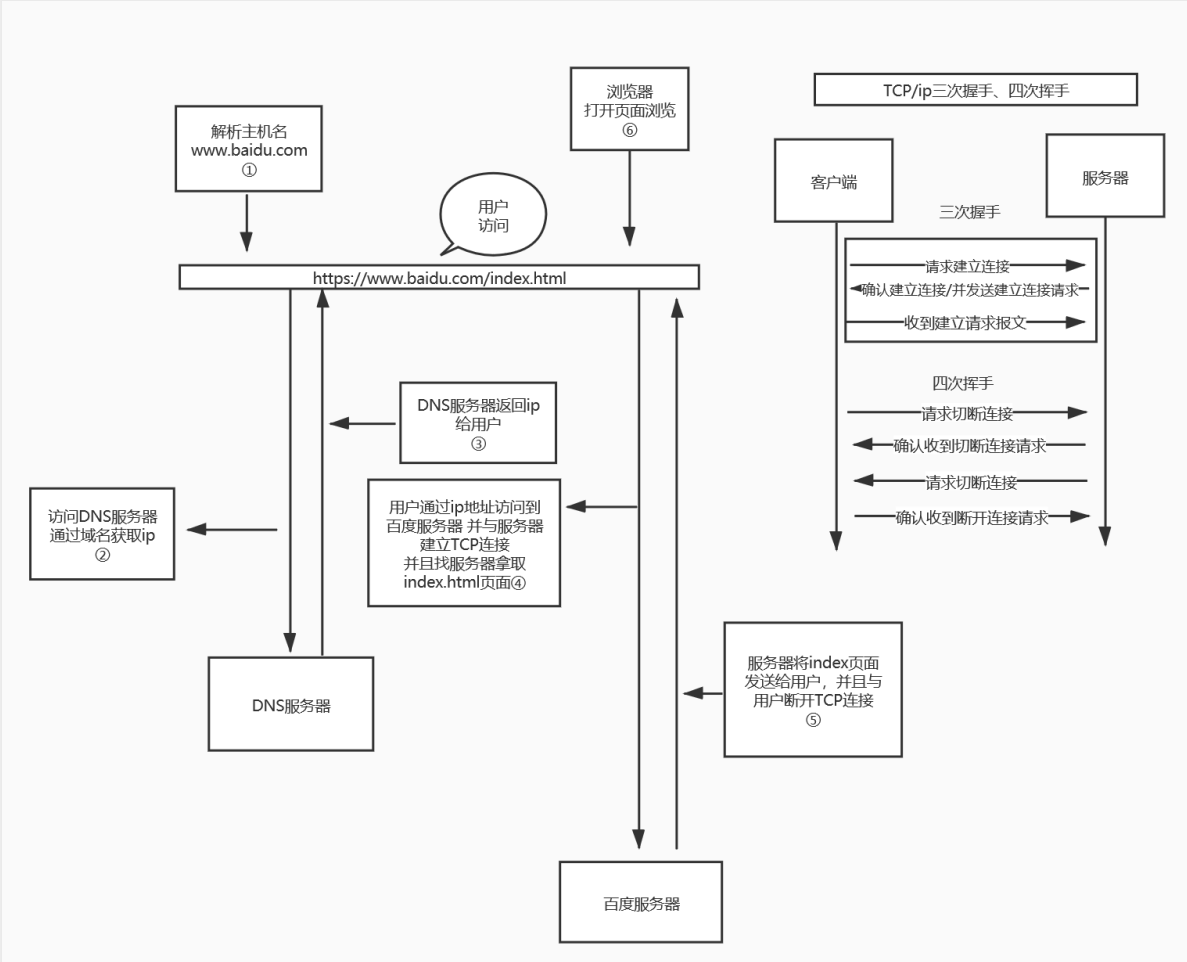
http工作原理
1.用输入域名 - > 浏览器跳转 - > 浏览器缓存 - > Hosts文件 - > DNS解析(递归查询|迭代查询)
客户端向服务端发起查询 - > 递归查询
服务端向服务端发起查询 - > 迭代查询
2.由浏览器向服务器发起TCP连接(三次握手)
客户端 -->请求包连接 -syn=1 seq=x 服务端
服务端 -->响应客户端syn=1 ack=x+1 seq=y 客户端
客户端 -->建立连接 ack=y+1 seq=x+1 服务端
3.客户端发起http请求:
1)请求的方法是什么: GET获取
2)请求的Host主机是: blog.driverzeng.com
3)请求的资源是什么: /index.html
4)请求的端端口是什么: 默认http是80 https是443
5)请求携带的参数是什么: 属性(请求类型、压缩、认证、浏览器信息、等等)
6)请求最后的空行
4.服务端响应的内容是
1)服务端响应使用WEB服务软件
2)服务端响应请求文件类型
3)服务端响应请求的文件是否进行压缩
4)服务端响应请求的主机是否进行长连接
5.客户端向服务端发起TCP断开(四次挥手)
客户端 --> 断开请求 fin=1 seq=x --> 服务端
服务端 --> 响应断开 fin=1 ack=x+1 seq=y --> 客户端
服务端 --> 断开连接 fin=1 ack=x+1 seq=z --> 客户端
客户端 --> 确认断开 fin=1 ack=x+1 seq=sj --> 服务端
- 原理图
http请求方法
| 方法(Method) | 含义 |
|---|---|
| GET | 请求读取一个Web页面(下载一个页面) |
| POST | 附加一个命名资(如Web页面)(上传) |
| DELETE | 删除Web页面 |
