安装第三方库
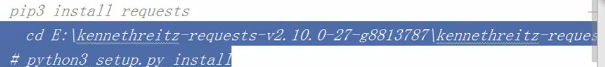
两种方法,
一、在DOS界面下运行
pip3 install requests
二、切换至request目录下
cd E:
python3 setup.py install
--------------------------------------------------------------------------------------------
正则表达式

正则字符
|
释义 |
举例 |
|
|
+ |
前面元素至少出现一次 |
ab+:ab、abbbb 等 |
|
* |
前面元素出现0次或多次 |
ab*:a、ab、abb 等 |
|
? |
匹配前面的一次或0次 |
Ab?: A、Ab 等 |
|
^ |
作为开始标记 |
^a:abc、aaaaaa等 |
|
$ |
作为结束标记 |
c$:abc、cccc 等 |
|
d |
数字 |
3、4、9 等 |
|
D |
非数字 |
A、a、- 等 |
|
[a-z] |
A到z之间的任意字母 |
a、p、m 等 |
|
[0-9] |
0到9之间的任意数字 |
0、2、9 等 |
示例
一. 判断字符串是否是全部小写


# -*- coding: cp936 -*- import re s1 = 'adkkdk' s2 = 'abc123efg' an = re.search('^[a-z]+$', s1) if an: print 's1:', an.group(), '全为小写' else: print s1, "不全是小写!" an = re.match('[a-z]+$', s2) if an: print 's2:', an.group(), '全为小写' else: print s2, "不全是小写!"
结果

究其因
1. 正则表达式不是python的一部分,利用时需要引用re模块
2. 匹配的形式为: re.search(正则表达式, 带匹配字串)或re.match(正则表达式, 带匹配字串)。两者区别在于后者默认以开始符(^)开始。因此,
re.search('^[a-z]+$', s1) 等价于 re.match('[a-z]+$', s2)
3. 如果匹配失败,则an = re.search('^[a-z]+$', s1)返回None
group用于把匹配结果分组
例如
import re a = "123abc456" print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0) #123abc456,返回整体 print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1) #123 print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2) #abc print re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3) #456
1)正则表达式中的三组括号把匹配结果分成三组
group() 同group(0)就是匹配正则表达式整体结果
group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。
2)没有匹配成功的,re.search()返回None
3)当然郑则表达式中没有括号,group(1)肯定不对了。