1.mAP
mAP的全称是mean Average Precision,意为平均精度均值(如果按照原来的顺利翻译就是平均均值精度)。这个指标是多目标检测和多标签图像分类中长常用的评测指标,因为这类任务中的标签大多不止一个,所以不能用普通的单标签图像的分类标准,也就是mean Precision,平均精确确率这个指标。mAP是将多分类任务中的平均精度AP(Average Precision)求和再取平均。
---------------------------------------来自菜鸡的分割线-----------------------------------------
因为我对基本概念的东西一直都模棱两可的,所以还是先拓展一下Precision,精确率这个指标。精确率的定义是,对于给定的测试数据集,分类器正确分类的样本数与总样本数之比的值。
假设样本总图像数为 n(x+y),预测目标数为 x,干扰目标数为 y,预测正确的正样本数(True Positive)为TP,预测错误的正样本数(False Positive)为FP,预测正确的负样本数(True Negative)为TN,预测错误的负样本数(False Negative)为FN。
则精确率Precision和召回率Recall的定义为:

Precision就是检测出来的样本有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
而平均精确率,即为所有准确率的和除以该类别的图像数量:

AP衡量的是模型在单个类别上判断结果的好坏(效果好坏),mAP衡量的是模型在所有类别上的好坏。
由于目标检测中有不止一个类别,因此需要对所有类别计算平均AP值:
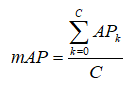
其中, 分子为每一个类别的平均精度, 分母为总类别数。
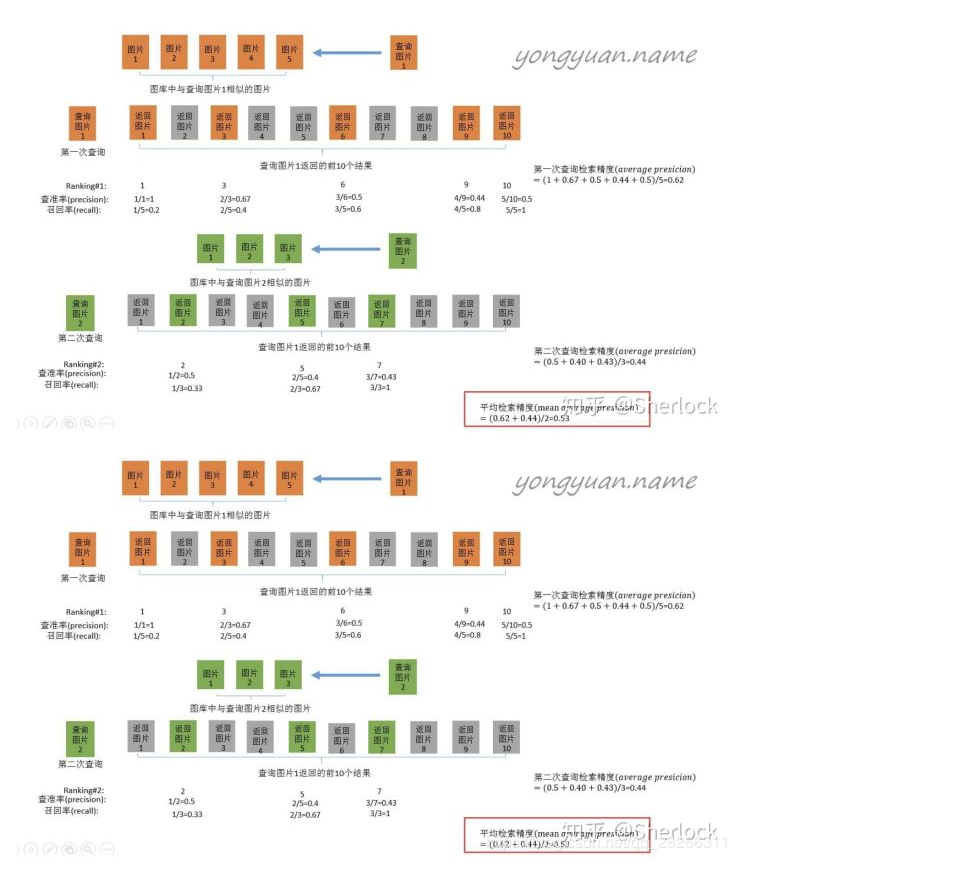
看回第4点的那个例子:
当需要检索的人数为1时,AP=(100%+66.66%+50%)/3=72.22%
而当需要检索的不止1个人时,此时正确率则取所有人的平均mAP。如图所示:
---------------------------------------来自菜鸡的分割线-----------------------------------------
2.Rank-k
搜索结果中最靠前(置信度最高)的n张图有正确结果的概率。
参考资料:https://blog.csdn.net/Chen_yuazzy/article/details/89261887
例子:
假设你的分类系统最终的目的是:能取出测试集中所有飞机的图片,而不是大雁的图片。
现在做如下的定义:
True positives : 飞机的图片被正确的识别成了飞机。
True negatives: 大雁的图片没有被识别出来,系统正确地认为它们是大雁。
False positives: 大雁的图片被错误地识别成了飞机。
False negatives: 飞机的图片没有被识别出来,系统错误地认为它们是大雁。
假设你的分类系统使用了上述假设识别出了四个结果,如下图所示:
那么在识别出的这四张照片中:
True positives : 有三个,画绿色框的飞机。
False positives: 有一个,画红色框的大雁。
没被识别出来的六张图片中:
True negatives : 有四个,这四个大雁的图片,系统正确地没有把它们识别成飞机。
False negatives: 有两个,两个飞机没有被识别出来,系统错误地认为它们是大雁。
Precision 与 Recall
Precision其实就是在识别出来的图片中,True positives所占的比率:
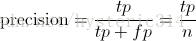
其中的n代表的是(True positives + False positives),也就是系统一共识别出来多少照片 。
在这一例子中,True positives为3,False positives为1,所以Precision值是 3/(3+1)=0.75。
意味着在识别出的结果中,飞机的图片占75%。
Recall 是被正确识别出来的飞机个数与测试集中所有飞机的个数的比值:
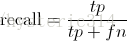
Recall的分母是(True positives + False negatives),这两个值的和,可以理解为一共有多少张飞机的照片。
在这一例子中,True positives为3,False negatives为2,那么Recall值是 3/(3+2)=0.6。
意味着在所有的飞机图片中,60%的飞机被正确的识别成飞机.。
原文链接:https://blog.csdn.net/hysteric314/article/details/54093734