| CONNECT | 用于代理服务器 |
| HEAD | 请求读取一个Web页面的头部 |
| PUT | 请求存储一个Web页面 |
| TRACE | 用于测试,要求服务器送回收到的请求 |
| OPTION | 查询特定选项 |
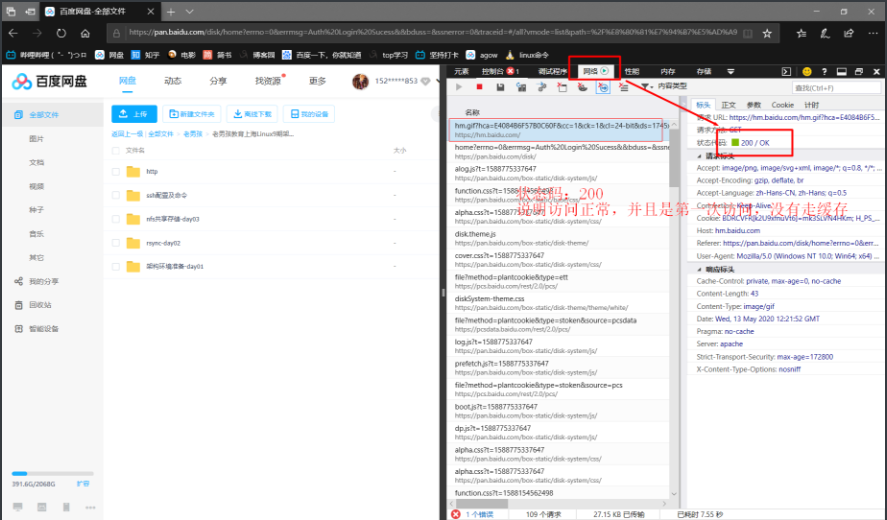
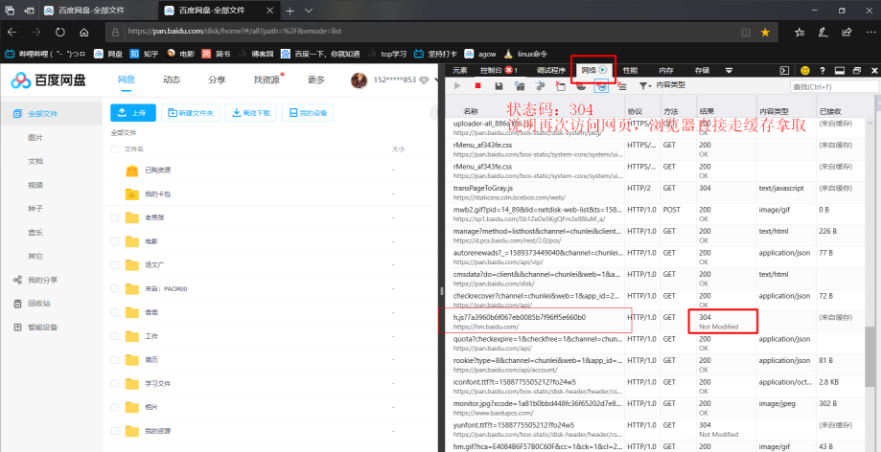
http状态码
- 1xx(临时响应)表示临时响应并需要请求者继续执行操作的状态代码。
- 2xx和3xx都是网页可以正常访问
- 4xx:Nginx的报错(出错,出在nginx上)去检查nginx服务,或者服务器权限等...
- 5xx:后端报错(nginx后面连接的服务报错:mysql、php、tomcat、redis.......,如果不是前面的原因:你们的代码有问题,滚回去重写)
详细状态码请参考网页TP
| 状态码 | 含义 |
|---|---|
| 200 | 成功 |
| 301 | 永久重定向(跳转) |
| 302 | 临时重定向(跳转) |
| 304 | 本地缓存(浏览器的缓存) |
| 307 | 内部重定向(跳转) |
| 400 | 客户端错误 |
| 401 | 认证失败 |
| 403 | 找不到主页,权限不足 |
| 404 | 找不到页面 |
| 405 | 请求方法不被允许 |
| 500 | 内部错误(MySQL关闭等...) |
| 502 | bad gateway 坏了的网关(php tomcat 等服务关闭) |
| 503 | 服务端请求限制 |
| 504 | 请求超时 |
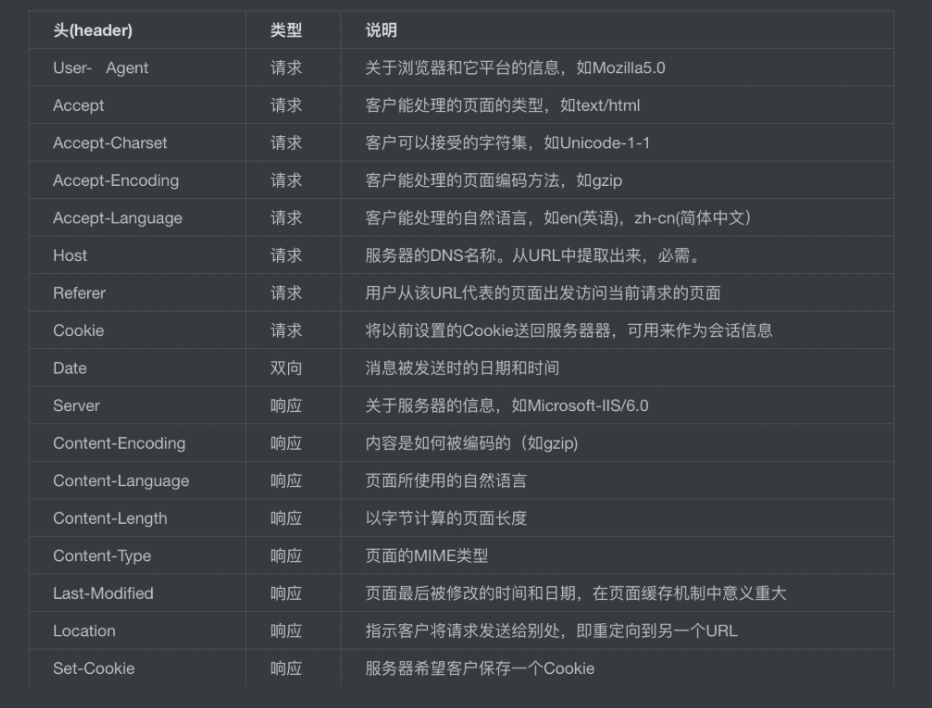
http头部信息
- Referer重点说明:浏览器向 WEB 服务器表明自己是从哪个 网页/URL 获得/点击 当前请求中的网址/URL,如当前处于百度搜索界面访问简书,那简书服务器得知的请求报文则包含一则地址为www.baidu.com的Referer信息
