14.3.2.2. Avoiding request queue congestion
Each request queue has a maximum number of allowed pending requests.By default, a queue has at most 128 pending read requests and 128 pending write requests.
每个请求队列都有一个允许处理的最大请求数。默认情况下,一个队列最多有128个等待读请求和128个等待写请求(CFQ就不是128)。
14.3.4.2. The "CFQ" elevator
The main goal of the "Complete Fairness Queueing" elevator is ensuring a fair allocation of the disk I/O bandwidth among all the processes that trigger the I/O requests. To achieve this result, the elevator makes use of a large number of sorted queuesby default, 64that store the requests coming from the different processes.
"CFQ(完全公平队列)”算法的主要目标是在触发I/O请求的所有进程中确保磁盘I/O带宽的公平分配。为了达到这个目标,算法使用许多个排序队列——缺省为64——它们存放了不同进程发出的请求。
14.3.4.3. The "Deadline" elevator
By default, the expire time of read requests is 500 milliseconds, while the expire time for write requests is 5 secondsread requests are privileged over write requests because they usually block the processes that issued them.
默认情况下,读请求的超时时间是500ms,而写请求的超时时间是5s,读请求优先于写请求,因为读请求通常会阻塞发出请求的进程。
14.3.4.4. The "Anticipatory" elevator
The default expire time for read requests is 125 milliseconds, while the default expire time for write requests is 250 milliseconds.
读请求的默认超时时间是125ms,写请求的缺省超时时间是250ms。
在centos6.5中默认以下参数为/sys/block/sda/queue
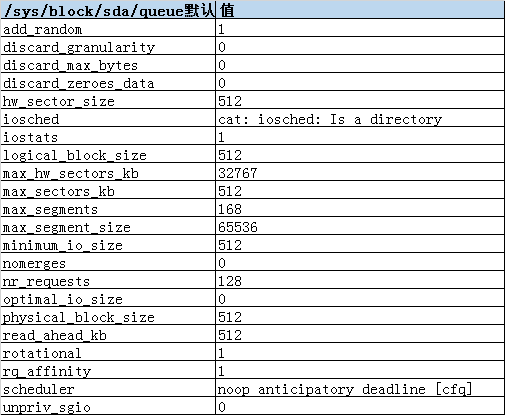
add_random
This file allows to turn off the disk entropy contribution. Default value of this file is '1'(on).
discard_granularity
This shows the size of internal allocation of the device in bytes, if reported by the device. A value of '0' means device does not support the discard functionality.
discard_max_bytes (RW)
While discard_max_hw_bytes is the hardware limit for the device, this setting is the software limit. Some devices exhibit large latencies when large discards are issued, setting this value lower will make Linux issue smaller discards and potentially help reduce latencies induced by large discard operations.
hw_sector_size (RO)
This is the hardware sector size of the device, in bytes.
iostats (RW)
This file is used to control (on/off) the iostats accounting of the disk.
logical_block_size lsblk -o NAME,PHY-SeC,LOG-SEC The logical block size is usually different from the physical block size. The physical block size is usually 512 bytes, which is the size of the smallest block that the disk controller can read or write.The UFS logical_block_size is 8192bytes max_hw_sectors_kb 表示单个请求所能处理的最大KB(硬约束) max_sectors_kb 表示设备允许的最大请求大小。 max_segments 表示设备能够允许的最大段的数目。
max_segment_size (RO)
Maximum segment size of the device.
minimum_io_size (RO)
This is the smallest preferred IO size reported by the device.
nomerges (RW)
This enables the user to disable the lookup logic involved with IO merging requests in the block layer. By default (0) all merges are enabled. When set to 1 only simple one-hit merges will be tried. When set to 2 no merge algorithms will be tried (including one-hit or more complex tree/hash lookups).
nr_requests The nr_requests represents the IO queue size. read_ahead_kb The read_ahead_kb represents the amount of additional data that should be read after fulfilling a given read request. For example, if there's a read-request for 4KB and the read_ahead_kb is set to 64, then an additional 64KB will be read into the cache after the base 4KB request has been met. Why read this additional data? It counteracts the rotational latency problems inherent in spinning disk / hard disk drives. A 7200 RPM hard drive rotates 120 times per second, or roughly once every 8ms. That may sound fast, but take an example where you're reading records from a database and only gathering 4KB with each IO read request (one read per rotation). Done serially that would produce a throughput of a mere 480K/sec. This is why read-ahead and request queue depth are so important to getting good performance with spinning disk. With SSD, there are no mechanical rotational latency issues so the SSD profile uses a small 4k read-ahead.
