Introduction
This repository includes tensorflow code of MBMD (MobileNet-based tracking by detection algorithm) for VOT2018 Long-Term Challenge. The corresponding arxiv paper has been drafted on Arxiv. Learning regression and verification networks for long-term visual tracking. Yunhua Zhang, Dong Wang, Lijun Wang, Jinqing Qi, Huchuan Lu
Prerequisites
python 2.7 ubuntu 14.04 cuda-8.0 cudnn-6.0.21 Tensorflow-1.3-gpu NVIDIA TITAN X GPU
Pretrained model
The bounding box regression's architecture is MobileNet, and the verifier's architecture is VGGM. The pre-trained model can be downloaded at https://drive.google.com/open?id=1g3aMRi6CWK88FOEYoQjqs61fY6QvGW1Z. Then you should copy the two files to the folder of our code.
Integrate into VOT-2018
The interface for integrating the tracker into the vot evaluation tool kit is implemented in the module python_long_MBMD.py. The script tracker_MBMD.m is needed to be copied to vot-tookit.
CPU manner
If you want to run this code on CPU, you need to just set os.environ ["CUDA_VISIBLE_DEVICES"]="" in the begin of python_long_MBMD.py
MobileNet based tracking by detection algorithm(MBMD)

大家好,在今年德国慕尼黑召开的ECCV Visual Object Tracking Workshop上,我们的算法有幸在SiameseRPN的巨大压力下,获得了Long-term Challenge的冠军。代码已开源在xiaobai1217/MBMD,训练和测试代码未来将在VOT2018官方网站上发布。
Visual-Object-Tracking Challenge (VOT) 是当前国际上在线目标跟踪领域最权威的测评平台,由伯明翰大学、卢布尔雅那大学、布拉格捷克技术大学、奥地利科技学院联合创办,旨在评测在复杂场景下单目标跟踪的算法性能。今年的VOT2018比赛中引入了Long-term Challenge:每个视频在2000帧至2万帧左右,被跟踪目标频繁离开视野,然后再次出现。因此,要求跟踪算法必须具有判断目标是否在当前帧出现和全图搜索目标的能力。Long-term比赛有两个任务,分别是长时跟踪(Long-term Tracking)和全图检测(Re-detection Experiment)。
方案简介:
Motivation: 匹配网络通过预训练能够适应在线跟踪时目标外观的变化,但是对干扰物区分度不够;分类网络能够很好地区分出干扰物,却很难适应目标外观的变化。如果用单一网络(匹配或分类),很难通过网络输出判断目标是否出现在当前帧,并执行全图搜索。如下图:
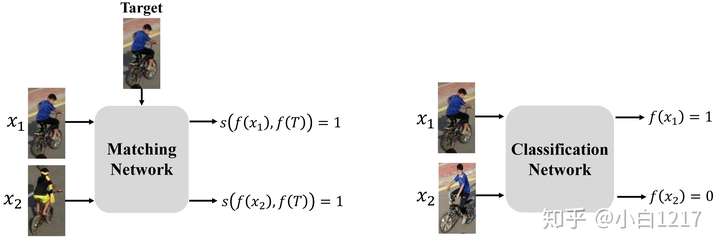
Algorithm: 如下图所示,我们的算法由两部分组成,一个基于匹配的回归网络和一个基于分类的验证网络。
 算法框架
算法框架
-