http相关术语
PV
# pv
- 指一个网站的请求量,页面独立浏览量,如一个用户多次对页面进行访问,PV都会将其记录
# uv
- 独立设备,一台手机多次访问一个页面只会算做一次访问,这里按照设备作为访问量
# ip
- 独立的ip,如300人使用一个ip地址上网,对于网页来说,只有一个用户在进行访问
# 案例:
假设公司有一座大厦,大厦有100人,每个人有一台电脑和一部手机,上网都是通过nat转换出口,每个人点击网站2次, 请问对应的pv,uv,ip分别是多少?每次访问的请求数为一次
PV : 页面独立浏览量
UV : 独立设备
IP : 独立IP
那么上面的题:
PV: 100*2*2 = 400
UV: 1002*2 = 200
IP: 1
- 日PV千万量级并不大,一般公司日UV可达到五六十万左右,对于PV的统计,可对访问日志文件进行统计,查看行数即可,因为一次的请求即为一行内容。对PV的统计一般有运维来进行,而uv的统计则需要开发统计,因需要对ip
松耦合架构
面向服务的架构(SOA)是一个组件模型,它将应用程序的不同功能单元(称为服务)进行拆分,并通过这些服务之间定义良好的接口和契约联系起来。接口是采用中立的方式进行定义的,它应该独立于实现服务的硬件平台、操作系统和编程语言。这使得构建在各种各样的系统中的服务可以以一种统一和通用的方式进行交互。
简单说明:比如京东,就是将多个网站组合,拆分模块,浏览器中进行访问一般都是jindong.com 但登录或者购买界面又是其他网站。
#一个电商公司,他的网站页面功能会有很多
注册
登录
首页
详情页
购物车
价格标签
留言
客服
支付中心
物流
仓储信息
订单相信
图片
网站分析
网站数据包分析

网站数据包详解
# 基本信息
请求网址:https://www.driverzeng.com/
请求方法:GET
远程地址:39.104.203.184:443
状态码:
200
版本:HTTP/1.1
Request URL: http://www.biadu.com/
Request Method: GET
Status Code: 200 OK
Remote Address: 10.0.0.7:80
Referrer Policy: no-referrer-when-downgrade
# 请求头部
## 请求的资源类型
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*=0.8,application/signed-exchange;v=b3
## 资源类型压缩
Accept-Encoding: gzip, deflate
## 资源类型的语言
Accept-Language: zh-CN,zh;q=0.9
## 缓存控制:服务端没有开启缓存
Cache-Control: no-cache
## 长连接
Connection: keep-alive
## 访问的主机:www.biadu.com
Host: www.biadu.com
## 项目缓存:没有开启
Pragma: no-cache
## 客户端优先加密
Upgrade-Insecure-Requests: 1
## 用户访问网站的客户端工具
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36
# 响应头部
Connection: keep-alive # 建立长连接
Content-Type: text/html;charset=utf-8 # 解析方式和字符集
Date: Wed, 13 May 2020 02:29:35 GMT # 日期
server:Nginx/1.14.1 # 该网站服务器,使用的软件和版本号
status: 200 # 状态码
状态码分析