参见https://wiki.osnexus.com/index.php?title=IO_Performance_Tuning#QuantaStor_System_Network_Setup
以上所有参数可参考https://www.mjmwired.net/kernel/Documentation/block/queue-sysfs.txt
通过以下命令可以指定sda使用不同的IO调度器,而相应的/sys/block/sda/queue/iosched的内容也将发生变化。
echo deadline >/sys/block/sda/queue/scheduler
echo anticipatory >/sys/block/sda/queue/scheduler
echo cfq >/sys/block/sda/queue/scheduler
echo noop >/sys/block/sda/queue/scheduler
下面罗列出不同调度器时/sys/block/sda/queue/iosched的参数值如下:

anticipatory还包括一个参数est_time未在上表列出(太长不好看)
est_time "0 % exit probability 0 % probability of exiting without a cooperating process submitting IO 0 ms new thinktime 584 sectors new seek distance"
Tuning The CFQ Scheduler
Remember that this is for mostly to entirely non-interactive work where latency is of lower concern. You care some about latency, but your main concern is throughput.
| Attribute | Meaning and suggested tuning |
fifo_expire_async |
Number of milliseconds an asynchronous request (buffered write) can remain unserviced. If lowered buffered write latency is needed, either decrease from default 250 msec or consider switching to deadline scheduler. |
fifo_expire_sync |
Number of milliseconds a synchronous request (read, or O_DIRECT unbuffered write) can remain unserviced. If lowered read latency is needed, either decrease from default 125 msec or consider switching to deadline scheduler. |
low_latency |
0=disabled: Latency is ignored, give each process a full time slice. 1=enabled: Favor fairness over throughput, enforce a maximum wait time of 300 milliseconds for each process issuing I/O requests for a device. Select this if using CFQ with applications requiring it, such as real-time media streaming. |
quantum |
Number of I/O requests sent to a device at one time, limiting the queue depth. request (read, or O_DIRECT unbuffered write) can remain unserviced. Increase this to improve throughput on storage hardware with its own deep I/O buffer such as SAN and RAID, at the cost of increased latency. |
slice_idle |
Length of time in milliseconds that cfq will idle while waiting for further requests. Set to 0 for solid-state drives or for external RAID with its own cache. Leave at default of 8 milliseconds for internal non-RAID storage to reduce seek operations. |
Tuning The Deadline Scheduler
Remember that this is for interactive work where latency above about 100 milliseconds will really bother your users. Throughput would be nice, but we must keep the latency down.
| Attribute | Meaning and suggested tuning |
fifo_batch |
Number of read or write operations to issue in one batch. Lower values may further reduce latency. Higher values can increase throughput on rotating mechanical disks, but at the cost of worse latency. You selected the deadline scheduler to limit latency, so you probably don't want to increase this, at least not by very much. |
read_expire |
Number of milliseconds within which a read request should be served. Reduce this from the default of 500 to 100 on a system with interactive users. |
write_expire |
Number of milliseconds within which a write request should be served. Leave at default of 5000, let write operations be done asynchronously in the background unless your specialized application uses many synchronous writes. |
writes_starved |
Number read batches that can be processed before handling a write batch. Increase this from default of 2 to give higher priority to read operations. |
Tuning The NOOP Scheduler
Remember that this is for entirely non-interactive work where throughput is all that matters. Data mining, high-performance computing and rendering, and CPU-bound systems with fast storage.
The whole point is that NOOP isn't a scheduler, I/O requests are handled strictly first come, first served. All we can tune are some block layer parameters in /sys/block/sd*/queue/*, which could also be tuned for other schedulers, so...
Tuning General Block I/O Parameters
These are in /sys/block/sd*/queue/.
| Attribute | Meaning and suggested tuning |
max_sectors_kb |
Maximum allowed size of an I/O request in kilobytes, which must be within these bounds: Min value = max(1, logical_block_size/1024) Max value = max_hw_sectors_kb |
nr_requests |
Maximum number of read and write requests that can be queued at one time before the next process requesting a read or write is put to sleep. Default value of 128 means 128 read requests and 128 write requests can be queued at once. Larger values may increase throughput for workloads writing many small files, smaller values increase throughput with larger I/O operations. You could decrease this if you are using latency-sensitive applications, but then you shouldn't be using NOOP if latency is sensitive! |
optimal_io_size |
If non-zero, the storage device has reported its own optimal I/O size. If you are developing your own applications, make its I/O requests in multiples of this size if possible. |
read_ahead_kb |
Number of kilobytes the kernel will read ahead during a sequential read operation. 128 kbytes by default, if the disk is used with LVM the device mapper may benefit from a higher value. If your workload does a lot of large streaming reads, larger values may improve performance. |
rotational |
Should be 0 (no) for solid-state disks, but some do not correctly report their status to the kernel. If incorrectly set to 1 for an SSD, set it to 0 to disable unneeded scheduler logic meant to reduce number of seeks. |
对于IO调度器参数的描述参见https://cromwell-intl.com/open-source/performance-tuning/disks.html
https://access.redhat.com/documentation/zh-cn/red_hat_enterprise_linux/7/html/performance_tuning_guide/sect-red_hat_enterprise_linux-performance_tuning_guide-storage_and_file_systems-configuration_tools#sect-Red_Hat_Enterprise_Linux-Performance_Tuning_Guide-Configuration_tools-Tuning_the_cfq_scheduler