回归网络有两个输入,分别是局部搜索区域和目标图像块。局部搜索区域以上一帧目标位置为中心,四倍目标大小在当前帧裁得。在每一帧,回归网络在搜索区域内提出一些和目标相似的候选框,每个候选框都有一个描述相似度的分值。验证网络在线学习一个分类器,它首先检验和目标最像的候选框是否是目标,若是,则此目标框为当前帧跟踪结果。如果最像的候选框被验证网络分为背景,则验证网络将从候选框中选择一个分类为前景的作为当前帧跟踪结果。如果两个网络均找不到一个候选框既与目标相似又被分类为前景,那么Tracker将开启全图搜索模式,即从图片左上角开始,裁出一个局部搜索区域,依次搜索全图,横向步长为目标长的一半,纵向步长为目标宽的一半。
-
匹配网络通过离线训练而具备在一个区域内定位相似物体的能力。它采用SSD检测框架和MobileNets结构作为特征提取部分,使用了ILSVRC2014 Object Localization Dataset 和ILSVRC2015 Video Object Detection Dataset两个数据集。预训练时不使用任何类别标签信息。上支路输入为局部搜索区域,输出两种尺寸的特征图(1919和1010)。我们采用两种尺度来处理目标大小剧烈变化。下支路输入目标图像块(第一帧给定的待追踪目标),输出一个特征向量。两路的特征图经过融合得到的特征图输入到后面的候选区域生成网络(Region Proposal Network,RPN),并由RPN模块输出编码了候选框信息的特征图,随后送入到非极大值抑制模块(Non-Maximum-Suppression)得到最终候选框。融合过程如下图所示(以19*19尺寸为例):
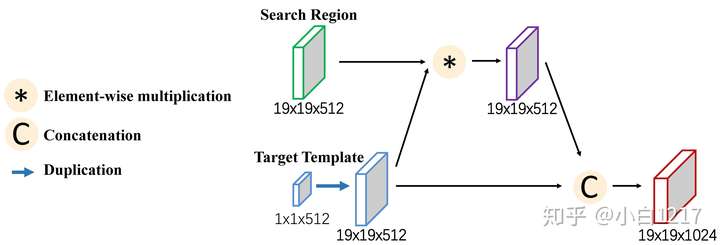
-
验证网络和MDNet的结构相似(VGGM结构),输入一个107*107的图片块,输出一个二维向量,分别是前景和背景的概率。我们加载VGGM在ImageNet Classification任务中预训练的参数,而不额外在Video数据集上训练。为了有效地滤掉干扰物,在线跟踪过程中,我们更新网络后三层来训练一个强分类器。
Performance: 在VOT2018 长时跟踪任务中,我们的F-score为0.61,AUC为0.81。
欢迎大家交流和cite:
@inproceedings{LRVNT,
title={Learning regression and verification networks for long-term visual tracking},
author={Yunhua Zhang, Dong Wang, Lijun Wang, Jinqing Qi, Huchuan Lu},
booktitle={arXiv preprint arXiv:1809.04320},
year={2018}
}
用siamRPN的proposal来做reid
SiamRPN+MDNet,proposal+verification的想法没优化的Code在2fps左右;image-wide detection部分很耗时间,未来要考虑重点加速。这个算法的核心思想是一个快速的较为精确的proposal机制(和SiamRPN结构类似,但train的没哪个好)和一个外观刻画能力强但确只需要处理少量样本的验证机制(所以就看上MDNet了,其实上看上VGG-M了,我们实验发现不用Video Training的VGG-M很牛)。
-
验证网络特征用cnn,分类有没有尝试过简单的线性之类的?
-
记得其他学生尝试过,可以使用VGG-M后面加逻辑回归或SVM之类的,效果会略差些。主要是VGG-M的特征会比较好,其实VGG-16更好(但是考虑到精度和速度平衡目前感觉现场网络中VGG-M是个不错的选择,目前基于VGG-M的代码优化好,是可能达到实时的)。
-
我想问一下为什么会考虑把correlation之后的结果和broadcast之后的template concat在一起呢?原版siamRPN应该是只使用了前者对吧,你们这样做的考虑和实际效果是怎样的呢?在paper里没有看到对应的ablation study。
-
concat主要是想为后面的RPN提供目标的信息,对应的ablation study会在第二版论文中补充进去
-
我测试了下您github上公开的代码,对于相似物体的跟踪容易出现错跟的情况,就拿vot2016数据集中ball来说,明明需要跟踪小伙踢球的那个球,但后面跟踪到了旁边的球上,出现了错跟的情况,这个有好的解决办法吗?
-
-
你好,我想问一下您在进行RPN之前将模板特征复制到与搜索区域维度相同做点乘然后与模板特征cancat这样做的意义是什么呢?因为SiameseRPN和之前的siamfc都是直接做卷积的,这样做会有什么优势吗?
-